



DATA ENGINEERING
时间序列数据库的前景
对当今时间序列数据库的简短调查
Background
在使用了一些重要的时间序列数据库产品并从技术爱好者的角度探索了其他产品之后,我认为在快速的文章中总结我所学到的东西可能会有所帮助。当我在 2017 年开始使用 InfluxDB 寻找同事想要建立的算法期权交易平台时,我开始喜欢上时间序列数据库。我们进行了几天的头脑风暴。没有任何结果,除了我对 InfluxDB 的捣乱激发了我对时间序列数据库的兴趣。从那时起,我一直在了解 TSDB 世界的最新动态。
我之前写过关于时间序列数据库的文章。我已经介绍了它们空前的受欢迎程度以及其他一些专门的数据库,或者 AWS 喜欢称之为专用数据库。我还谈到了一些流行数据库的具体功能,如 InfluxDB(流入线路协议)、TimescaleDB(使用 TSBS 的比较)和 QuestDB(摄取模式)。在本文中,我将介绍最流行的时间序列数据库和几个不是专门为解决时间序列问题而构建的数据库,并且可以很好地处理它。所以,事不宜迟,让我们直接进入它。[0][1]
Timeseries Databases
InfluxDB[0]
用于指标、事件和实时分析的可扩展数据存储。
InfluxDB 是一个开源数据库。到目前为止,这是世界上最受欢迎和使用最多的时间序列数据库。 InfluxData 通过在本地和云端提供该数据库的企业版本来赚钱。与大多数其他 TSDB 一样,您可以在三个主要云平台(AWS、Google Cloud 和 Azure)中的任何一个上部署 InfluxDB。[0][1][2][3][4]
InfluxDB 还为您提供流行用例的模板。一个有趣的用例是监控 Counter-Strike 的游戏指标,如下图所示:

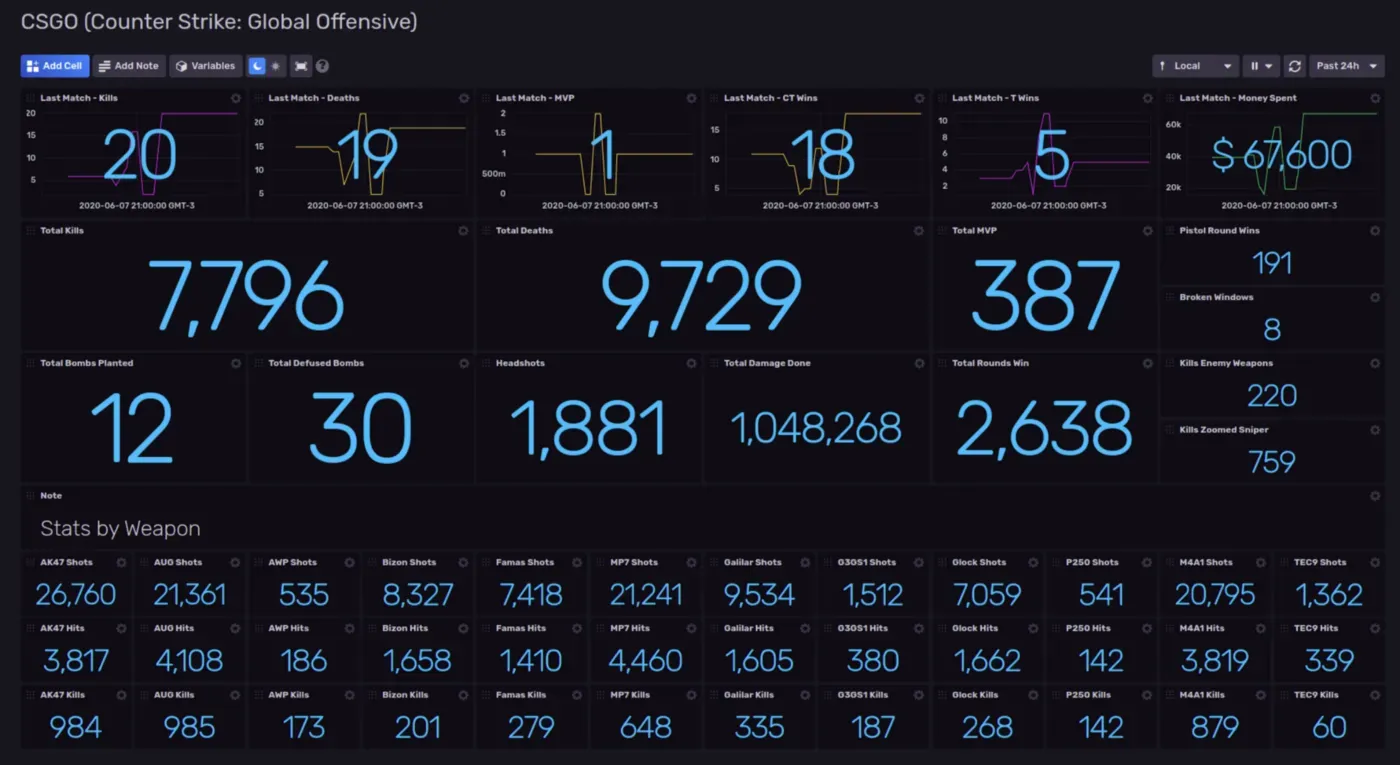
毫无疑问,InfluxDB 在过去几年中对加速时间序列数据库的发展起到了重要作用。一个这样的例子是 InfluxDB 线路协议,这是一种轻量级协议,用于存储时间序列数据并将其传输到时间序列数据库中。另一个主要的时序数据库 QuestDB 支持 PostgreSQL 有线协议,由于其实现和性能,决定支持和推动 InfluxDB 线协议。[0]
您可以在此博客上阅读有关他们旅程的更多信息。[0]
QuestDB[0]
一个开源 SQL 数据库,旨在更快地处理时间序列数据
Vlad Ilyushchenko 在 2010 年代初就职于金融服务行业,他非常清楚低延迟在金融领域的重要性。他将 QuestDB 作为一个附带项目来创建一个可大规模运行的超快时间序列数据库。最近,Vlad 在卡内基梅隆大学数据库组谈到了 QuestDB 的架构和激动人心的用例:

QuestDB 使用柱状结构来存储数据。 QuestDB 在每列的底部附加任何新数据,以保留摄取数据的自然时间顺序。该数据库还支持时间序列数据的关系建模,这意味着您可以编写连接并使用 SQL 查询来读取数据。
与当今许多其他时间序列数据库一样,QuestDB 也受到开源关系数据库庞然大物 PostgreSQL 的启发。就像在 Redshift 中运行大多数 PostgreSQL 查询一样,您可以在 QuestDB 中运行大部分查询。这在 QuestDB 中是可能的,因为它支持 Postgres 有线协议。这种 Postgres 兼容性还意味着您用于连接到 PostgreSQL 的大多数驱动程序也可以与 QuestDB 一起使用。您可以在此处找到 QuestDB 的 PostgreSQL 兼容性的优点和限制。[0]
已经有一段时间了,但我写过关于使用 TSBS(Timeseries Benchmarking Suite)对 QuestDB 和 TimescaleDB 性能进行基准测试的文章。您基本上可以使用 TSBS 来比较市场上的大多数时间序列数据库。这是 GitHub 存储库。[0]
TimescaleDB[0]
一个开源时间序列 SQL 数据库,针对快速摄取和复杂查询进行了优化。它被打包为 PostgreSQL 扩展。
PostgreSQL 的一大特点是它的可扩展性。许多令人惊叹的数据库都建立在 PostgreSQL 上并非巧合。例如,Redshift 就是其中之一。 TimescaleDB 是许多其他数据库中的另一个。 TimescaleDB 本质上是 PostgreSQL 之上的一个包扩展,解决了具有时间序列数据的特定读写模式。在下面的视频中,Erik Nordström 谈到了 TimescaleDB 的工作原理以及它与其他竞争对手的比较:[0]
TimescaleDB 可以下载和自托管。它还可以通过多云管理平台 Aiven 托管在您选择的平台上的云中。对于本文中讨论的许多数据库,我已经讨论了 AWS 上的不同部署选项:
TimescaleDB 还提供 Promscale,这是一个 Prometheus 的数据库后端,可以有效地处理 OpenTelemetry 数据。您可以在官方博客上详细了解 TimescaleDB 与 PostgreSQL 的区别以及其他产品的不同之处。[0][1][2]
kdb+[0]
这是独一无二的。 kdb+ 是一个支持关系建模和内存计算的列式时间序列数据库。它在高科技金融交易行业已经有好几年了。 kdb+ 是用一种很少使用的编程语言 k 编写的。这种语言以其数组处理能力而闻名。查询语言也基于 k 的变体,称为 q。在本教程中亲自了解这两种语言的深奥本质。[0]
老实说,我不认识任何从事或曾经从事过 kdb+ 工作的人,但这可以说这是一个远离主流的小众产品。您会发现有足够多的公司在使用不太常见的架构模式,例如此处描述的那种,其中涉及使用 Amazon FSx for Lustre 和许多 EC2 实例、S3 存储桶等,用于 kdb+ 的服务,如 Tickerplant、实时数据库、历史数据库、复杂事件处理 (CEP) 和网关。 Azure、Google Cloud 和 Digital Ocean 上也有类似的架构。[0][1][2]
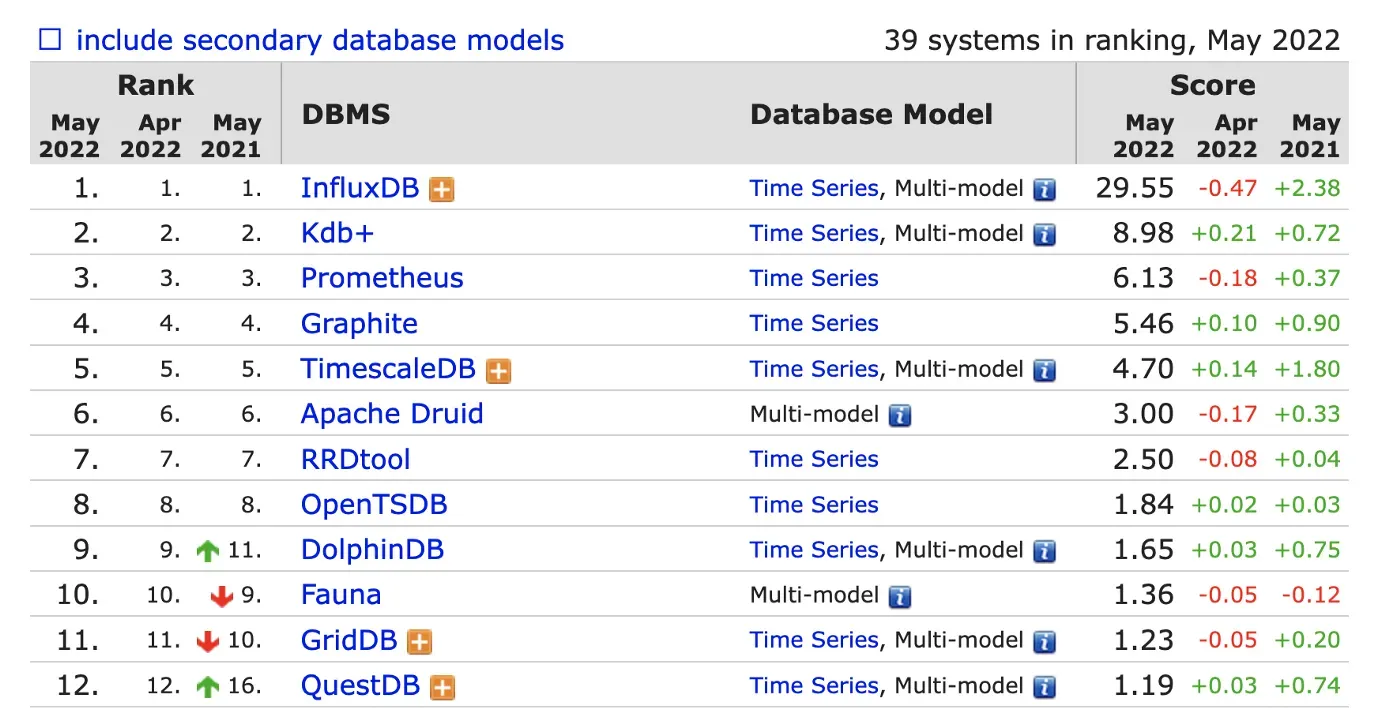
Databricks 与 kdb+ 合作,使用 Spark 实现超快速的金融时间序列数据分析。您可以使用多种选项将 Databricks 与 kdb+ 结合使用,包括 PyQ、Databricks API、使用 JDBC 的联合查询等。数据库排名网站 db-engines.com 在时序数据库类别中排名第二,仅次于 InfluxDB。尽管我有理由怀疑你在下一份工作中是否需要 kdb+,但知道它是什么并没有什么坏处。-[0]

Druid[0]
Druid 不一定只是一个时间序列数据库,但它通常用于时间排序数据的超快速聚合。因此,Druid 被更好地识别为基于时间的分析数据库。正因为如此,Druid 的架构壮举在于它所服务的各种用例。一些用例与 InfluxDB 和 TimescaleDB 等时间序列数据库重叠,例如网络遥测分析和应用程序性能分析。由于这种重叠,Druid 说它结合了数据仓库、时间序列数据库和搜索系统。[0]
它的核心重点是成为具有列式存储和实时和批量摄取功能的分布式 MPP 系统,这对于您的数据工程堆栈来说是一个令人兴奋的工具。对于超快速查询,Druid 使用压缩位图索引和基于时间的分区来修剪您不需要的数据。 Druid 使用基于 JSON 的查询语言,类似于您在 MongoDB 或 Cassandra 中看到的。尽管如此,因为每个人都知道 SQL 并使用 SQL 与数据交互,所以 Druid 还提供了 Druid SQL,它是原生查询引擎之上的包装器。[0]
Netflix、Airbnb、Salesforce、Booking、Appsflyer、Criteo 和 PayPal 等公司在生产中使用 Druid。以下是 Netflix 技术博客中的一个案例研究示例,讲述了他们如何使用 Druid 和 Kafka 来实时提供见解:
我还建议 Roman Leventov 的另一篇博客文章讨论 Druid、Pinot 和 ClickHouse 之间的区别。[0]
Conclusion
时间序列数据库非常适合许多用例,尤其是当您默认使用数据获得自然时间顺序时。由于需求,时间序列数据库的数量不时增加。这也导致一些云平台提出了他们的时间序列数据库,部分或全部受到开源同行的启发。在接下来的几年里,我们将在时间序列数据库领域看到更多的采用。作为一个 SQL 人,我可能会有偏见,但我确实认为大多数时间序列数据库都会尝试支持 ANSI SQL 标准。让我们来看看。
如果您觉得我的文章有用,请订阅并查看我在 🌲 Linktree 上的文章。您也可以考虑通过使用我的推荐链接购买中等会员资格来支持我。干杯![0][1]
文章出处登录后可见!