收集、读取、预处理数据,模型搭建、训练。
Pokemon Dataset


数据集加载
自定义数据集
__len__()函数返回数据集的数量,限制数据集迭代次数;
__getitem__索引样本;

import torch
from torch.utils.data import Dataset
class NumberDataset(Dataset):
def __init__(self, training = True) -> None:
super().__init__()
self.training = training
if training:
self.samples = list(range(1, 1001))
else:
self.samples = list(range(1001, 1501))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
data = NumberDataset(True)
print(len(data))
print(data[10])
输出:
1000
11
数据预处理
- resize
- 数据增强
增加数据集规模,辅助性提升一部分性能; - 归一化
将数据分布缩放为一个指定均值和方差的正态分布; - 转换为Tensor
将其它数据类型转换为pytorch的Tensor
图像数据存储结构
推荐采用一个label文件夹存储该label的图像;pytorch易于管理,它提供了一个API可以直接读取出这种存储结构的数据,而不用我们人为去写一个读取这些数据的代码;

代码
import torch
import os, csv
import random, glob
from torch.utils.data import Dataset
import visdom,time
from torchvision import transforms
from PIL import Image
class Pokemon(Dataset):
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = dict() # 将string转换为label
for name in sorted(os.listdir(root)):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# image, label 将图像数据和label一一对应
self.images, self.labels = self.load_csv('img_label.csv')
if mode == 'train': # 60%
self.images = self.images[:int(0.6*len(self.images))] #取数据集的前60%作为训练集
self.labels = self.labels[:int(0.6*len(self.labels))]
elif mode == 'val': # 20% : 60%->80%
self.images = self.images[int(0.6*len(self.images)): int(0.8*len(self.images))] #取数据集的前60%-80%作为验证集
self.labels = self.labels[int(0.6*len(self.labels)): int(0.8*len(self.labels))]
else: #20% : 80%->100%
self.images = self.images[int(0.8*len(self.images)):] #取数据集的最后20%作为测试集
self.labels = self.labels[int(0.8*len(self.labels)):]
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
#将每一类图像的path提取出来存入image
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root, name, '*.png')) #Return a list of paths matching a pathname pattern.
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images))
#保存image path和label的对应关系,这里保存到csv文件中,节约内存
with open(os.path.join(self.root, filename), mode = 'w', newline='') as f:
writer = csv.writer(f)
for img in images:
name = img.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img, label])
print('write to csv file:', filename)
images = []
labels = []
#将image path和label的对应关系再重新读取出来
with open(os.path.join(self.root, filename), mode='r') as f:
reader = csv.reader(f)
for row in reader:
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images,labels
def denormalize(self, x): #c,h,w
mean = [0.485, 0.456, 0.406] # c
std = [0.229, 0.224, 0.225] # c
x = x*(torch.tensor(std).unsqueeze(1).unsqueeze(1)) + \
torch.tensor(mean).unsqueeze(1).unsqueeze(1)
return x
def __len__(self):
return len(self.images)
def __getitem__(self, index):
# indx: [0~len(slef.images)]
img_path = self.images[index]
label = self.labels[index]
tf = transforms.Compose([
lambda x: Image.open(img_path).convert('RGB'), # string path => image
transforms.Resize((int(self.resize*1.5), int(self.resize*1.5))),
transforms.RandomRotation(15), #如果旋转角度太大,可能会导致网络不收敛
transforms.CenterCrop(self.resize), #裁剪成一个指定大小的形状
transforms.ToTensor(),
transforms.Normalize(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])
])
img = tf(img_path)
label = torch.tensor(label)
return img, label
def main():
vis = visdom.Visdom()
data = Pokemon('G:\BaiduNetdiskDownload\pokemon\pokeman', 224, 'train')
x,y = next(iter(data))
print(x.shape)
print(y.shape)
vis.image(data.denormalize(x), win = 'sample_x', opts=dict(title='sample_x'))
if __name__ == '__main__':
main()
输出:
Setting up a new session...
torch.Size([3, 224, 224])
torch.Size([])
visdom:http://localhost:8097/
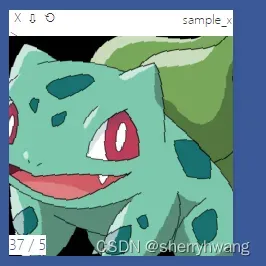
上述代码,可以通过torchvision.datasets.ImageFolder实现数据的读取和封装;
这种方式不是适合所有情况,只适合数据非常规整的存储了,并且如果对数据有一些额外的操作,还是要自己定义数据类。
import torchvision
tf = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
])
db = torchvision.datasets.ImageFolder(root='G:\BaiduNetdiskDownload\pokemon\pokeman', transform=tf)
print(len(db))
x,y = next(iter(db))
print(x.shape)
print(y)
print(db.class_to_idx)
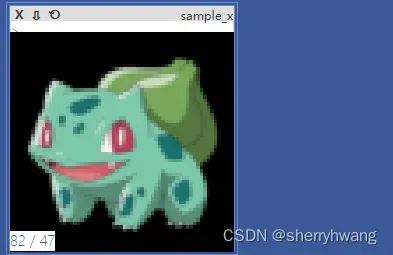
vis.image(x, win = 'sample_x', opts=dict(title='sample_x'))
输出:
1167
torch.Size([3, 64, 64])
0
{'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
visdom:http://localhost:8097/
构建模型

ResNet18
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResBlk(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride= stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential()
if in_channels != out_channels:
self.extra = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = F.relu(out + self.extra(x))
return out
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(16)
)
# fllow 4 blocks
self.block1 = ResBlk(16, 32 ,2)
self.block2 = ResBlk(32, 64, 2)
self.block3 = ResBlk(64, 128, 2)
self.block4 = ResBlk(128, 256, 2)
self.pool = nn.AdaptiveAvgPool2d((1,1))
self.outlayer = nn.Linear(256, 5)
def forward(self, x):
x = self.conv1(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.pool(x).flatten(1)
logits = self.outlayer(x)
return logits
if __name__ == '__main__':
x = torch.rand(3,3, 224, 224)
model = ResNet()
out = model(x)
p = sum(map(lambda p:p.numel(), model.parameters())) # torch.numel()函数,查看一个张量有多少元素
print(out.shape)
print('parameters size:', p)
输出:
torch.Size([3, 5])
parameters size: 1224645
训练模型
import torch
import torch.nn as nn
import torchvision
import visdom
from torch.utils.data import DataLoader
from pokemon import Pokemon
from resnet import ResNet
batch_size = 32
lr = 1e-3
epoches = 10
device = torch.device('cpu')
torch.manual_seed(1234)
root = 'G:\BaiduNetdiskDownload\pokemon\pokeman'
def evaluate(model, loader):
correct = 0.
for x,y in loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
preds = logits.argmax(dim = 1)
correct += preds.eq(y).sum().float().item()
print('total correct:', correct)
acc = correct / len(loader.dataset)
return acc
def train():
vis = visdom.Visdom()
train_db = Pokemon(root, 224, 'train')
val_db = Pokemon(root, 224, 'val')
test_db = Pokemon(root, 224, 'test')
print('train:', len(train_db))
print('val:', len(val_db))
print('test:', len(test_db))
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle = True, num_workers=4)
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=2)
model = ResNet().to(device)
criteon = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = lr)
best_acc = 0.
best_epoch = 0
global_step = 0
for epoch in range(epoches):
model.train()
for step, (x,y) in enumerate(train_loader):
x,y = x.to(device), y.to(device)
# print(y)
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
global_step += 1
if step %2 == 0:
print('epoch:[{}/{}]\tloss:{}'.format(step, epoch, loss.item()))
vis.line([loss.item()], [global_step], win='loss', update='append')
# evaluate
model.eval()
val_acc = evaluate(model, val_loader)
print('epoch:[{}]\t accuracy:{}'.format(epoch, val_acc))
vis.line([val_acc], [global_step], win='val_acc', update='append')
if val_acc > best_acc:
torch.save(model.state_dict(), 'best_model.pth')
best_acc = val_acc
best_epoch = epoch
print('save model....')
# test
best_model = ResNet()
best_model.load_state_dict(torch.load('best_model.pth'))
best_acc = evaluate(best_model, test_loader)
print('best acc:', best_acc, 'best epoch:', best_epoch)
if __name__ == '__main__':
train()
输出:
...
epoch:[10/1] loss:0.32095620036125183
epoch:[12/1] loss:0.8680893182754517
epoch:[14/1] loss:0.5944045782089233
epoch:[16/1] loss:0.8467034101486206
epoch:[18/1] loss:0.442536860704422
epoch:[20/1] loss:0.5616939663887024
total correct: 192.0
epoch:[1] accuracy:0.8240343347639485
save model....
epoch:[0/2] loss:0.5097338557243347
...
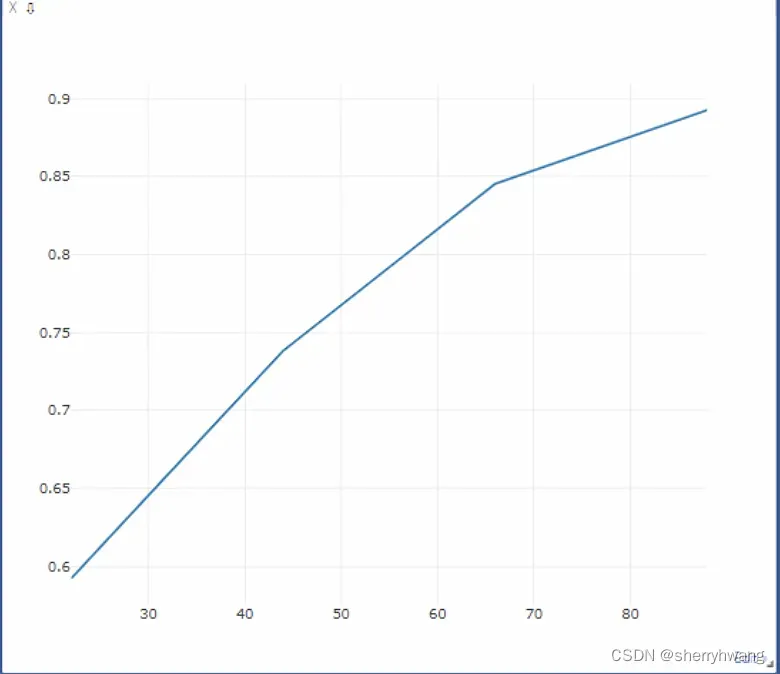
训练过程的visdom:
loss曲线
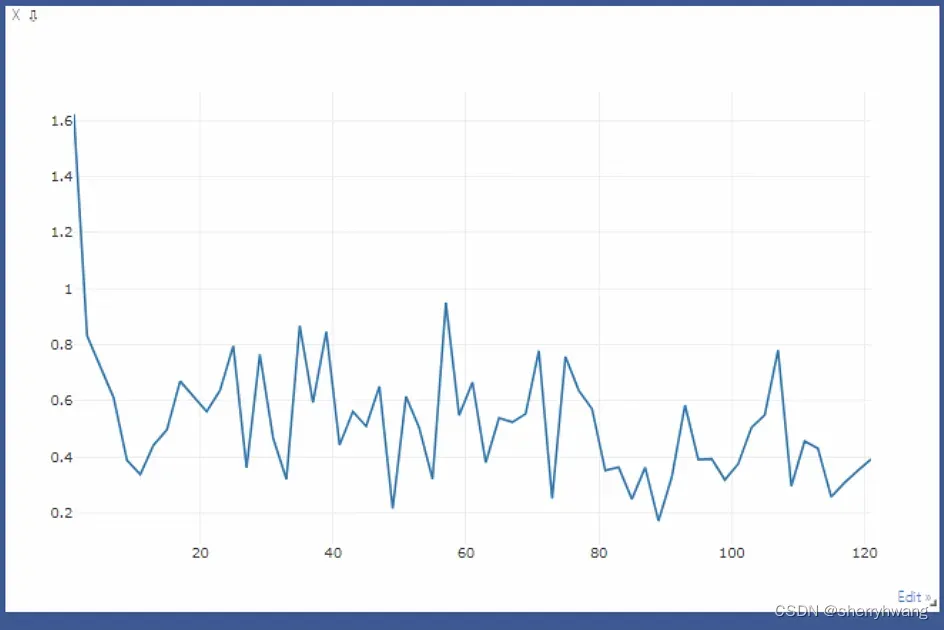
acc曲线;
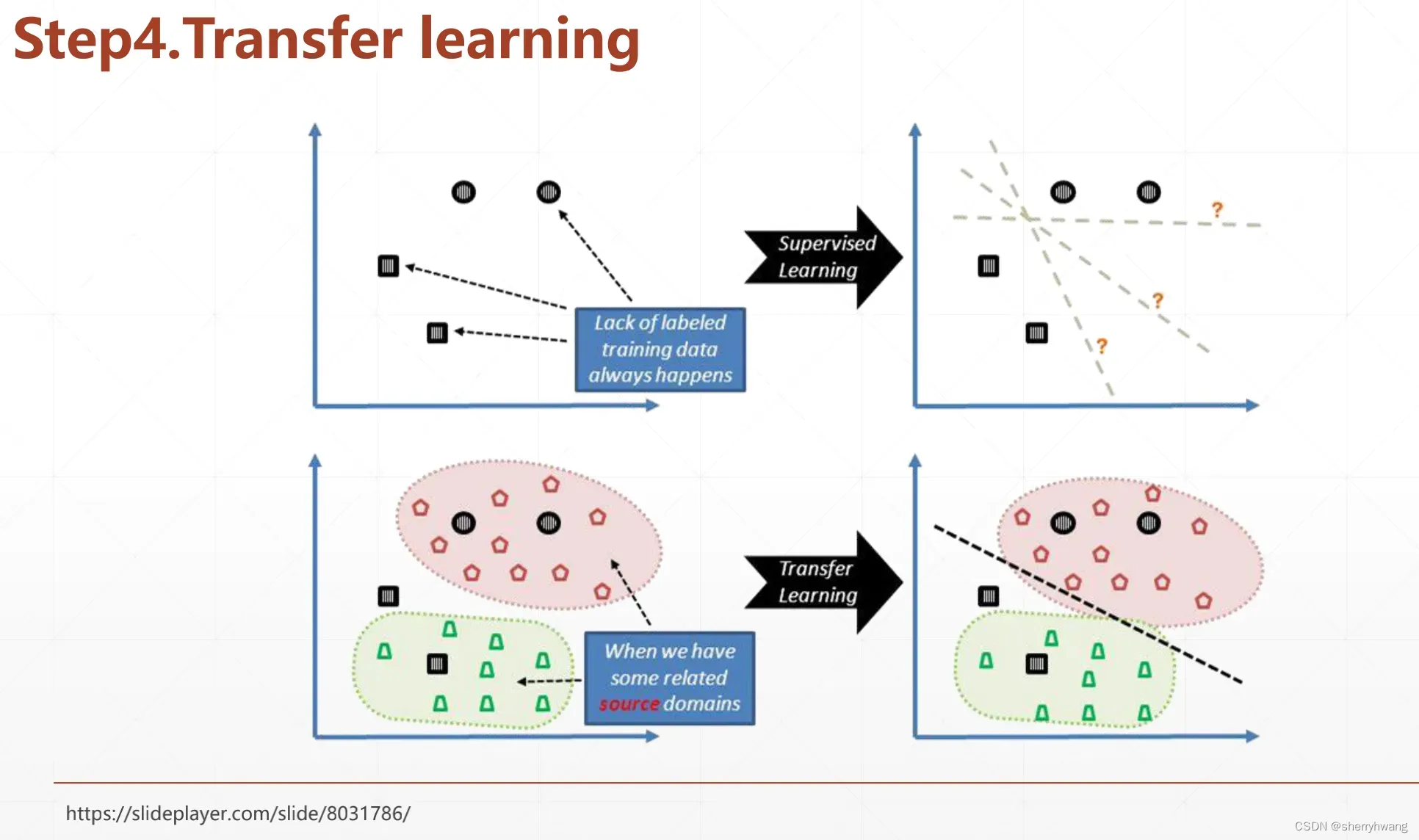
迁移学习
图像数据集与源域数据集存在比较多的重合的话(或者分布相似)比如ImageNet,那么可以使用源域数据集训练好的模型来辅助现在的特定任务,即将在A任务上训练好一个分类器,然后transfer到B任务上去;在B任务上叫微调,finetuning;
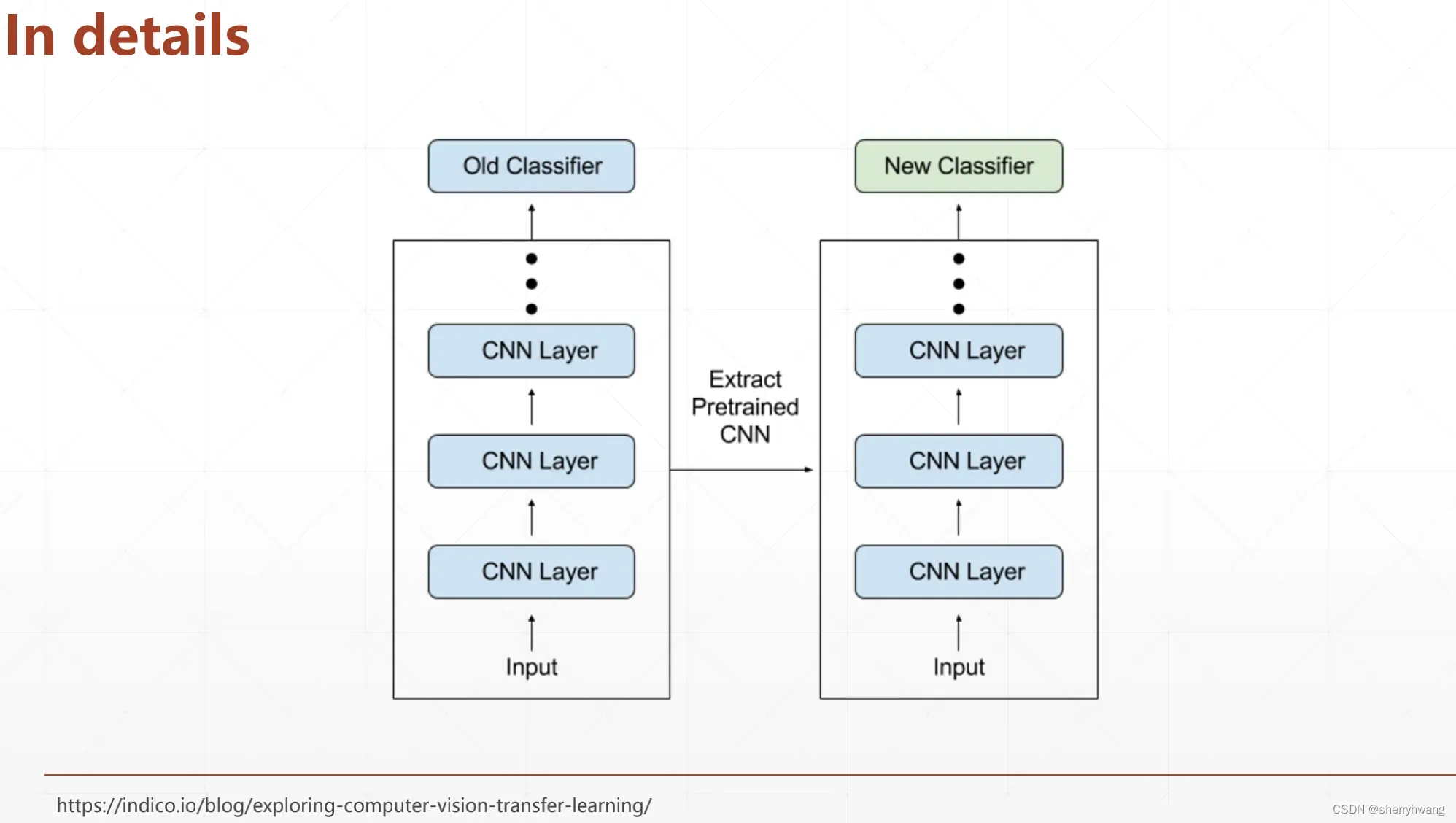
from torchvision.models import resnet18
class Flatten(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x):
return x.flatten(1)
trained_model = resnet18(pretrained=True).to(device)
model = nn.Sequential(
*list(trained_model.children())[:-1], #取resnet18前17层, 该层输出为[b,512,1,1]
Flatten(),
nn.Linear(512,5)
)
输出:
...
epoch:[0/0] loss:1.823586344718933
epoch:[2/0] loss:0.30410656332969666
epoch:[4/0] loss:0.7876781821250916
epoch:[6/0] loss:0.8662126660346985
epoch:[8/0] loss:0.5194013714790344
epoch:[10/0] loss:0.390007346868515
...
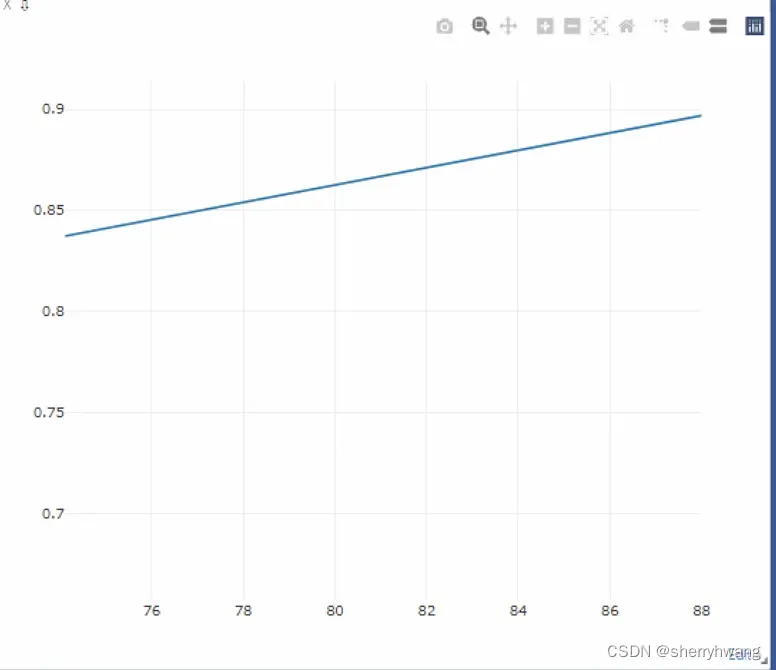
部分visdom可视化:
loss曲线
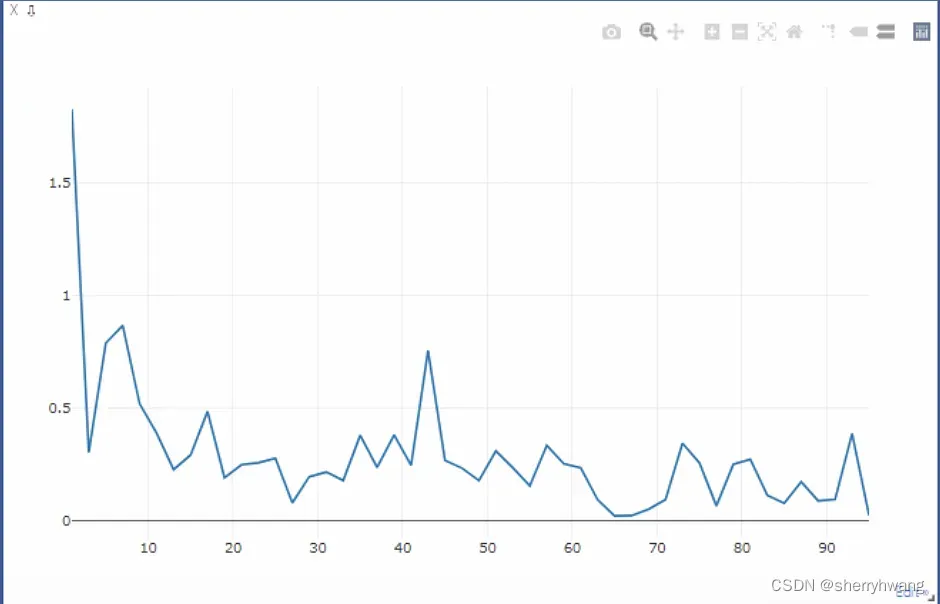
acc曲线
文章出处登录后可见!
已经登录?立即刷新