深度网络的置信度校准:为什么以及如何?
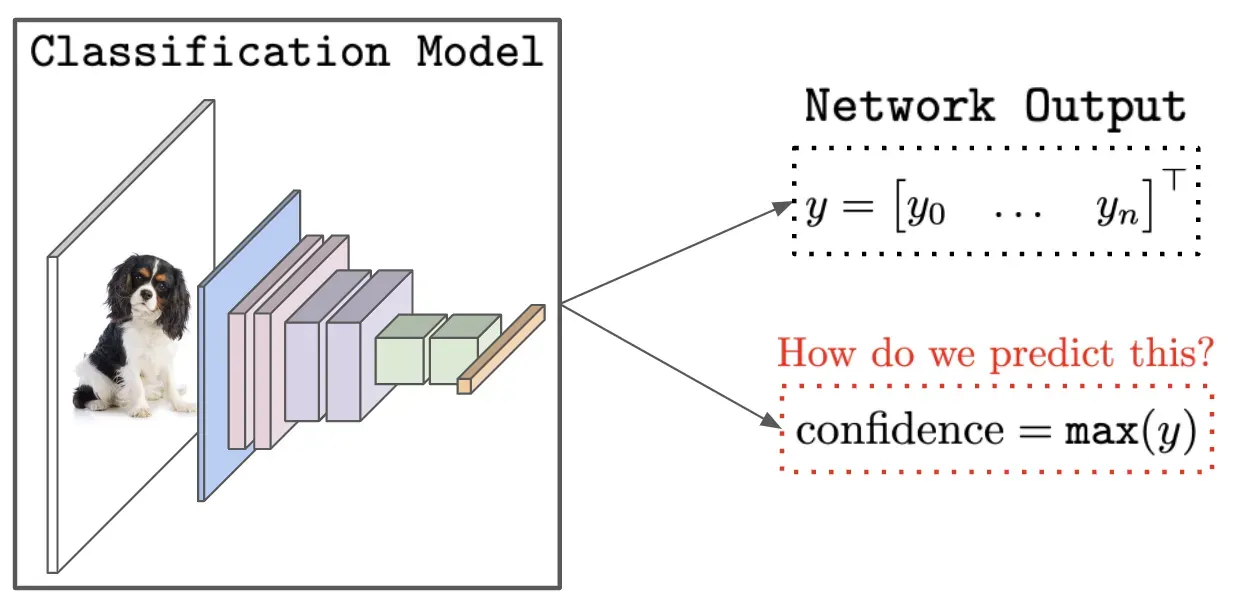
置信度校准被定义为某个模型为其任何预测提供准确概率的能力。换句话说,如果一个神经网络以 0.2 的置信度预测某个图像是一只猫,那么如果神经网络经过正确校准,这个预测应该有 20% 的机会是正确的。这种校准后的置信度分数在各种“高风险”应用中很重要,在这些应用程序中,不正确的预测是非常成问题的(例如,自动驾驶汽车、医疗诊断等),因为与每个预测相关的校准概率分数允许低质量的预测是识别并丢弃。因此,即使神经网络输出还不能完全解释,置信度校准通过将每个预测与准确的不确定性/置信度分数相关联,为避免实践中的重大错误提供了一种实用的途径。
在这篇博文中,我将探讨深度学习中的置信度校准主题,从置信度校准背后的动机、为什么它很重要以及如何使用它开始。然后,我将概述测量置信度校准的常用方法,包括 Brier 分数、预期校准误差、最大校准误差等。最后,我将概述深度学习中现有的置信度校准方法,重点介绍在大规模应用中最有效和最高效的方法。
为什么校准很重要?
从业者经常错误地将从神经网络获得的预测概率(即 softmax 分数)解释为模型置信度。然而,众所周知,现代神经网络经常做出糟糕的(即不正确的)预测,softmax 分数接近 100%,这使得预测概率成为对真实置信度的糟糕和误导性估计 [2]。尽管前几代神经网络并没有以这种方式“过度自信”,但从神经网络预测中获得准确的不确定性分数的问题并不简单——我们如何才能让 softmax 分数真正反映给定预测的正确概率?
目前,深度学习已在众多领域(例如图像/语言处理)中得到普及,并且通常用于可以接受错误的应用中。例如,考虑一个电子商务推荐应用程序,其中神经网络可能会在 90% 以上的情况下做出高质量的推荐,但偶尔会无法发现最相关的产品。尽管此类应用很多,但将深度学习部署到医疗诊断或核能等高风险领域需要尽可能减少不正确的模型预测。因此,准确预测模型的不确定性是一个有影响力的问题,有可能扩大深度学习的范围。
Potential Applications
鉴于置信度校准是一个可能对深度学习社区产生巨大影响的重要问题,人们可能想知道哪些类型的应用程序最依赖于正确校准的不确定性。虽然有很多,但我在本节中概述了一些,以提供相关背景并激发实践中信心校准的好处。
过滤不良预测。给定一个经过适当校准的模型,可以丢弃具有高不确定性(或低置信度)的预测,以避免不必要的模型错误。这种基于与每个预测相关联的置信度得分丢弃不正确预测的能力在上述高风险应用中特别有影响。尽管在短期内真正解释或理解神经网络输出可能仍然很困难,但正确校准的不确定性分数为检测和避免神经网络的错误提供了实用的途径。
模型感知主动学习。正确的不确定性估计使模型难以理解的数据很容易被识别。因此,与低置信度预测相关的数据可以被搁置一旁,并传递给人工注释者进行标记并包含在模型的训练集中。通过这种方式,模型不确定性可用于迭代识别模型不理解的数据,从而实现一种模型感知主动学习。[0]
检测 OOD 数据。具有良好校准特性的模型通常可用于检测分布外 (OOD) 数据,或与模型训练集显着不同的数据。尽管校准和 OOD 检测是正交问题——例如,尽管校准不佳,但 softmax 分数可以直接用于检测 OOD 数据 [16]——但它们通常被串联研究,其中最佳校准方法在校准和检测 OOD 数据的能力(即,通过为此类示例分配高不确定性/低置信度)[6]。
Measuring Calibration
尽管现在希望很清楚置信度校准是一个有用的属性,但与准确度或损失等具体性能指标相比,它并不容易衡量。因此,随着时间的推移,人们提出了各种不同的置信度校准指标,每种指标都有自己的优缺点。在本节中,我将按相关性顺序概述用于测量置信度校准的最广泛使用的指标。对于这些指标中的每一个,我将确定它是否是一个正确的评分规则——这意味着最佳分数对应于一个完美的预测并且不存在“琐碎的”最佳解决方案——解释分数的直观含义,并描述它是如何实现的计算出来的。[0]
Brier Score [1]
Brier 分数 (BS) 是一种适当的评分规则,用于测量预测概率向量和 one-hot 编码的真实标签之间的平方误差。较低的分数对应于更准确的校准;请参阅下图进行描述。
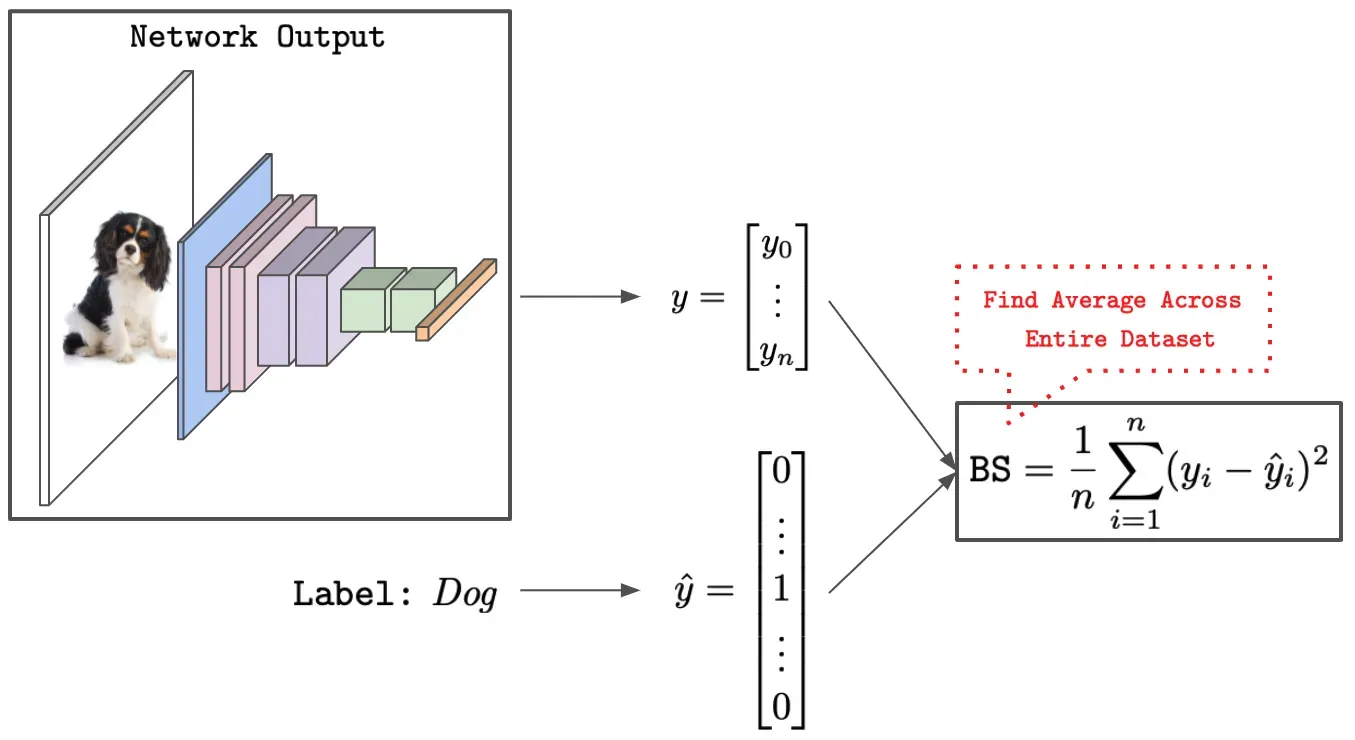
直观地说,BS 测量预测概率的准确性。它可以分解为三个部分——不确定性(标签的边际不确定性)、分辨率(个体预测与边际的偏差)和可靠性(真实标签频率的平均违反)——如下所示。[0]
尽管 BS 是衡量网络预测校准的良好指标,但它对与不频繁事件相关的概率不敏感。因此,利用除 BS 之外的多个指标来测量校准通常会提供有用的洞察力。
预期和最大校准误差 [2]
预期校准误差 (ECE) 计算置信度和准确度之间的预期差异。这种期望的差异可以如下计算。

尽管上述表达式不能以封闭形式计算,但我们可以通过根据相关的置信度分数将模型预测划分为单独的 bin 来近似它。然后,可以在每个 bin 内计算平均置信度和准确度之间的差异,如下图所示。
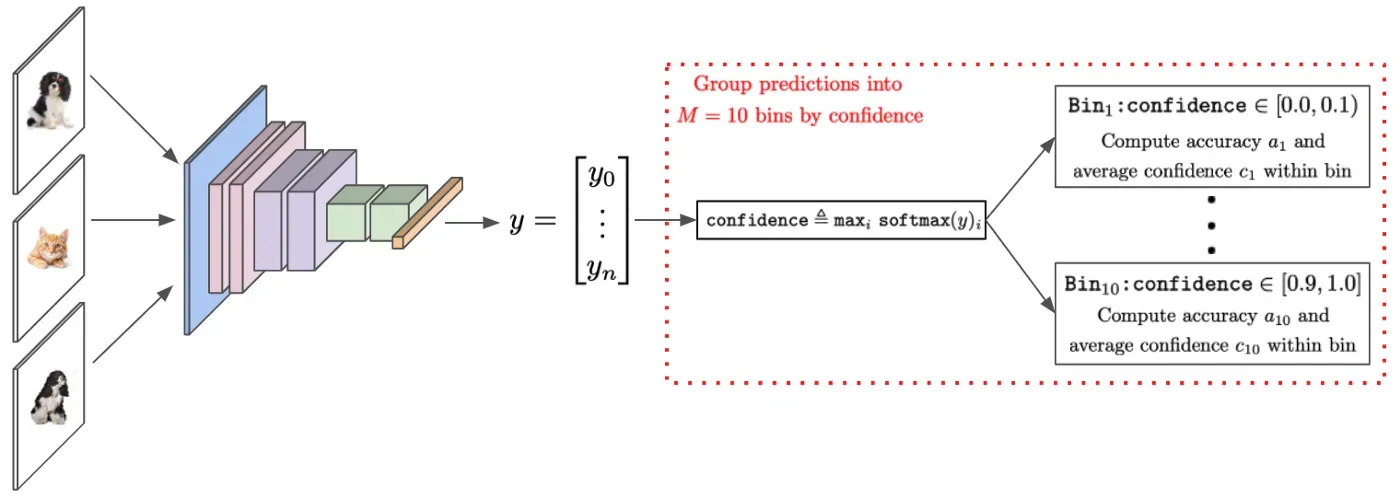
从这里,ECE 计算每个 bin 内的平均置信度和准确度之间的差异,然后根据每个 bin 的相对大小对这些值进行加权平均。最大校准误差 (MCE) 遵循相同的过程,但等于跨箱的平均置信度和准确度之间的最大差异。有关 ECE 和 MCE 的更严格的表述,请参见下图。
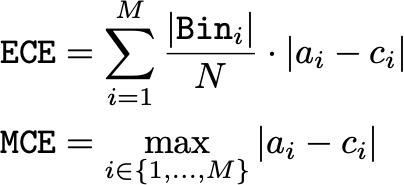
对于 ECE 和 MCE,较低的分数对应于更好的校准预测。 ECE 和 MCE 都不是正确的评分规则,这意味着存在具有最佳校准误差的琐碎解决方案(例如,预测均匀、随机概率)。此外,由于分箱过程,这些指标都不会随着预测的提高而单调下降。尽管如此,由于它们能够提供简单且可解释的模型校准估计,因此这些指标被普遍使用。 MCE 通常用于绝对需要可靠的置信度测量(即校准中的大错误是有害的)的应用中,而 ECE 提供更全面的跨箱平均度量。[0]
可靠性图。如果希望获得表征校准误差的图,而不是像 ECE 或 MCE 这样的标量度量,则可以轻松地将每个 bin 精度和置信度度量转换为可靠性图。这些图表在 y 轴上描绘了准确度,在 x 轴上描绘了平均置信度。然后,将每个 bin 内的平均置信度和准确度测量值绘制在图表上,形成线图。在这里,完美的校准将在可靠性图上产生一条对角线,其中置信度等于每个单独箱内的准确度;请参阅下面的插图。
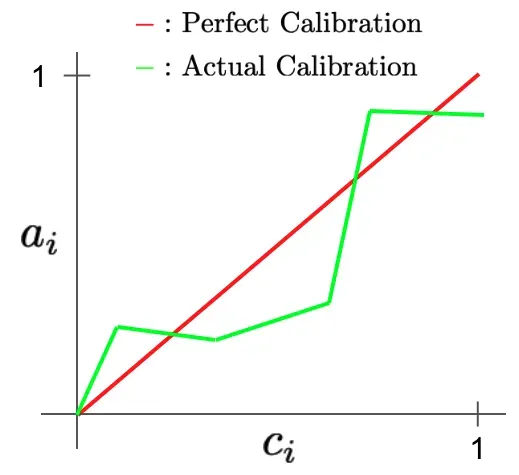
可靠性图通常可用于可视化所有箱的校准误差。虽然 ECE 和 MCE 将 bin 统计信息聚合为一个简单的标量指标,但可靠性图表可以同时查看每个 bin 的属性,从而在易于解释的图中捕获更多校准信息。
Negative Log-Likelihood
负对数似然 (NLL) 是一种适当的评分规则,可用于评估保留数据的模型不确定性,其中较低的分数对应于更好的校准。虽然 NLL 通常用作训练的目标函数,但 NLL 表征了真实标签的预测和实际置信度之间的差异,当所有数据都以 100% 的置信度正确预测时,达到完美的零分。有关 NLL 的公式,请参见下面的等式,其中 y 是某些神经网络的原始向量输出。[0]
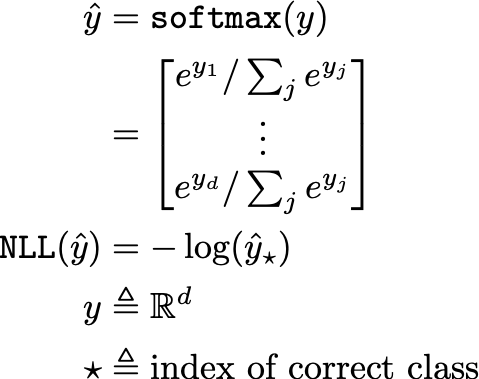
然而,NLL 过分强调尾部概率,这意味着与正确、完全自信的预测的轻微偏差会导致 NLL 大幅增加。可以很容易地观察到此属性对神经网络的影响,其中 NLL(即目标函数)相对于训练集可能非常低,但由于趋势,对测试集的错误预测是 100% 置信度的网络进行高置信度预测以最小化 NLL(即本文开头提到的“过度自信”问题)[2]。
Entropy
通常,我们可能想要评估模型对来自与训练集不同分布的数据的行为,因此没有模型可以理解的真实标签(即 OOD 数据)。在这种情况下,由于缺乏真正的标签,以前的指标都不能用于评估。相反,通常通过测量此类 OOD 数据产生的输出分布的熵来分析模型的行为。[0]
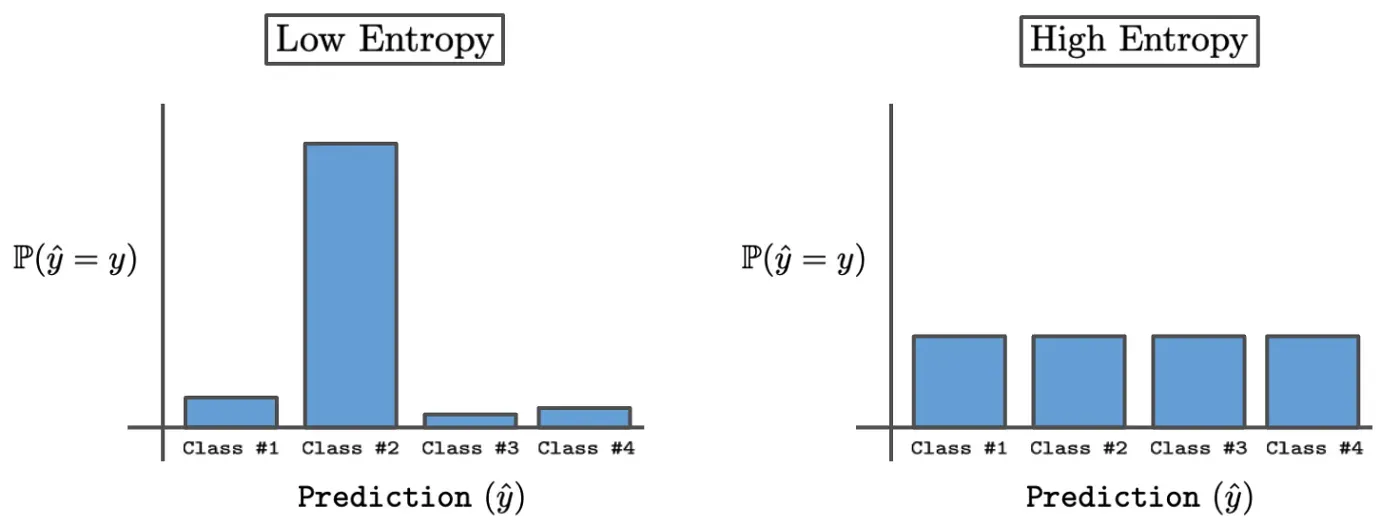
直观地说,OOD 数据应该导致具有高熵的网络预测,对应于一种不确定状态,其中所有可能的输出都被分配了统一的概率。另一方面,对易于理解的数据的网络预测应该具有低熵,因为如果模型准确且经过适当校准,则该模型会以高置信度预测正确的类别。因此,在通过一组包含 OOD 数据的测试示例评估模型时,对正常数据和 OOD 数据所做的预测的熵应该清楚地分开,这表明该模型在 OOD 示例上表现出可测量的不确定性。
Calibration Methodologies
在本节中,我将探讨为改进神经网络置信度校准而提出的众多方法。其中一些方法是可以添加到训练过程中的简单技巧,而另一些则需要利用保留验证集的后处理阶段,甚至需要对网络架构进行重大更改。在描述每种方法时,我将概述它们的优缺点,重点关注每种方法是否适用于大规模深度学习应用程序。
Temperature Scaling [2]
当首次发现和探索现代深度神经网络的不良校准时(即本文开头概述的“过度自信”问题),作者将此类网络做出过度自信、错误预测的趋势归因于最近的发展,例如增加神经网络大小/容量、批量归一化、权重衰减较小的训练,甚至使用 NLL 损失(即,由于强调尾部概率,这种损失将网络预测推向高置信度)。令人惊讶的是,与前几代架构(例如,LeNet [7])相比,这种用于神经网络训练的现代最佳实践——尽管产生的网络具有令人印象深刻的性能——却被发现产生的网络具有显着降低的校准特性。
为了解决这种糟糕的校准问题,[2] 的作者探索了几种不同的事后校准技术,这些技术在训练完成后使用一些保留验证集进行校准。他们发现调整输出层的 softmax 温度(即,在二进制设置 [8] 中称为 Platt Scaling)以最小化验证集上的 NLL 在校准网络预测时最有效。因此,softmax 变换被修改为如下所示的正值温度 T。
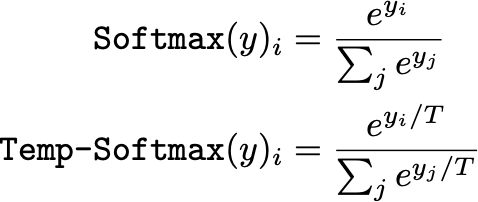
在这个表达式中,较大的 T 值将“软化”输出分布(即,将其移向均匀分布),而较小的 T 值将更加强调分布中的最大值输出。因此,T 参数实质上控制了输出分布的熵。
通过在保留验证集上调整 T 参数以优化 NLL,[2] 的作者能够显着改善网络校准。但是,此校准过程需要验证数据集,并在训练后作为单独的阶段执行。此外,后来的工作发现这种方法不能很好地处理 OOD 数据,并且当暴露给网络的数据是非 i.i.d 时完全失败。 [6]。因此,在给定足够不熟悉或对抗性数据的情况下,网络仍然可以以高置信度做出错误预测。[0]
Ensemble-based Calibration [9]
与单个网络相比,集成——或由几个独立训练的网络联合用于预测的组——众所周知,可以提供更好的性能[10]。然而,[9] 的作者证明,对集合内网络的预测进行平均也可用于得出有用的不确定性估计。特别是,通过以下方式修改训练过程:i)使用适当的评分规则(例如,NLL)作为目标函数,ii)使用对抗性示例 [11] 扩充训练集,以及 iii)训练网络集合;请参阅下面的描述。
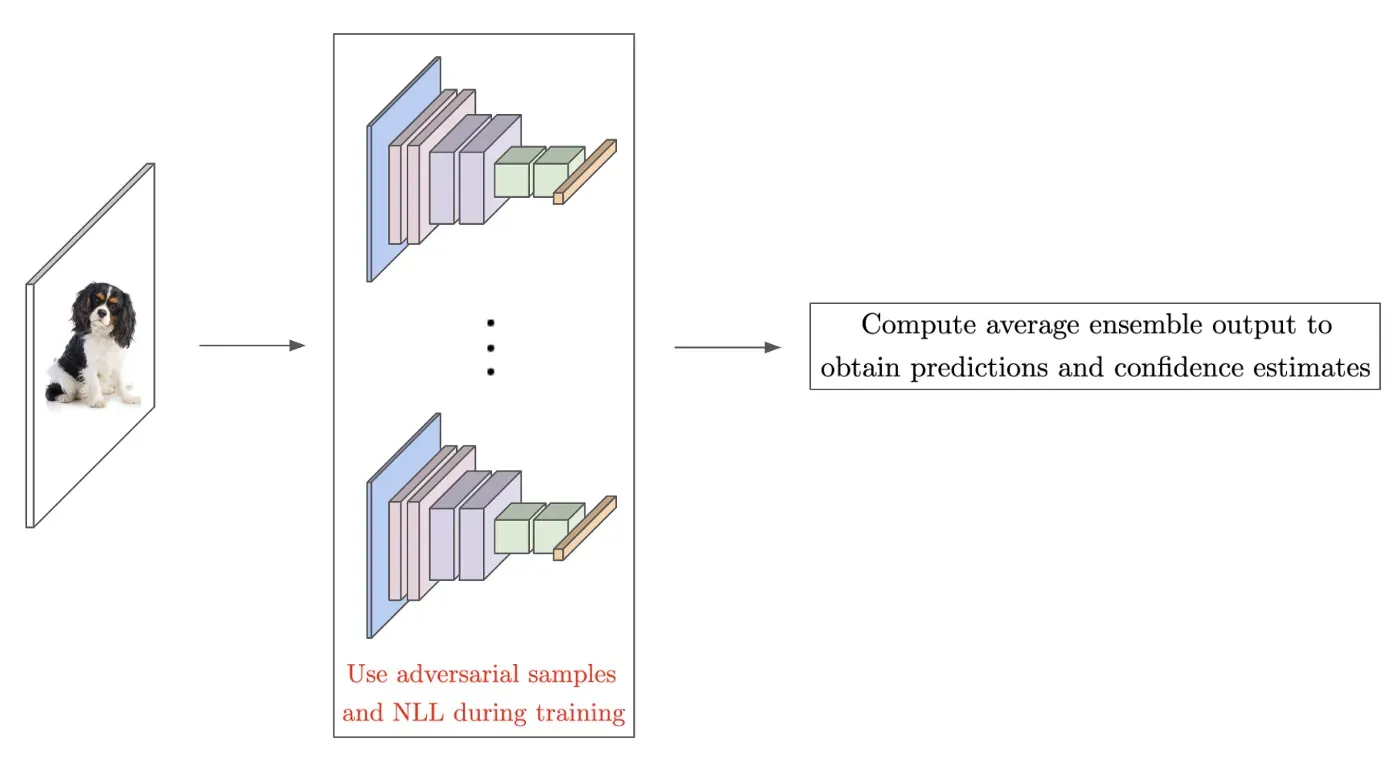
集成中的每个网络都是在整个数据集上独立训练的(即,使用不同的随机初始化和改组),这意味着集成中每个成员的训练可以并行执行。然后,通过对所得集合的预测进行平均,即使在大规模数据集上也可以获得高质量的不确定性估计。此外,这种方法被证明对数据集中的变化具有鲁棒性,允许准确检测 OOD 示例。因此,尽管会产生处理多个网络的额外计算成本,但基于集成的校准技术是简单、高度稳健和高性能的。
Mixup [12]
Mixup 是一种简单的数据增强技术,它通过将训练样本的凸组合与随机抽样(来自 beta 分布)加权并使用这些组合样本来训练网络来进行操作;请参阅下面的示意图。[0][1]
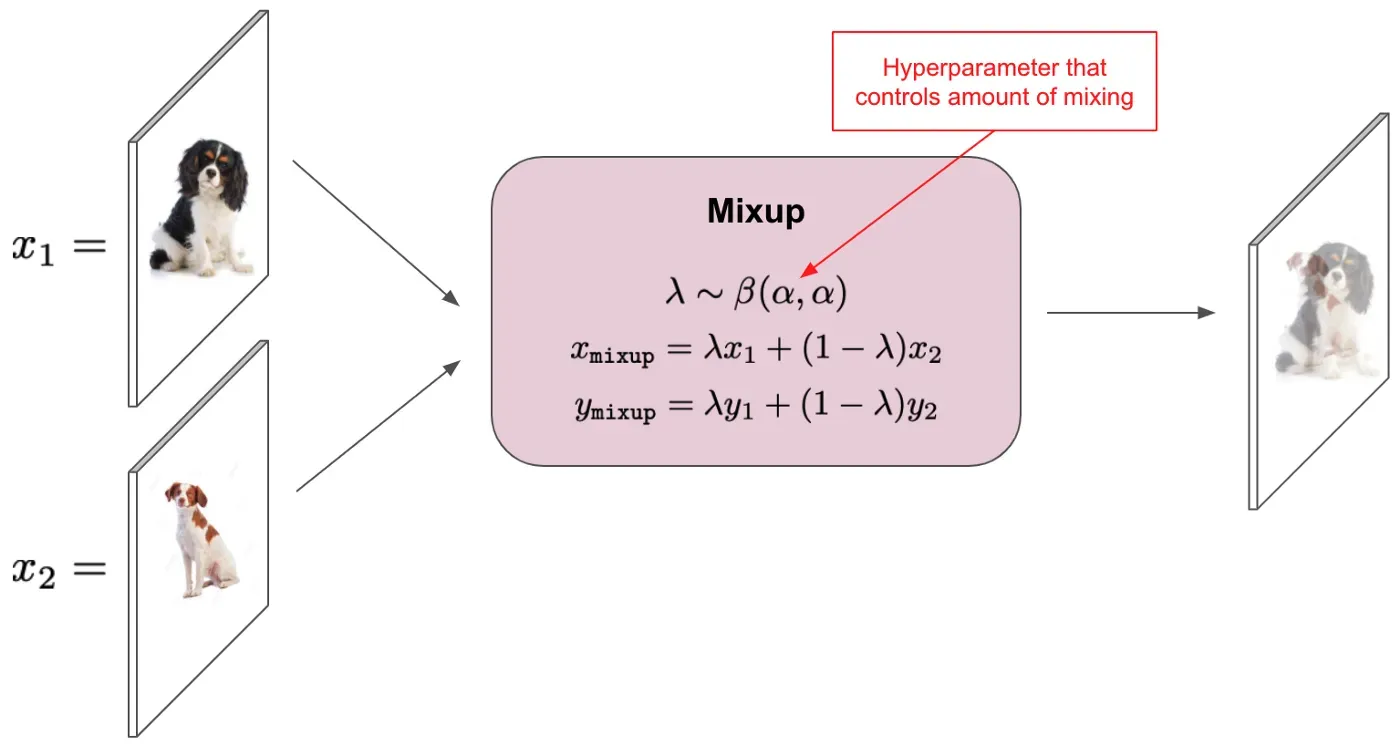
值得注意的是,mixup 结合了输入图像及其相关标签。此外,最近的工作 [13] 发现,在训练期间使用混合,除了提供显着的调节和性能优势外,还可以使分类模型具有改进的校准特性。这样的发现即使在规模上也成立,而且 Mixup(包括已提出的各种变体)甚至被证明在检测 OOD 数据方面是有效的 [14]。有趣的是,[13] 的作者发现简单地混合输入图像不足以实现校准的好处,这表明混合输出标签对于校准网络输出至关重要。研究标签平滑(即增加标签分布的熵)对网络性能和校准的影响的相关工作进一步支持了这一发现[15]。
Bayesian Neural Networks [3]
贝叶斯神经网络——受权重分布的无限宽神经网络收敛到高斯过程(因此具有封闭形式的不确定性估计)[4]的推动——可以简单地定义为分布在其上的有限神经网络权重。这样的公式为过度拟合提供了鲁棒性,并能够在网络中表示不确定性。然而,贝叶斯神经网络,即使使用了新开发的变分推理技术,也承受着过高的计算和内存成本。事实上,基础模型的大小通常必须加倍,才能使用贝叶斯公式进行正确的不确定性估计 [5]。因此,贝叶斯神经网络还不适合大规模应用,但我建议任何对这种方法感兴趣的人阅读这篇精彩而实用的概述。[0][1][2]
作为贝叶斯近似的辍学 [5]
如上所述,贝叶斯网络能够对模型的不确定性进行推理,但在计算成本方面常常令人望而却步。然而,最近的工作表明,使用 dropout [17] 训练的神经网络是高斯过程的贝叶斯近似。此外,通过简单地 i) 运行多个随机前向传递(具有不同的 dropout 实例)和 ii) 对每个前向传递的预测进行平均,可以利用此属性来生成深度网络预测的不确定性分数;有关此方法的描述,请参见下文,该方法通常称为 Monte Carlo dropout。
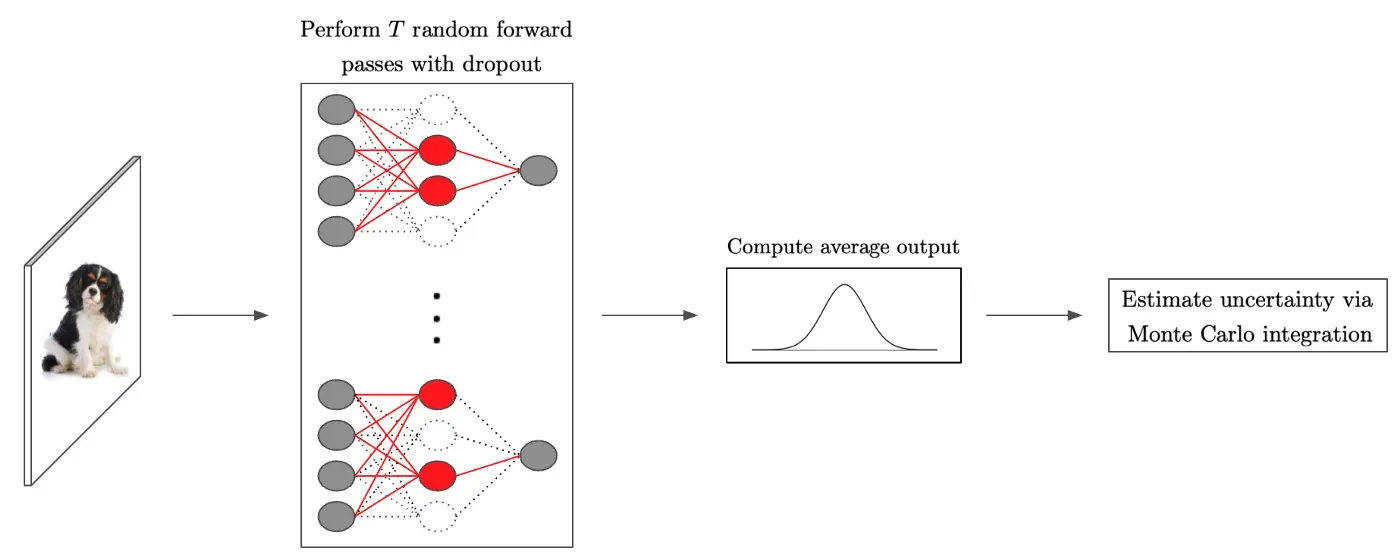
有趣的是,这种将 dropout 作为高斯过程的近似值的观点可以在不改变底层网络或需要任何事后处理的情况下实现稳健的不确定性估计。事实上,所需要的只是训练一个带有 dropout 的普通网络,并在测试时执行多个带有 dropout 的随机前向传递,其中每个不同的前向传递都可以并行化以避免增加延迟。这种方法在大规模应用中效果很好,并且显示出既可以实现最先进的置信度校准,又可以高精度地检测 OOD 数据。然而,基于 dropout 的校准的性能比上面讨论的基于集成的技术略差。
所以……你应该用什么?
尽管我们在这篇文章中概述了几种用于置信度校准的方法,但人们可能会问,哪种方法在实践中会提供最大的好处。这种确定的相关考虑因素是简单性、有效性和效率。我们已经看到,诸如温度缩放和利用贝叶斯神经网络的不确定性近似等方法可能无法在更大的尺度上很好地工作——例如,温度缩放在非独立同分布上中断。数据,而贝叶斯神经网络的计算成本很高,因此在某些情况下效率较低。其他方法效果很好,并提供了令人印象深刻的大规模校准结果。因此,鉴于这些方法通常是有效的,人们可能会开始考虑它们的简单性和效率。
Mixup 是一种易于实现(即,请参阅论文中的参考实现)的数据增强技术,可以将其添加到训练中以改进生成的网络的校准,使其成为校准神经网络的低成本和简单的选择网络。同样,利用网络集合提供了令人印象深刻的校准结果并且易于实现(即,只需训练更多网络!)。但是,它引入了训练多个网络并将它们全部用于预测的额外计算成本,因此与 Mixup 等数据增强技术相比,训练和预测的效率都下降了。更进一步,Monte Carlo dropout 不会降低训练效率并提供令人印象深刻的大规模不确定性校准,但在预测期间需要多次前向传递,并且通常优于基于集合的不确定性估计。因此,方法的选择通常是基于应用程序的,并且取决于操作的约束条件(例如,训练需要快速,因此使用 Mixup 或 Monte Carlo dropout,效率不是问题,因此使用集成等) .
Conclusion
非常感谢您阅读这篇文章!我希望你觉得它有帮助。如果您有任何反馈或疑虑,请随时对帖子发表评论或通过推特与我联系。如果您想关注我未来的工作,可以在 Medium 上关注我。我的博客专注于深度学习的实用技术,我尝试发布两篇关于从视频深度学习到使用深度网络在线学习技术等主题的文章。如果您对我的出版物和其他工作感兴趣,也可以随时查看我个人网站上的内容。这一系列帖子是我作为 Alegion 研究科学家的背景研究的一部分。如果您喜欢这篇文章,请随时查看该公司和任何相关的空缺职位——我们一直在寻求与对深度学习相关主题感兴趣的积极人士进行讨论或雇用![0][1][2][3][4][5]
Bibliography
[1] Brier, Glenn W. “以概率表示的预测验证。”每月天气回顾 78.1(1950):1-3。
[2] 郭,川,等。 “关于现代神经网络的校准。”机器学习国际会议。 2017 年,PMLR。
[3] Neal, Radford M. 神经网络的贝叶斯学习。卷。 118. 施普林格科学与商业媒体,2012 年。
[4] 威廉姆斯,克里斯托弗。 “用无限网络计算。”神经信息处理系统的进展 9 (1996)。
[5] Gal、Yarin 和 Zoubin Ghahramani。 “作为贝叶斯近似的辍学:表示深度学习中的模型不确定性。”机器学习国际会议。 2016 年,PMLR。
[6] 奥瓦迪亚、亚尼夫等人。 “你能相信你的模型的不确定性吗?评估数据集转移下的预测不确定性。”神经信息处理系统的进展 32 (2019)。
[7] LeCun、Yann 等人。 “基于梯度的学习应用于文档识别。” IEEE 86.11 (1998) 会议记录:2278–2324。
[8] 普拉特,约翰等人。支持向量机的概率输出以及与正则化似然方法的比较。大边距分类器的进展,10(3): 61–74, 1999。
[9] Lakshminarayanan、Balaji、Alexander Pritzel 和 Charles Blundell。 “使用深度集成进行简单且可扩展的预测不确定性估计。”神经信息处理系统的进展 30 (2017)。
[10] T. G. 迪特里希。机器学习中的集成方法。在多分类器系统中。 2000 年。
[11] I. J. Goodfellow、J. Shlens 和 C. Szegedy。解释和利用对抗性示例。在 ICLR,2015 年。
[12] 张宏义,等。 “混淆:超越经验风险最小化。” arXiv 预印本 arXiv:1710.09412 (2017)。
[13] Thulasidasan,苏尼尔,等人。 “关于混合训练:改进深度神经网络的校准和预测不确定性。”神经信息处理系统的进展 32 (2019)。
[14] Wolfe、Cameron R. 和 Keld T. Lundgaard。 “E-Stitchup:预训练嵌入的数据增强”。 arXiv 预印本 arXiv:1912.00772 (2019)。
[15] Müller、Rafael、Simon Kornblith 和 Geoffrey E. Hinton。 “标签平滑何时有帮助?”神经信息处理系统的进展 32 (2019)。
[16] 亨德利克斯、丹和凯文·金佩尔。 “用于检测神经网络中错误分类和分布外示例的基线。” arXiv 预印本 arXiv:1610.02136 (2016)。
[17] 斯利瓦斯塔瓦、尼蒂什等人。 “Dropout:一种防止神经网络过度拟合的简单方法。”机器学习研究杂志 15.1(2014):1929-1958。
文章出处登录后可见!