生存分析:简介
初步了解最适合检查事件时间数据的方法

生存分析是一种久经考验且值得信赖的方法,用于从事件发生时间数据中获得洞察力。
不幸的是,尽管我花了很多时间学习生存分析,但在我自己的项目中,我忽略了这项技术,即使它的用途很合适。
这很可能是因为我用来学习该技术的许多资源直接用于解释该方法,而没有花费足够的时间来强调事件发生时间数据的性质。
我希望通过概述生存分析来避免其他人犯同样的错误,同时关注使这种技术不可或缺的事件发生时间数据的特征。
Survival Analysis
生存分析是统计方法的一个分支,专注于分析事件发生时间的变量。该名称源于其最初用于检查疾病和疾病的死亡率。
话虽如此,这种分析的可用性远远超出了医疗保健领域,也存在于制造业和金融等行业。今天的企业利用这种技术来评估各种事件,例如机器故障、客户流失和贷款偿还。
在这种情况下,“幸存”一词描述了研究中没有经历相关事件的受试者。例如,在对机器故障的研究中,“幸存”的机器是仍在运行的机器。
使用这种技术,您可以回答以下问题:
- 受试者在 X 年后存活的概率是多少?
- 不同组的受试者是否表现出不同的存活率?
- 哪些特征会影响受试者的生存能力?
您可能会查看问题列表并认为:此分析没有什么特别之处。人们可以用传统的统计方法回答同样的问题,对吧?
Well, not necessarily.
为什么要使用生存分析?
生存分析的好处在于事件发生时间变量的性质。
由于获取事件时间数据的方式,生成的数据集通常包含审查。
审查是当一项研究未能准确捕捉到受试者的生存时间时发生的一种现象。
总共有三种类型的删失:右删失、左删失和区间删失。
当受试者的真实生存时间大于记录的生存时间时,就会发生右删失。当真实生存时间小于记录的生存时间时,就会发生左删失。当真实生存时间在一定范围内时,就会发生间隔删失。
审查是数据收集程序固有缺陷的产物。视情况而定,审查可能很难(如果不是不可能)预防,这就是它在事件发生时间数据中如此普遍的原因。
审查的风险
由于几个原因,数据集中的审查值得关注。
- 审查数据歪曲结果
由于删失数据不能正确捕捉受试者的生存时间,因此将其包含在内可能会产生误导性值。
例如,假设您正在进行一项检查机器故障的研究。在研究中,您观察了 5 台机器并记录了它们达到故障所需的时间。但是,由于实验设计的限制,即使某些机器仍在运行,您也必须停止观察。最后,您从 5 台机器中获得以下持续时间:
Machine 1: 5 hours (Failed)
Machine 2: 10 hours (Operational)
Machine 3: 12 hours (Failed)
Machine 4: 6 hours (Operational)
Machine 5: 15 hours (Operational)由于 5 台机器中有 3 台没有出现故障并且仍在运行,因此记录的持续时间少于这些机器的实际持续时间。这是右删失的一个例子。
如果您使用基本聚合计算一台机器的平均持续时间,您会得出一个低估了实际平均持续时间的平均持续时间。
同样,如果您利用机器学习并构建回归模型来预测机器将运行多长时间,则该模型的训练时间会不准确,因此会产生不可靠的预测。
由于这些原因,对审查数据执行传统的数据科学技术可能不可行。
2. 审查数据难以检测
不幸的是,与很容易发现的缺失数据不同,审查数据是模糊的,很容易逃避检测。
毕竟,原始数据通常不提供直接标记审查或非审查数据的功能。这条信息通常必须从现有数据中获取。
仅识别数据集中的审查记录是重要的一步。即使要对此类数据进行基本汇总,考虑到审查的存在也可以得出更合理的结论。
我在检查包含事件发生时间变量的时间序列数据时犯了一个错误,而没有意识到一些受试者甚至没有经历过相关事件。
3. 审查数据无法补救
即使用户在他们的数据中识别出被审查的记录,他们也可以通过用错误的方法解决这些问题来破坏他们的努力。
将审查数据视为缺失数据并简单地将其从数据集中删除可能很诱人。
不幸的是,虽然包括未说明的删失数据对研究有害,但删除删失数据也是不可行的。由于受试者通常不会随机审查(例如,未达到故障的机器可能有更长的生存时间),将它们排除在分析之外无疑会产生有偏差的结果。
简而言之,生存分析的作用
生存分析的吸引力在于它处理审查的能力。
虽然它不直接填充缺失的持续时间或省略不相关的持续时间,但它能够解释审查数据。
生存分析通过使用称为生存函数的概率函数对事件时间数据进行建模来实现这一点。
用数学术语来说,生存函数可以用以下公式表示:
用 S(t) 表示的生存函数表示受试者在过去时间 t 中幸存的概率。
通过用模型表示事件发生时间数据,用户可以预测受试者的生存情况或识别影响生存能力的因素。
进行生存分析需要两个关键信息:
- 如果每个主题都发生了事件(审查或未审查)
- 每个受试者的生存时间
Case Study
案例研究最适合展示生存分析如何处理审查数据。
该演示将利用生命线包,这是在 Python 中进行生存分析的首选模块。[0]
它提供了一个内置数据集,记录受试者被捕所需的周数。
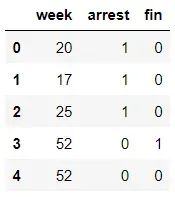
对于每一行,我们可以看到对象已经被观察了多少周,对象是否被逮捕,以及对象是否获得了经济援助。
在这里,“逮捕”功能将记录标记为已审查或未审查。经历过事件(即被捕)的对象被赋值为 1,而没有经历过事件的对象被赋值为 0。
我们可以使用生存分析中流行的工具 Kaplan-Meier 估计器来估计生存函数。
为方便起见,我们可以通过构建生存曲线来可视化该数据的生存函数。
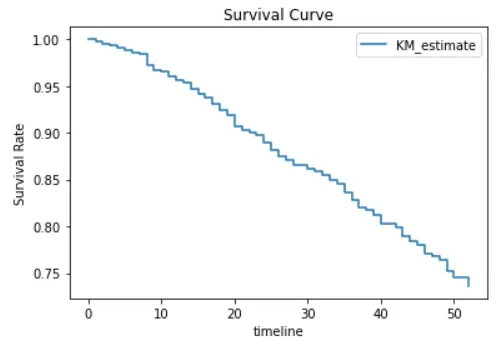
使用生存函数,我们可以很容易地确定受试者在任何给定时间点的估计生存率。
例如,我们可以得出受试者在 30 周后的存活率。
根据结果,86.11% 的受试者在 30 周后不会被捕。
此外,我们可以确定向受试者提供经济援助是否会影响他们的生存机会。
我们可以首先通过绘制每组的生存曲线来可视化两组之间的生存率对比。
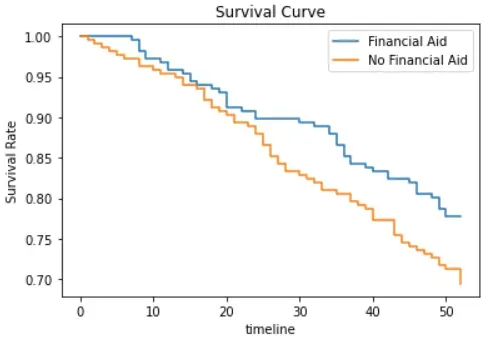
仅从可视化来看,似乎有经济援助的人比没有经济援助的人更有可能不被捕。但是,尚不清楚这种差异是否具有统计学意义。
这种观察可以通过假设检验来验证。我们可以使用对数秩检验,一种比较两组生存分布的假设检验。
让我们进行测试并查看结果。
鉴于 p 值高于 0.05,我们没有足够的证据证明经济援助会影响受试者的生存能力。
Conclusion

希望除了简要解释生存分析背后的“如何”之外,我还解释了“为什么”。
我知道很多人都渴望直接深入研究生存分析的来龙去脉(就像我一样),但我相信了解通常包含审查记录的事件时间数据的性质同样重要。
生存分析能够处理审查,这就是它如此实用的原因。但是,未能识别数据中的审查记录可能会导致您坚持使用其他统计方法来获得洞察力。
只有当您识别出事件发生时间数据的潜在缺点时,您才能认识到生存分析的必要性并利用其各种建模方法。
祝您在数据科学工作中好运!
文章出处登录后可见!