OpenCV 计算机视觉——Python语言实现
1.不同颜色模型
在计算机视觉应用于图像时,通常使用的三种类型的颜色模型:灰度、BGR、HSV
- 灰度模型:将颜色信息转换为灰度或亮度来减少颜色信息的一种模型。在只需要亮度信息就足够的问题(如人脸检测),每个像素都是一个8位值表示,范围从0~255
- BGR模型,opencv默认从文件加载或摄像头抓取的数据模型,由三通道构成
- HSV模型:色调hue时颜色的基调,饱和度(saturation)是颜色的强度,值(value)表示颜色的亮度
2.HPF和LPF
HPF:High-Pass Filter,高通滤波器,可以检查图像的每一个区域,并根据周围图像的强度差异增强某些像素强度
LPF:Low-Pass Filter,低通滤波器,去噪和模糊,平滑像素
2.1定义HPF卷积核
在边缘检测中,通常值得总和为0
kernel_3x3 = np.array([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
kernel_5x5 = np.array([[-1, -1, -1, -1, -1],
[-1, 1, 2, 1, -1],
[-1, 2, 4, 2, -1],
[-1, 1, 2, 1, -1],
[-1, -1, -1, -1, -1]])
2.2 应用卷积核
#scipy中得convol函数支持多维数组
k3 = ndimage.convolve(img, kernel_3x3)
k5 = ndimage.convolve(img, kernel_5x5)
blurred = cv2.GaussianBlur(img, (17,17), 0)
g_hpf = img - blurred
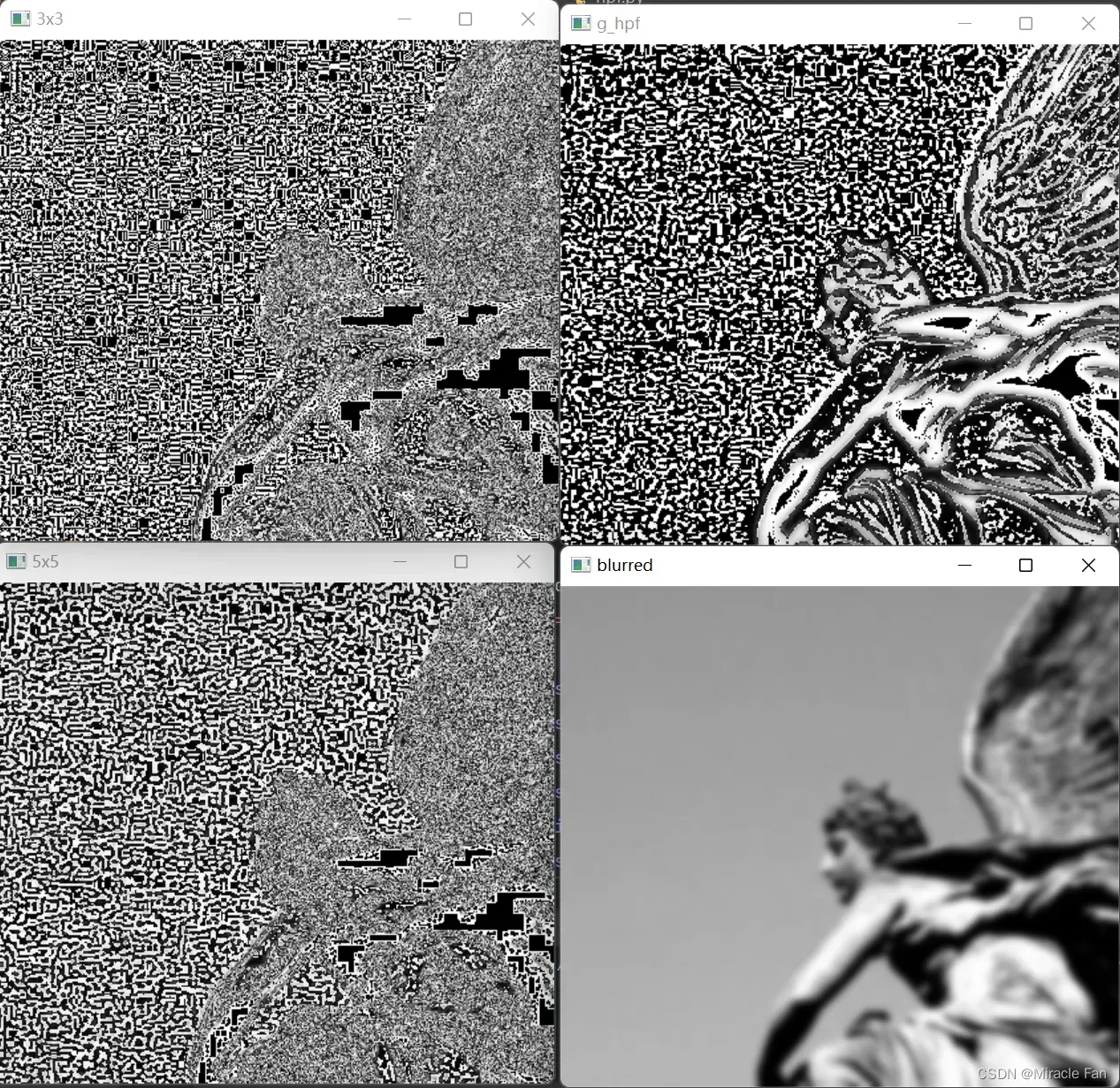
2.3 基于Canny的边缘检测
cv2.imwrite("canny.jpg", cv2.Canny(img, 200, 300))
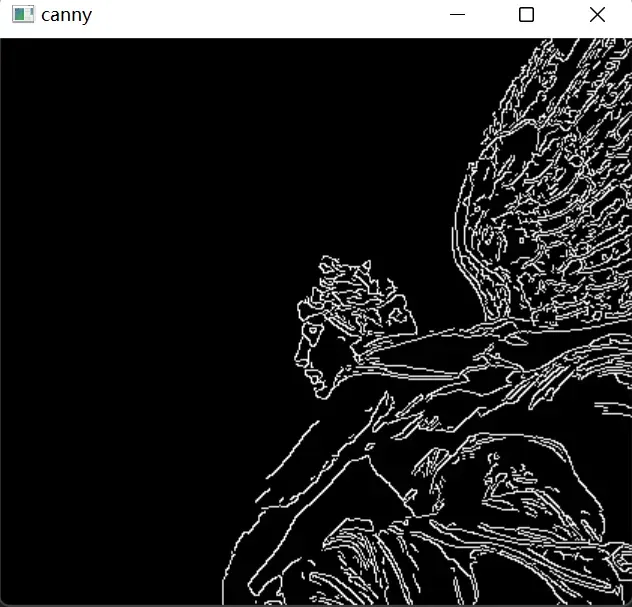
2.3.1 算法过程
- 应用高斯滤波器平滑图像以去除噪声
- 计算图像梯度
- 在边缘上应用非极大值抑制(Non-Maximum Suppression,NMS).算法从一组重叠得边缘选出最好得边缘
- 将双阈值应用于所有检测到得边缘,淘汰所有得假正例结果
- 分析所有的边缘及其连接,保留真正的边缘
3.人脸识别
三种不同人脸识别算法
-
执行主成分分析,识别某一组管擦数据的主成分,计算当前的观测值下国内对于数据集的散度,并产生一个值。该值越小,人脸数据库于检测到的人脸之间的差异值越小
model = cv2.face.EigenFaceRecognizer_create() model.train(training_images, training_labels)通过
cv2.face.EigenFaceRecognizer_create()创建特征脸人脸识别器,通过传递图像数组和标签训练识别器,我们还可以将两个参数传递给该函数num_components:这是PCA需要保留的主成分量数threshold:这是一个浮点值,指定置信度阈值。丢弃置信度低于阈值的人脸
-
也是从主成分分析(PCA)衍生出来的
model = cv2.face.FisherFaceRecognizer_create() model.train(training_images, training_labels) -
将检测到的人脸分成小单元格,并为每个单元格建立一个直方图,描述在给定方向的领域像素时图像的亮度是否在增加。这个单元格的直方图可以与模型中相应的单元格进行比较产生相似度向量。
在人脸检测中,LBPH的实现是唯一运行模型样本人脸和检测到的人脸具有不同形状、不同大小的人脸识别器
model = cv2.face.LBPHFaceRecognizer_create() model.train(training_images, training_labels)可选参数:
Parameter Description radius 用于计算单元格直方图的领域的像素距离 neighbors 用于计算单元格直方图的领域数 grid_X 水平分割人脸的单元格数量 grid_y 垂直分割人脸的单元格数量 confidence 置信度阈值,默认为最高浮点值
4.图像描述符检索和搜索图像
4.1特征检测和匹配的类型
角点:通常意义来说就是极值点,对于图像而言,就是轮廓线的连接点
斑点:是指二维图像中和周围颜色有颜色差异和灰度差异的区域
特征检测:
- Harris:适用于角点检测
- SIFT:适用于斑点检测
- SURF:适用于斑点检测
- FAST:适用于角点检测
- BRIEF:适用于斑点检测
- ORB(尺度不变特征变换):Oriented FAST and Rotated BRIEF,对于角点和斑点的组合检测很有用
4.2 检测Harris角点
因为边缘点与图像颜色通道没有关系,所以将其转换为gray图像
import cv2
img = cv2.imread('../images/chess_board.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = cv2.cornerHarris(gray, 2, 23, 0.04)
img[dst > 0.01 * dst.max()] = [0, 0, 255]
cv2.imshow('corners', img)
cv2.waitKey()

对于该函数dst = cv2.cornerHarris(gray, 2, 23, 0.04),其最重要的是第三个参数,定义了Sobel算子的孔径和核大小。其返回值为浮点格式的图像,该图像每个值表示源图像对应像素的一个分值。中等和高得分表明像素很有可能是角点。然后通过img[dst > 0.01 * dst.max()] = [0, 0, 255]将像素分值大于最高分值1%得像素点涂成红色。而第二个参数代表得是块大小,也即是检测角点区块大小
Sobel算子:通过测量邻域像素之间的水平和垂直差异来检测边缘,并使用核完成这个过程。这些参数定义了角点检测灵敏度。参数值必须在3~31之间的奇数值。低值代表高灵敏度,所有方格边界都会被检测

4.3 检测DoG特征并提取SIFT描述符
SIFT:尺度不变特征变换,Scale-Invariant Feature Transform,该函数在检测特征变换时,不会因图像尺度得不同而输出不同的结果,该变换不检测观察点,而是通过特征向量来描述周围区域。而不检测观察点则需要使用==DoG(Difference of Gaussian)==实现。
import cv2
img = cv2.imread('../images/varese.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()#该对象使用DoG检测关键点,再计算每个关键点周围区域的特征向量
keypoints, descriptors = sift.detectAndCompute(gray, None)#特征检测和描述符计算
cv2.drawKeypoints(img, keypoints, img, (51, 163, 236),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('sift_keypoints', img)
cv2.waitKey()

4.4 基于FAST特征和BRIEF特征的ORB描述符
4.4.1 FAST
定义:加速分割测试的特征(Feature from Accelerated Segment Test).FAST算法将邻域(16个像素的圆形邻域)内每个像素标记为比特定阈值更亮或更暗,该阈值相对于圆心而言。如果包含若干系列连续像素,这个邻域就被视为角点。(plus:有时只检测2个或4个像素点确定邻域是不是角点)
4.4.2 BRIEF
二值鲁棒独立基本特征(Binary Robust Independeent Elementary Feature)并非一种特征检测算法,而是一个描述符,类比于SIFT描述符,其是通过DoG特征检测然后使用SIFT进行特征描述。关键点描述符是图像的一种表示,用来作为特征匹配的通道,也即是用描述符表征图像的特性。
4.4.3 蛮力匹配
蛮力匹配器是一个描述符匹配器,它用来比较两组关键点描述符并生成匹配列表。对于两个图片之间的关键点描述符进行比较,计算距离值,并基于最小距离选择最佳匹配。
import cv2
from matplotlib import pyplot as plt
# Load the images.
img0 = cv2.imread('../images/nasa_logo.png',
cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('../images/kennedy_space_center.jpg',
cv2.IMREAD_GRAYSCALE)
# 计算ORB特征描述符
orb = cv2.ORB_create()
kp0, des0 = orb.detectAndCompute(img0, None)
kp1, des1 = orb.detectAndCompute(img1, None)
# 蛮力匹配
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)#使用汉明距离作为描述符之间的差异
matches = bf.match(des0, des1)
#根据差异值将匹配方案排序
matches = sorted(matches, key=lambda x:x.distance)
# 绘制相似度高的前25条匹配线
img_matches = cv2.drawMatches(
img0, kp0, img1, kp1, matches[:25], img1,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 可视化匹配
plt.imshow(img_matches)
plt.show()

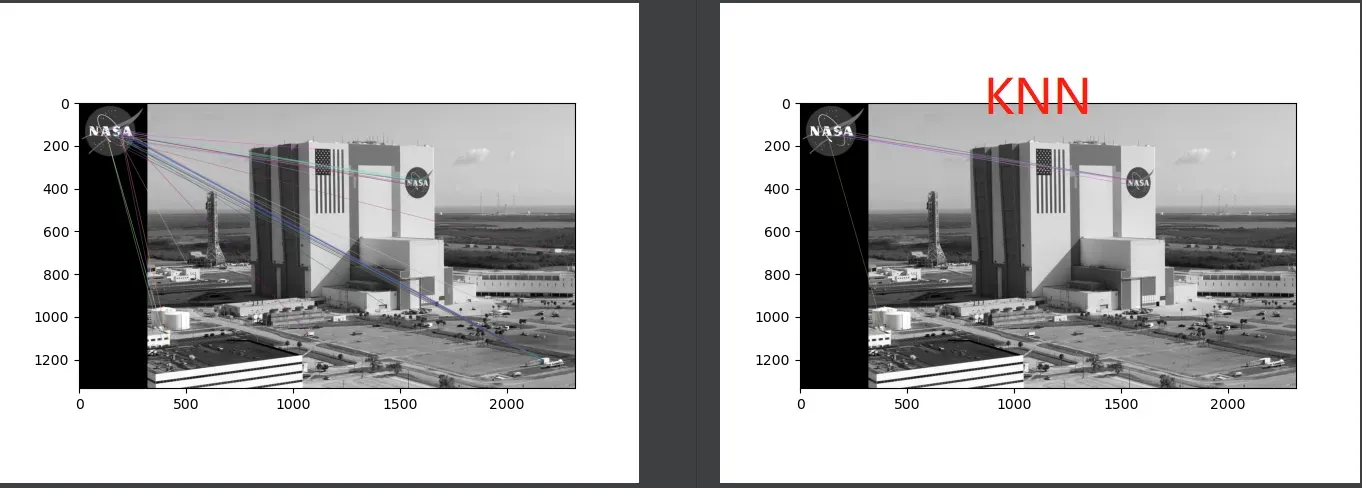
4.5 使用KNN和比率检测过滤匹配
对于蛮力匹配器,其计算每个可能匹配的距离分值,提供了对大量糟糕匹配的距离分值的观察。而与无数糟糕的匹配相比,良好的匹配的距离分值更低,方便我们针对该匹配选择一个阈值。
使用KNN-K最近邻算法能自适应的选择距离阈值,接受一个参数k,指定为每个查询关键点保留的最佳距离匹配的最大数量。
#进行KNN匹配
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=False)
pairs_of_matches = bf.knnMatch(des0, des1, k=2)
比率检验(ratio test)为每个查询关键点请求两个最佳匹配列表,基于最优匹配点,我们选取次优匹配的距离分值乘上一个小于1的值就得到了阈值,当距离小于阈值,才将最优匹配视为良好匹配
# 应用比率检验
matches = [x[0] for x in pairs_of_matches
if len(x) > 1 and x[0].distance < 0.8 * x[1].distance]
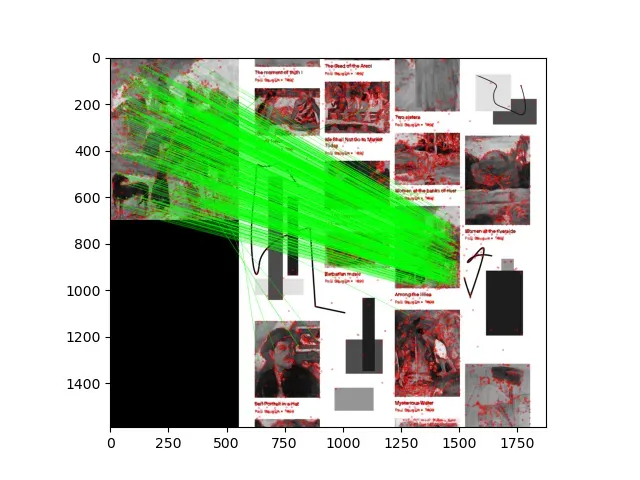
4.6基于FLANN的匹配
FLANN代表快速近似最近邻库(Fast Library for Approximate Nearest Neighbor),一个在高维空间执行快速近似最近邻搜索的一个库。
FLANN匹配器接受两个参数,indexParams对象和searchParams对象,这些参数通过字典形式进行传递,确定FLANN内部用于计算匹配的索引和搜索对象的行为,提供了精度和处理速度之间的合理平衡。
对于indexParams参数,选择使用5棵树的核密度函数(kd-tree)索引算法,官方文档建议在1~16之间,1棵树不提供并行性,而对于searchParams执行50次检查和遍历
# 检验关键点并提取SIFT特征描述符
sift = cv2.xfeatures2d.SIFT_create()
kp0, des0 = sift.detectAndCompute(img0, None)
kp1, des1 = sift.detectAndCompute(img1, None)
# 定义FLANN匹配参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
#使用FLANN匹配
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des0, des1, k=2)
# 只绘制掩膜中标记好的匹配
mask_matches = [[0, 0] for i in range(len(matches))]
#应用劳氏比率检验,也即是乘数为0.7.
for i, (m, n) in enumerate(matches):
if m.distance < 0.7 * n.distance:
mask_matches[i]=[1, 0]
# 绘制通过检验的匹配
img_matches = cv2.drawMatchesKnn(
img0, kp0, img1, kp1, matches, None,
matchColor=(0, 255, 0), singlePointColor=(255, 0, 0),
matchesMask=mask_matches, flags=0)
#可视化匹配
plt.imshow(img_matches)
plt.show()
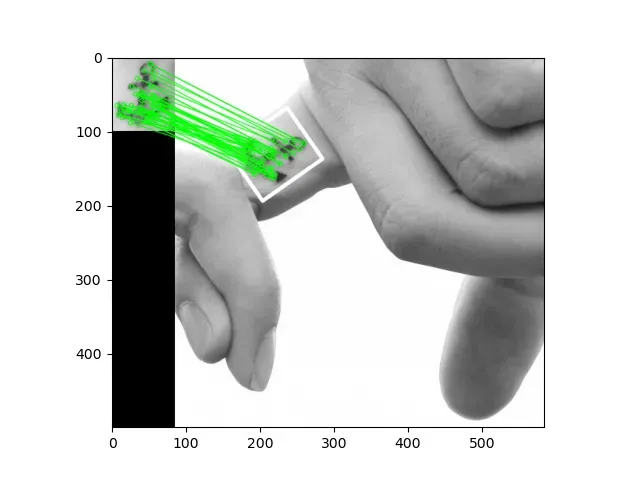
4.7基于FLANN进行单应性匹配
单应性:homography,单应性被定义为从一个平面到另一个平面的投影映射
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
if len(good_matches) >= MIN_NUM_GOOD_MATCHES:
src_pts = np.float32(
[kp0[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32(
[kp1[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
mask_matches = mask.ravel().tolist()
h, w = img0.shape
src_corners = np.float32(
[[0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1, 1, 2)
dst_corners = cv2.perspectiveTransform(src_corners, M)#进行透视转换,将查询图像的矩形角点,并将其投影到场景中
dst_corners = dst_corners.astype(np.int32)
5.建立自定义物体检测器
5.1HOG描述符
定义:Histograms of Gradients将图像划分成若干个单元,并针对每个单元计算一组梯度。每个梯度描述了在给定方向上像素密度的变化,这些梯度共同构成了直方图表示。
5.2 NMS非极大值抑制
实现步骤:
- 构建图像金字塔
- 对于物体检测,用滑动窗口扫描金字塔每一层,对于每个产生正检测结果的窗口(超过某个任意置信度阈值),将窗口转换为原始图像尺度
- 将正检测结果列表按置信度排序
- 对于正检测结果的每个窗口W,移除与W明显重叠的后续窗口
5.3 基于HOG描述符检测人
hog.detectMultiScale()方法接受如下几个参数:
-
winStride:定义滑动窗口在连续检测尝试之间移动的x和y距离
-
scale:该尺度因子应用于图像金字塔的连续层之间,尺度因子越小,检测次数越多
-
finalThreshold:决定检测标准的严格程度。
其返回两个列表:
- 检测到的物体的矩形框列表
- 检测到的物体的权重或者置信度列表
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
img = cv2.imread('../images/haying.jpg')
found_rects, found_weights = hog.detectMultiScale(
img, winStride=(4, 4), scale=1.02, finalThreshold=1.9)
6.物体跟踪
6.1 基本背景差分器
-
使用摄像头捕捉帧
-
丢弃前9帧,这样摄像头才有时间适当调整曝光,以适应场景中的光照条件
-
取第十帧,对其模糊,并将模糊图像作为背景的参考图像
for i in range(10): success, frame = cap.read() if not success: exit(1) gray_background = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) gray_background = cv2.GaussianBlur(gray_background, (BLUR_RADIUS, BLUR_RADIUS), 0) -
对于每个后续图像,重复模糊,灰度,计算模糊帧与参考图像之间的决定差值。对差值进行阈值化、平滑和轮廓检测
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) gray_frame = cv2.GaussianBlur(gray_frame, (BLUR_RADIUS, BLUR_RADIUS), 0) diff = cv2.absdiff(gray_background, gray_frame) _, thresh = cv2.threshold(diff, 40, 255, cv2.THRESH_BINARY) cv2.erode(thresh, erode_kernel, thresh, iterations=2)#侵蚀 cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)#膨胀 contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)#阈值化处理
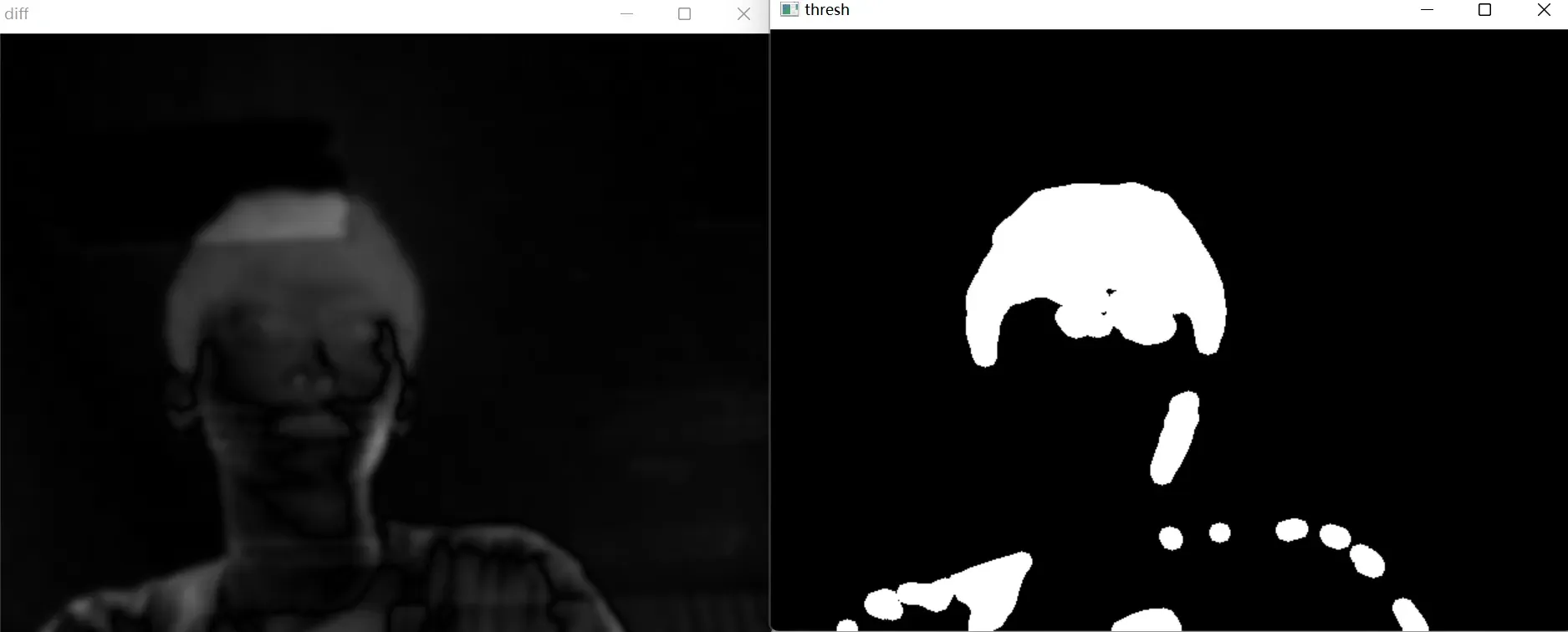
6.2MOG背景差分器
对于基本背景分类器,它的脚本不能动态更新背景图像,鲁棒性很低,因此我们使用混合高斯算法(Mixture of Gaussian)进行背景擦划分。实现方法类似于基本背景分类器,只需要先将创建实例bg_subtractor = cv2.createBackgroundSubtractorMOG2(detectShadows=True),true代表检测阴影,修改形态学核大小,再在读取视频帧数时,使用其获得前景/背景/阴影的掩膜

6.3 KNN背景差分器
只需将创建实例的代码换为bg_subtractor = cv2.createBackgroundSubtractorKNN(detectShadows=True)

其他类似的背景差分器如下:
- CNT
- GMG
- GSOC
- LSBP
可以在cv2.bgsegm模块中进行使用,但它们不支持检测阴影。
6.4 利用MeanShift和CamShift跟踪彩色物体
MeanShift:对于视频的每一帧,进行迭代跟踪,根据当前跟踪矩形中的概率值计算一个质心,将矩形的中心移动到质心上,根据新矩阵中的值重新计算质心,再次移动矩阵,直至收敛。
CamShift:类似于MeanShift的接口,但其会返回有特定旋转角度的矩形,该旋转角度跟踪物体的旋转
文章出处登录后可见!