来源于:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
此时我们使用:“Diabetes Datasets.csv”来做一个分类任务,
“Diabetes Datasets”的数据样式如下所示:其中CSV文件的某一行为一个Sample,某一列为Feature(习惯这么叫)
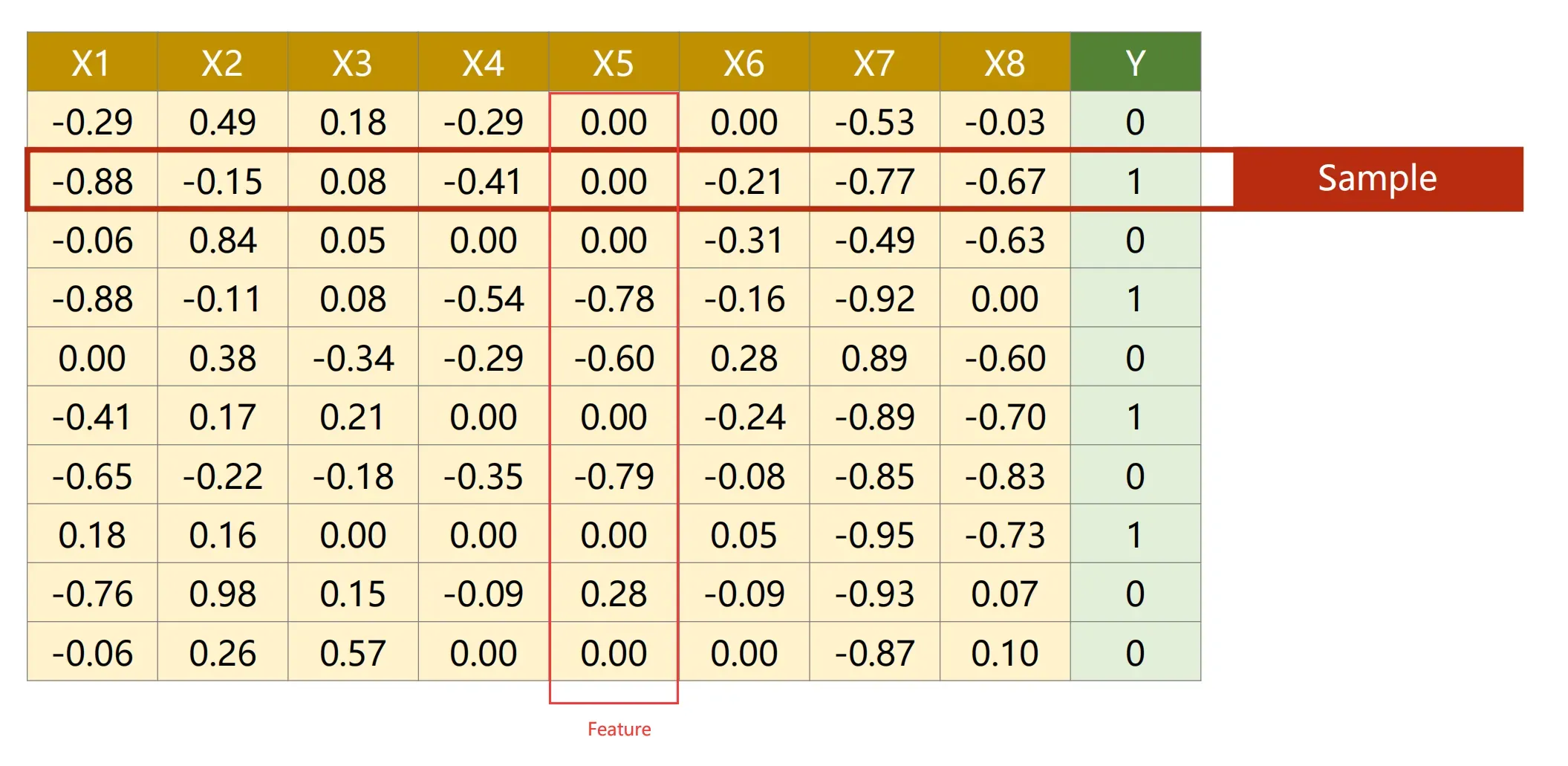
由于是多维的特征输入而不是一维的特征输入,
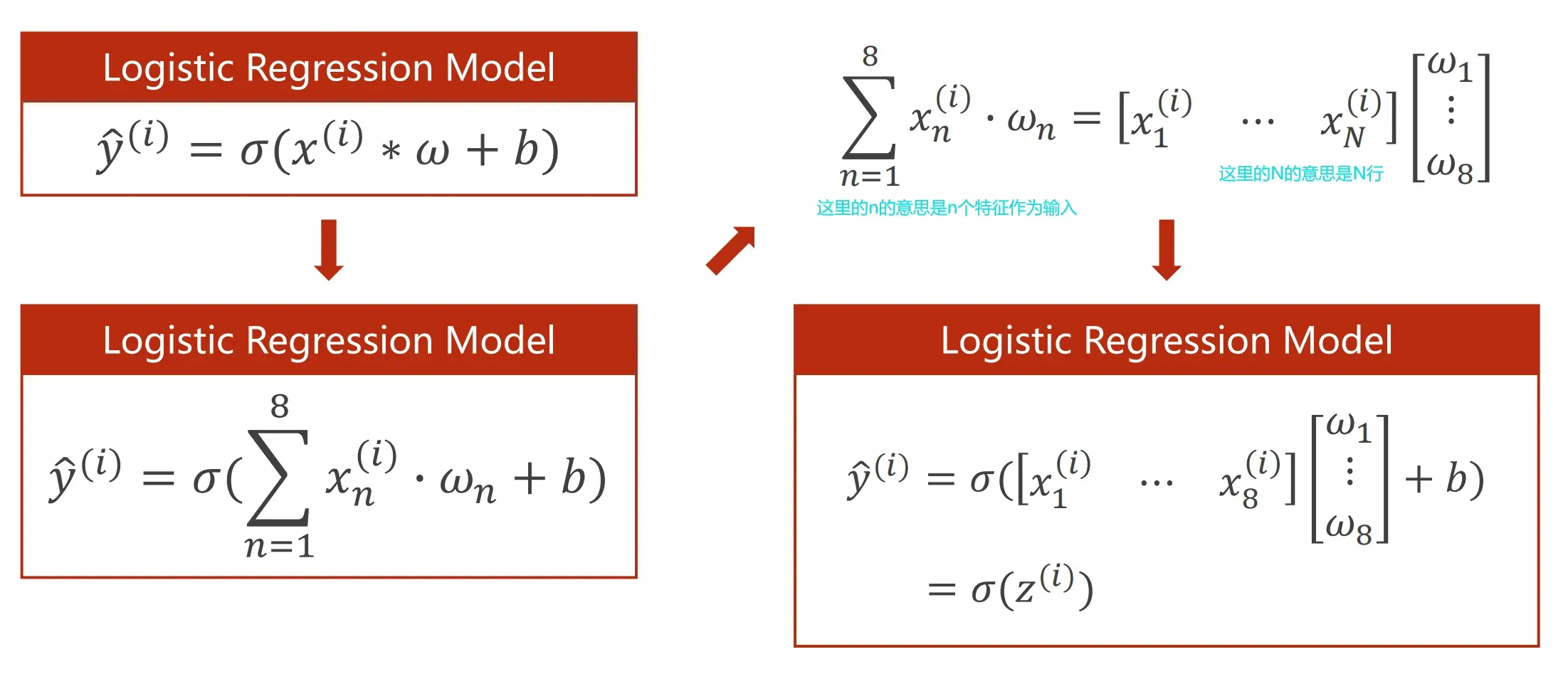
多维数据的输入可以看成矩阵进行运算,这里我们使用单Linear层做拟合,这样它只是一个线性层进行拟合数据,很有可能会导致拟合不准确,所以下面我们使用多个线性层叠加,然后通过引入sigmode函数来做非线性变换,增加模型的拟合程度
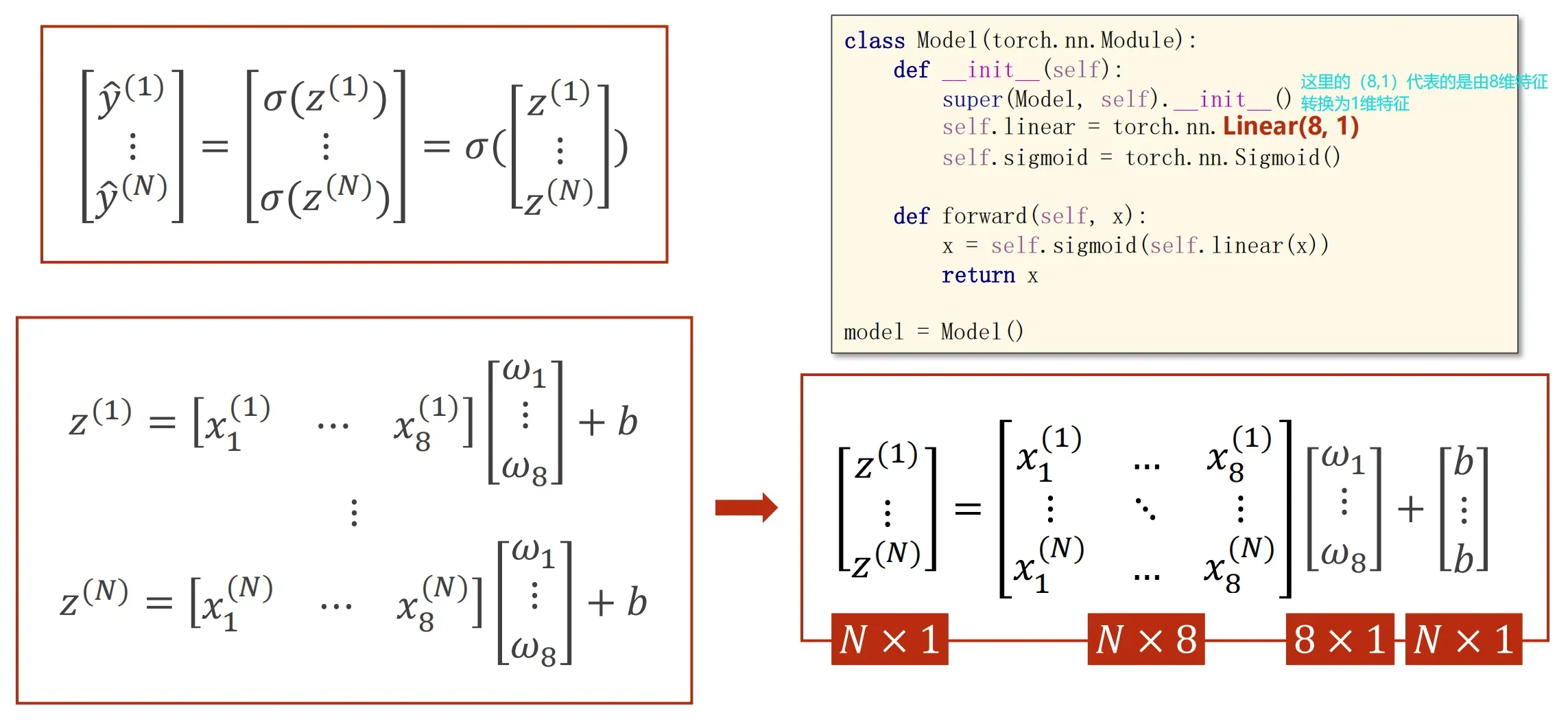
多线性层+非线性变换:
这里有一个问题就是:既然网络的层数越多,拟合就越好,那么我们为什么不一直增加层数从而让网络变得很好呢?
1、会导致模型很大,需要太多的计算资源
2、会让模型过拟合,从而泛化性很差
所以我们建议使用“超参数搜索”来解决这个问题
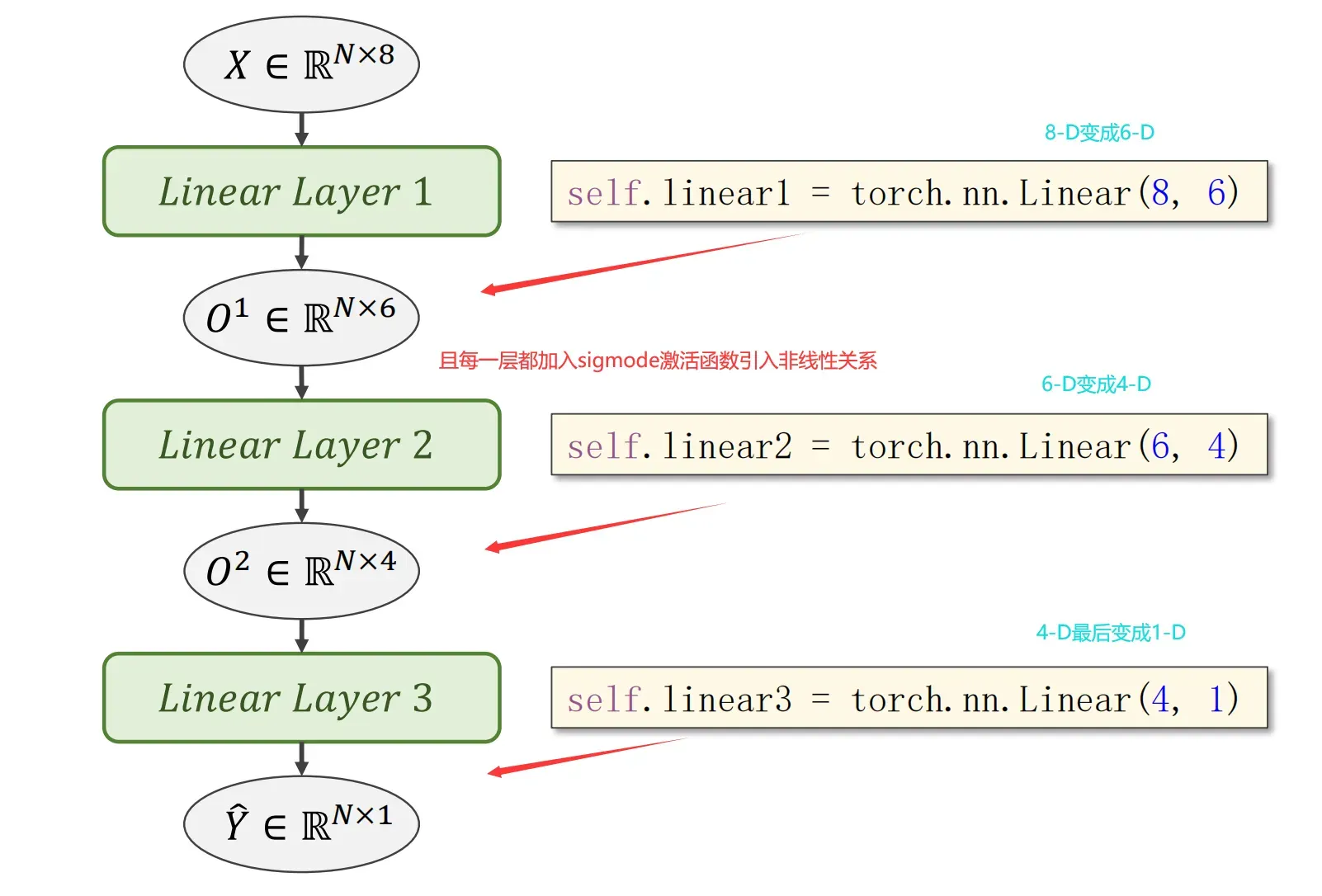
The overall code:
import numpy as np
import torch
import torch.nn as nn
# 1.Load datasets
# 使用float32而不是double的原因是因为32的精度已经够用了,第二是因为一般专业显卡才支持double,平时的家用显卡不支持
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 所有行,第一列到最后一列(不包含最后一列)
y_data = torch.from_numpy(xy[:, [-1]]) # 所有行,只要最后一列,加” [] “的原因是让这一列变成一个矩阵,而不是标量
# 2.Define Model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(8, 6)
self.linear2 = nn.Linear(6, 4)
self.linear3 = nn.Linear(4, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# 3.Construct Loss and Optimizer
# Mini-Batch Loss Function for Binary Classification
criterion = nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 4.Training Cycle
for epoch in range(100):
# Forward
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print("The loss of {} is {}".format(epoch,loss.item()))
# Bcakward
optimizer.zero_grad()
loss.backward()
# Updata
optimizer.step()
torch.save(model.state_dict(), 'diabetes.pth')
文章出处登录后可见!
已经登录?立即刷新