平均值还是中位数?选择基于决策,而不是分布
即使对于倾斜的数据,平均值有时也会导致更好的决策

当我采访数据科学申请人时,我最喜欢的问题之一是,“什么时候使用平均值而不是中位数更好?”
这个问题不仅可以帮助我评估候选人的统计基础,还可以让我了解他们如何解决问题。他们是否强调数据或决策的性质?
大多数候选人会这样回答:
“当数据遵循对称分布时,平均值通常更好。当数据有偏差时,中值会更有用,因为平均值会被异常值扭曲。”
这个答案抓住了我在统计学课程中学到的传统智慧。它侧重于数据的性质,不考虑分析的目标。
决策分析课程教会了我解决这个问题的不同方法。决策分析不是专注于数据的性质,而是让我们专注于我们的目标。
实际上,在许多应用中,平均值是比中位数更有用的度量,即使是倾斜的数据也是如此。
让我们从三个涉及倾斜数据的经典示例开始,在这些示例中,均值或中位数都严重失败。
Example 1: Monetary lotteries
假设您可以选择玩以下机会游戏之一:
Game A:
- 1/3 的机会赢得 $1
- 1/3 的机会赢得 $2
- 1/3 的机会赢得 $3
Game B:
- 1/3 的机会赢得 $1
- 1/3 的机会赢得 $1.90
- 1/3 的机会赢得 $1,000,000
你会选择哪一个?
大多数人会选择玩游戏 B,即使它的中位数较低(1.90 美元对 2.00 美元)。在这种情况下,使用均值更有意义,即使分布是倾斜的。
中位数的论点在这里没有意义:
“我的决定应该基于一个不受我有三分之一的机会通过游戏 B 成为百万富翁这一事实影响的衡量标准。”
1,000,000 美元的 1/3 机会是一个极值,但它是分配的一部分,与决策相关。
示例 2:比尔·盖茨走进一家酒吧
一个常见的笑话是这样的:
“比尔·盖茨走进一家酒吧,里面的每个人平均都变成了百万富翁。”
这个笑话突出了平均值是如何产生误导的。如果没有上下文,人们可能会认为酒吧里满是百万富翁,而它可能由零个百万富翁组成。在这种情况下,中位数给出的结果大多数人会觉得更直观。
这个例子的一个基本特征是它是关于数据通信而不是决策。这个例子是唯一一个不涉及明确决定的例子。
关于数据通信的观点无疑是有效的。研究人员在报告家庭收入时使用中位数是有充分理由的。中位数通常可以更好地了解“典型”值是什么,这有助于提供对数据集的直觉。
给出“典型”值最直观感觉的度量不一定是导致最优决策策略的度量。
示例 3:一家考虑扩张的公司
一家公司正在考虑扩张。扩张将涉及雇用 300 名新员工,因此公司需要估算该计划的总成本。
工资,就像收入一样,往往是向右倾斜的。我们可以预期新工作的平均工资将高于中位数。
公司的一位分析师决定使用中位数,因为工资分布是正确的。他们将中位数乘以 300 来估算雇用新员工的总成本。
事实证明,实际成本远高于他们的估计。为什么?因为他们应该使用平均值。
在这种情况下,公司对总数感兴趣。均值与总数有直接关系(总计 = 均值 x N),但中位数没有。
一般来说,当分析的目的是估计总体总数时,无论分布的形状如何,均值是比中位数更有用的度量。
两家竞争公司的模拟
评估统计方法有效性的最佳方法之一是对合成数据执行蒙特卡罗模拟。
因此,让我们模拟一家基于均值做出决策的公司与一家基于中值做出决策的公司竞争。
我们可以模拟的*相对*简单的业务决策是 A/B 测试。在 A/B 测试中,公司面临发布产品的两个不同版本(变体)的决定——A 和 B。
为简单起见,我们将其模拟为“赢者通吃”测试,这意味着公司选择从测试中看起来更好的变体而不计算统计显着性。这种方法在没有控制组的情况下是合理的,而且业务问题的风险相对较低。
在向整个客户群发布变体 A 或 B 之前,公司用客户样本测试变体 A,用不同的客户样本测试变体 B。
根据变体 A 和 B 在测试中的表现,公司选择向整个客户群发布变体 A 或变体 B。
这是设置的摘要。在每次模拟中:
- 我们将随机生成两个倾斜分布。这些分布代表变体 A 和 B 的每个用户收入的真实分布。
- 为了决定发布哪个变体,两家公司将分析一个数据集,该数据集由来自变体 A 分布的 1,000 个抽取和来自变体 B 分布的 1,000 个抽取组成。这些抽签构成了“测试数据集”。
- 为了隔离决策方法的影响,两家公司都分析了相同的 A/B 测试数据集。
- 每个公司将根据测试数据集选择 A 或 B。
- 选择变体后,每家公司都会“大规模”向其整个客户群推出其首选变体。我们将通过从每家公司选择的分布中生成 100,000 次抽奖来模拟此步骤。这些抽奖代表从每家公司的 100,000 名客户那里获得的收入。
- 业务目标是最大化总收入,因此我们会在每家公司大规模发布其首选变体时,根据每家公司的总收入来评估每家公司的决策政策。
现在让我们进入 Python 实现。完整的实现可在 GitHub 上找到。我鼓励读者尝试一下,以了解不同的决策框架如何导致不同的业务成果。[0]
首先,我们需要编写一个生成随机偏态分布的函数。我选择了对数正态分布,因为它们是偏斜数据的常用模型。
回想一下,如果变量 x 具有对数正态分布,则 log(x) 具有正态分布。我发现根据潜在正态分布的均值 (mu) 和标准差 (sigma) 来表征对数正态分布的参数很直观。
在这个函数中,我们从 0 到 0.5 之间的均匀分布中随机抽取 mu,从 1 到 1.5 之间的均匀分布中抽取 sigma:
此函数生成如下所示的分布:
在每次模拟中,公司将看到其中两种分布,他们需要根据从每个分布中抽取的 1,000 次随机样本来选择一种。
以下是测试数据集的示例:
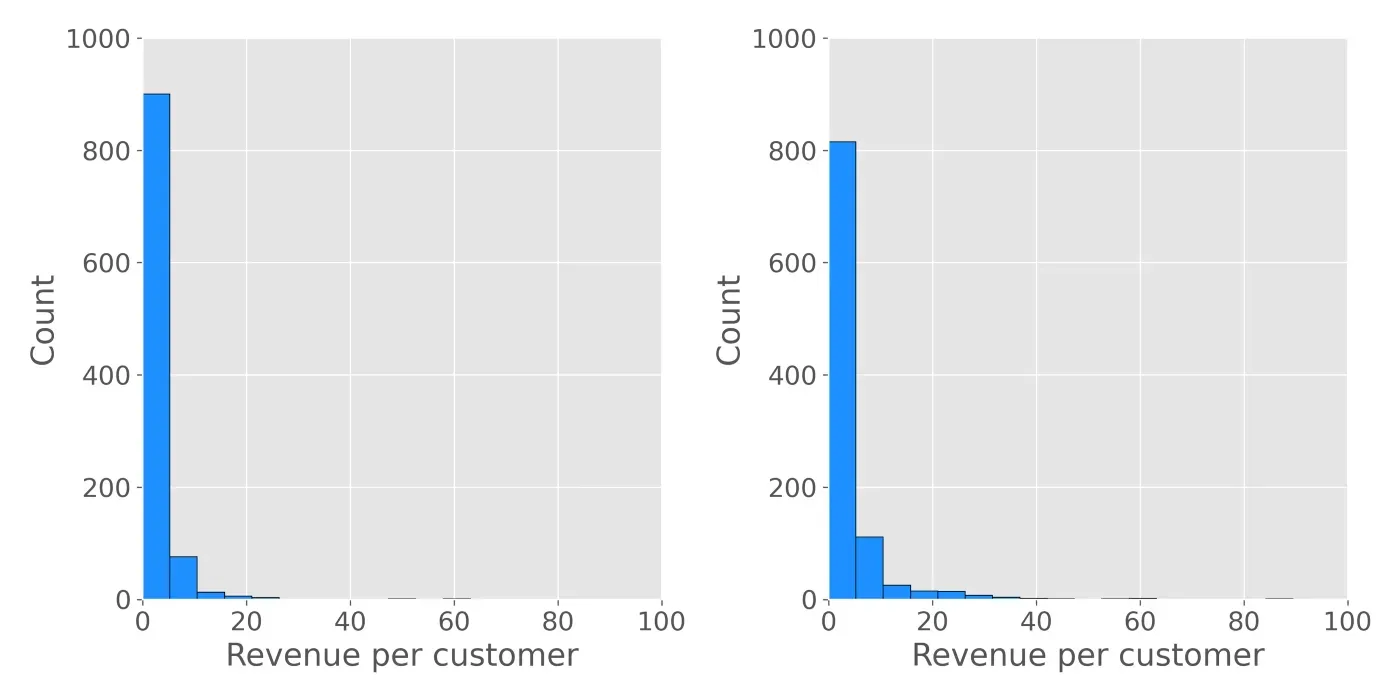
看看这些数据集,两家公司就应该如何做出决定得出了不同的结论:
- 中值 Maxers 注意到分布非常倾斜。事实上,看起来有些数据点可能是异常值。为了减少异常值的影响,他们选择测试数据集具有较高中位数的分布。
- Mean Maxers 意识到基本目标是最大化总收入,因此他们选择测试数据集具有更高均值的分布。
我们可以用以下函数表示两家公司的决策政策:
运行 5,000 次模拟后,两家公司的收入分布如下所示。
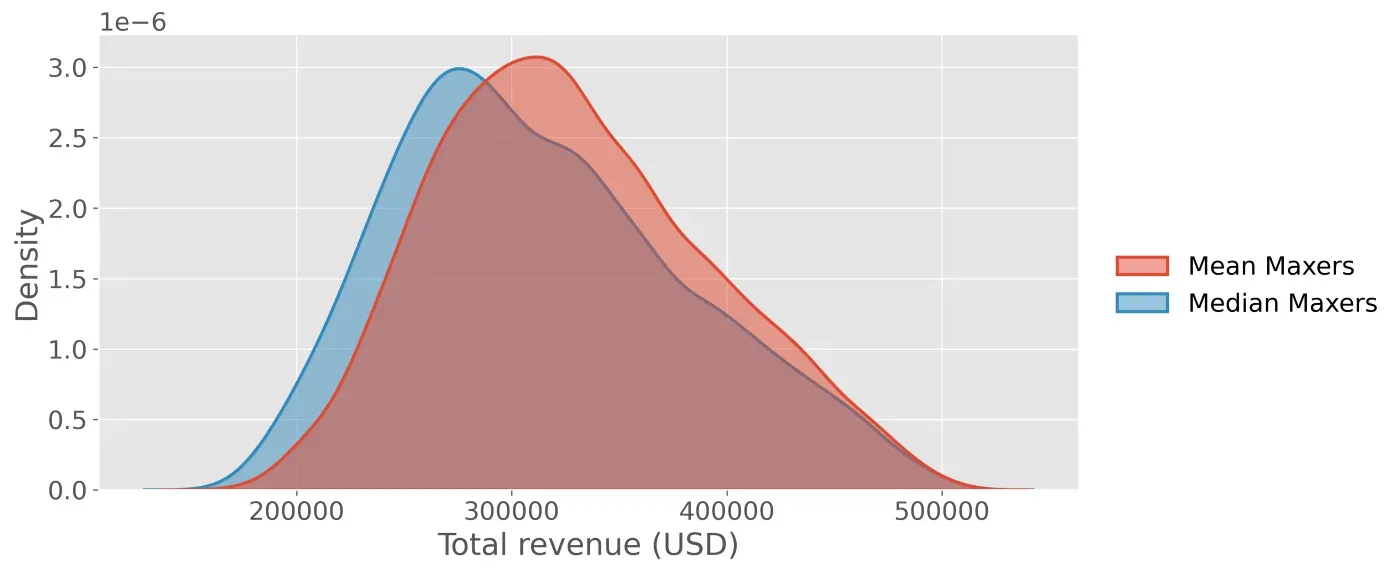
尽管两家公司的总收入在模拟中有所不同,但很明显,Mean Maxers 的收入分配明显更高。
我们还可以看一个条形图来回答这个问题:平均 Maxers 有多少百分比的时间优于 Median Maxers?
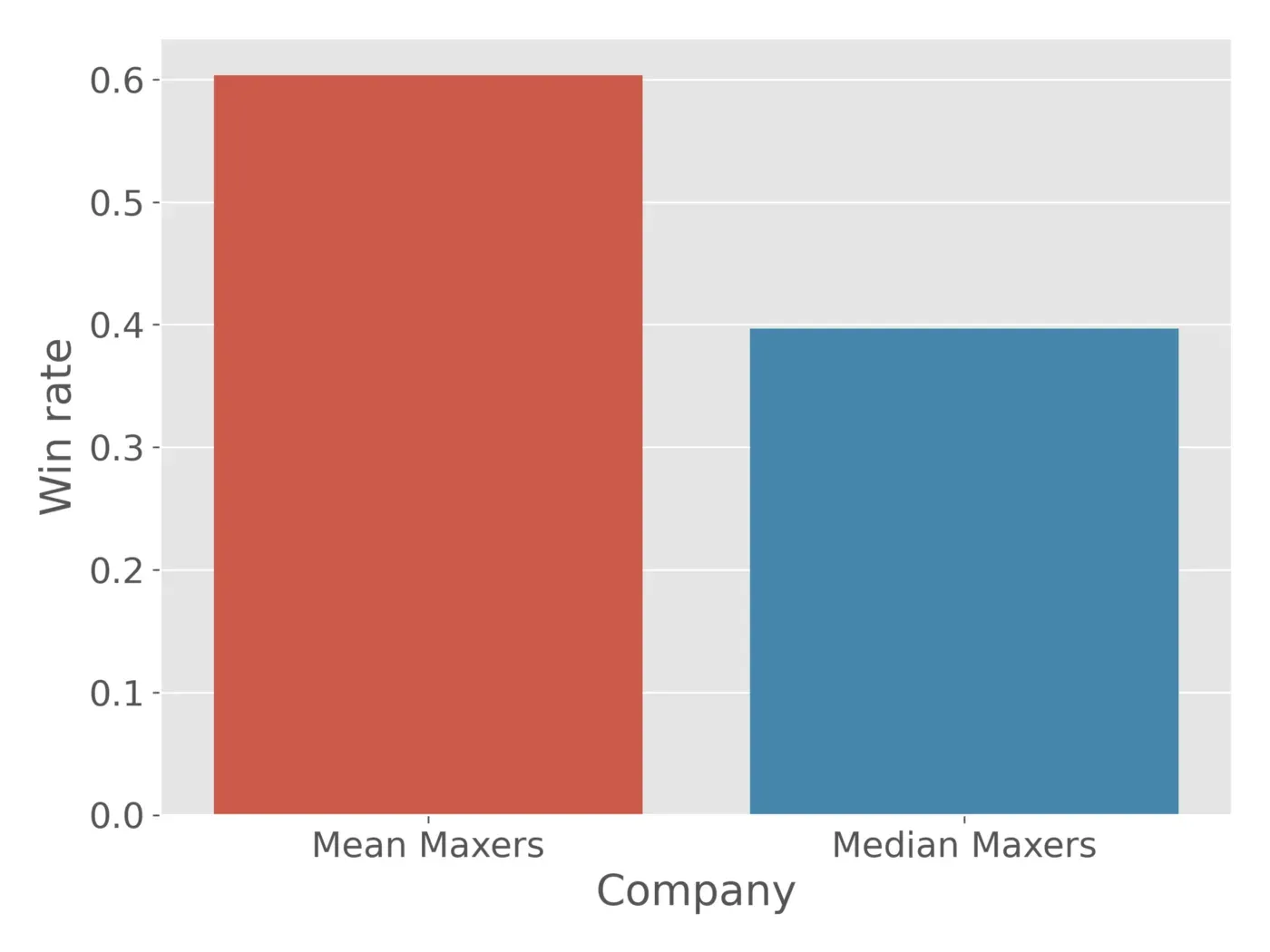
在大约 60% 的模拟中,Mean Maxers 的表现优于 Median Maxers。
这个结果很有趣。直觉上,这两家公司似乎应该经常得出相同的结论,因为具有较高平均值的分布通常应该具有较高的中位数。
根据我们使用的对数正态参数,公司在大约 70% 的模拟中选择了相同的变体。当公司选择相同的变体时,任何一家公司都有 50% 的机会胜过另一家公司。
然而,当这些公司选择不同的变体时,平均 Maxers 在大约 86% 的模拟中优于 Median Maxers。
这些数字取决于我们使用的确切模拟设置,但关键的一点是,这代表了一种相当常见的业务情况,其目标是使总数最大化。有了这个目标,根据中值而不是平均值做出决策会导致战略劣势。
我们什么时候应该使用中位数(或更一般地说,分位数)?
需要明确的是,我并不是说中位数永远没有帮助。有时,中位数与分析目标一致。
在某些应用中,中位数(或分位数)优于均值。这里有几个:
- 数据讲故事。当手头没有明确的决定时,中位数通常更有助于报告偏斜的数据。它可以更直观地了解分布中的“典型”值。然而,为公司工作的数据科学家几乎总是有一个决定。
- 有时,中位数会直接回答问题。如果我们需要知道给定的薪水是否高于部门薪水的一半,我们需要中位数。
- 当我们关心确保一定的服务水平时。例如,当我与消防部门合作时,他们关心的是提供一定的响应时间,而且概率很高。因此,他们经常使用 90% 的响应时间来评估他们的表现。如果他们使用平均响应时间,他们可以用非常短的响应时间来补偿长响应时间,这与公共安全目标不一致。
- 当我们被激励以最小化预测的绝对误差时。正如本文所讨论的,分布的中位数是最小化平均绝对误差的值。[0]
对数转换呢?
处理倾斜数据的常用方法是使用数据转换,例如取对数。这些转换在许多应用中都有帮助;它们可以缓解右偏,强制数据为正,并提高预测模型的性能。
但是,我们还需要小心,不要以无意中改变决策政策的方式使用它们。
您更喜欢以下两个选项中的哪一个:
- 选项 1:一张 10 美元的钞票和一张 1 美元的钞票
- Option 2: Two $5 bills
大多数人会选择选项 1,因为 10 美元 + 1 美元大于 5 美元 + 5 美元。如果在求和之前进行对数转换,您会更喜欢选项 2,因为 $5 x $5 大于 $10 x $1。对数转换改变了决策策略。
这种变化不一定是坏事。在某些情况下,将决策基于产品而不是总和是有意义的。
当我们使统计数据更容易的努力无意中导致我们的利益相关者进入次优策略时,就会出现问题。
在上一节的模拟中,我考虑添加第三家公司 Log Transformers,该公司将在取平均值之前取测试数据集的对数。然后他们会选择在对数尺度上具有更大均值的变体。该策略相当于选择几何均值较高的分布。[0]
中值等于对数正态分布的几何平均值,因此对数变换器的策略与中值 Maxers 几乎相同。他们的策略也将不如 Mean Maxers 的策略。
What about outliers?
当最优决策政策建议我们应该使用平均值而不是中值时,我们需要小心异常值,因为它们会扭曲平均值。
但答案不是用导致次优决策的度量来代替平均值。
相反,我们首先应该理解为什么异常值会出现在数据集中。
它们是测量误差的结果吗?如果是这样,我们应该考虑将它们排除在分析之外。如果异常值是对现实的准确测量,我们需要使用合理的判断。
异常值可能是侥幸的结果。例如,在电子商务网站上,一小部分客户可能是订单异常大的企业。如果您正在运行 A/B 测试,并且测试组包含这样的用户,则可能会以不希望的方式扭曲结果。
根据具体情况,其他方法(例如 Winsorized 均值)可能会有所帮助。这里没有通用的解决方案。最好的建议是专注于分析的目标,开发领域知识以了解异常值的原因,然后从中做出良好的判断。[0]
在处理异常值时,首先要专注于理解它们为什么存在。之后,问问自己它们是否是分发中有意义的部分。
我们应该使用汇总统计吗?
一些人认为汇总统计在某些情况下具有内在的误导性,我们应该关注“整体分布”。
这个概念有一些优点。查看整个分布可以揭示标准汇总统计无法捕捉到的见解。
例如,查看 A/B 测试中的分布可以揭示异质效应——这意味着处理可能对某些用户产生与其他用户不同的影响。
然而,我们的目标通常是将数据转化为决策,这需要以可操作的方式总结分布。
量化决策框架需要用一个数字来总结分布,该数字量化它与决策者偏好的一致性。
没有这个,我们就无法量化一种分布是否比另一种更好。决策分析有助于解决这个问题;它的中心目标之一是在一个单一的数字中捕捉偏好和分布——行动的效用。
所以是的,我们需要汇总统计数据。我们应该解释是什么推动了汇总统计,但我们必须知道如何以捕捉决策者偏好的方式汇总分布。
同样重要的是要注意,还有许多其他方法可以总结分布,例如调和平均数、几何平均数和某些等价物。根据决策的性质,它们在某些情况下都是有用的。
Conclusions
现在我们已经深入探讨了这个问题,我们可以对“什么时候使用平均值而不是中位数更好?”提出一个更深思熟虑的答案。
以下是我将如何回答这个问题:
使用平均值或中位数的选择应主要由分析目标驱动。当基本业务决策取决于总数(例如总收入或总销售额)时,平均值通常是更好的指标,因为与中位数不同,它与总数有直接关系。均值对极值很敏感,因此应注意确保它们是在干净、有意义的数据集上计算的。当分布偏斜时,中位数可以提供更直观的“典型”值感觉,但这并不一定意味着它是最优决策策略的基础。
该主题还强调了数据科学家需要将决策分析中的主题与统计、机器学习和编程一起纳入他们的研究饮食中。
感谢您阅读这篇文章。如果您对更多决策分析和统计内容感兴趣,请在 Medium 上关注我或在 LinkedIn 上联系。[0][1]
Recommended resources:
- Ronald A. Howard 的决策分析基础。本书对决策分析的核心概念进行了出色的概述。这些概念对我作为数据科学家的成长很有帮助。
- Melinda Miller Holt 和 Stephen M. Scariano 从决策的角度看均值、中位数和众数。本文概述了使均值、中位数或众数成为决策最佳度量的数学条件。一些描述的激励结构在实践中并不常见,但本文提供了一个有趣的数学框架来选择汇总统计数据。[0]
- 你能解开这个射箭之谜吗?通过 FiveThirtyEight(YouTube 视频)。这个谜语概述了平均值不是决策的理想衡量标准的情况。有人将这个谜语作为一个例子,说明平均值没有用处,因为分布是倾斜的。相反,我认为这是关于分析的目标。目标是最大化获胜概率,这与最大化预期总分不同。[0]
文章出处登录后可见!