Data Cleaning
Python Pandas 中的数据清理入门
使用流行的 Python 库执行数据清理的实际示例。

数据清理是处理数据时的强制性步骤之一。事实上,在大多数情况下,您的数据集是脏的,因为它可能包含缺失值、重复项、错误格式等。在没有清理数据之前运行数据分析可能会导致错误的结果,并且在大多数情况下,您甚至无法训练您的模型。
为了说明执行数据清理所需的步骤,我使用了一个非常有趣的数据集,由 Open Africa 提供,其中包含 4 个维多利亚湖次区域的历史和预计降雨量和径流。该数据集是根据知识共享许可发布的,可在此链接中获得。我发现这个数据集非常有趣,因为它虽然很小,但它是故意弄脏的,因此它可以用来说明如何执行数据清洗。[0]
所以,让我们继续吧!
文章的结构安排如下:
- Loading the Dataset
- Missing values
- Data standardization
- 初步探索性数据分析。
1 Loading the Dataset
数据集以 Excel 文件的形式提供,因此我通过 read_excel() 函数加载它。要正常工作,此功能需要安装 openpyxl 库。要安装它,您可以运行 pip install openpyxl。
import pandas as pddf = pd.read_excel('source/rainfall.xlsx')
df.head()

数据集未正确加载,因为列名错误。因此,我需要通过跳过前 2 行来再次读取数据集:
df = pd.read_excel('source/rainfall.xlsx', skiprows=2)
df.head()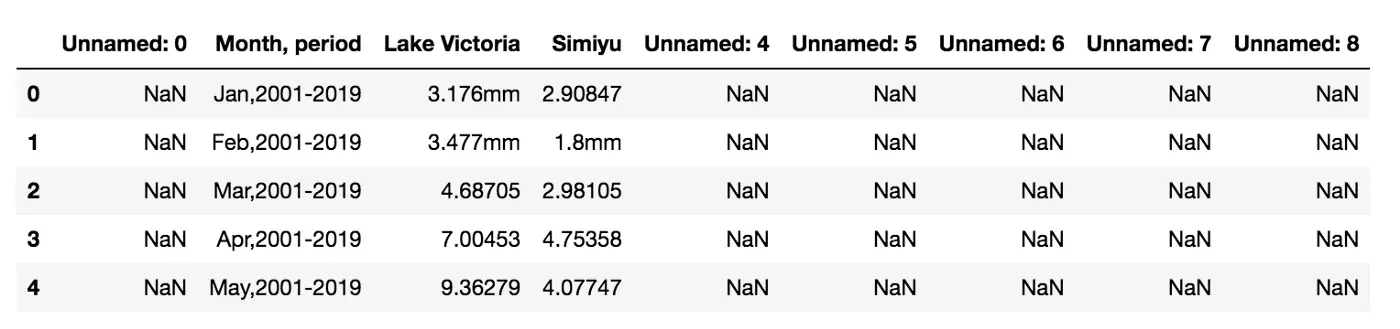
还有一些额外的列,我可以通过 usecols 参数删除它们:
df = pd.read_excel('source/rainfall.xlsx', skiprows=2, usecols='B:D')
df.head(20)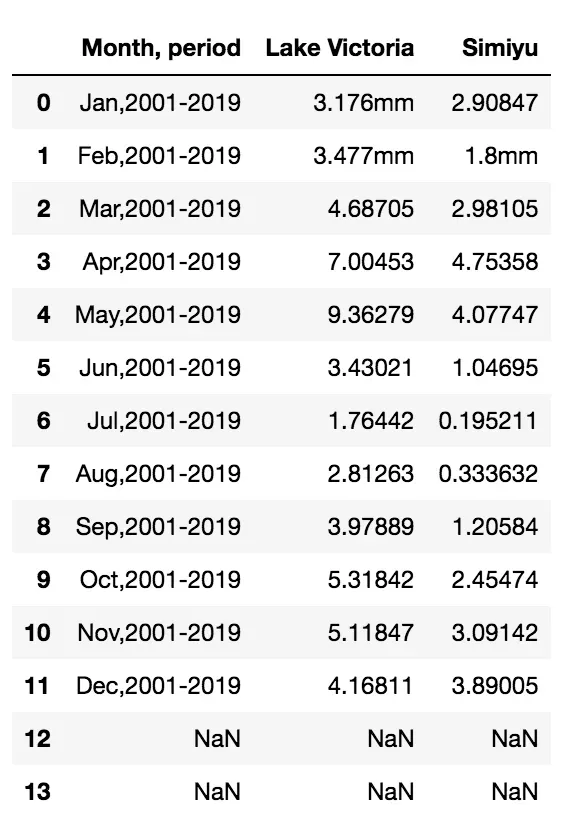
2 Missing values
有两行完全是空的。我可以通过 dropna() 函数删除它们:
df.dropna(inplace=True, axis=0)
df.head(20)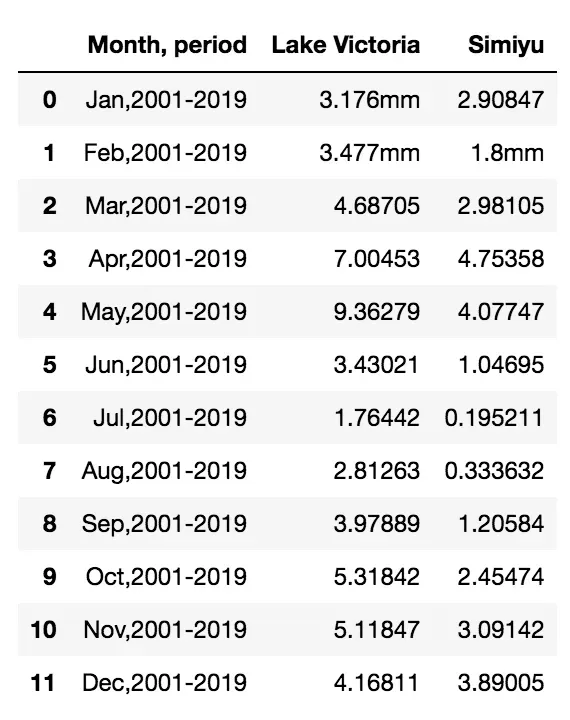
3 Data standardization
第一列包含两列。我使用 split() 函数拆分它们。
splitted_columns = df['Month, period'].str.split(',',expand=True)
splitted_columns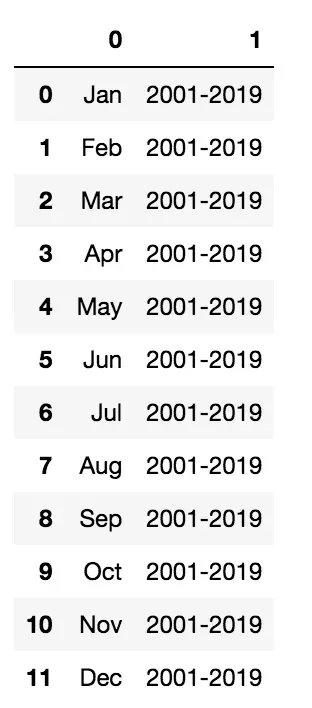
现在我将每个新列分配给原始数据框中的一个新列:
df['Month'] = splitted_columns[0]
df['Period'] = splitted_columns[1]
df.head(15)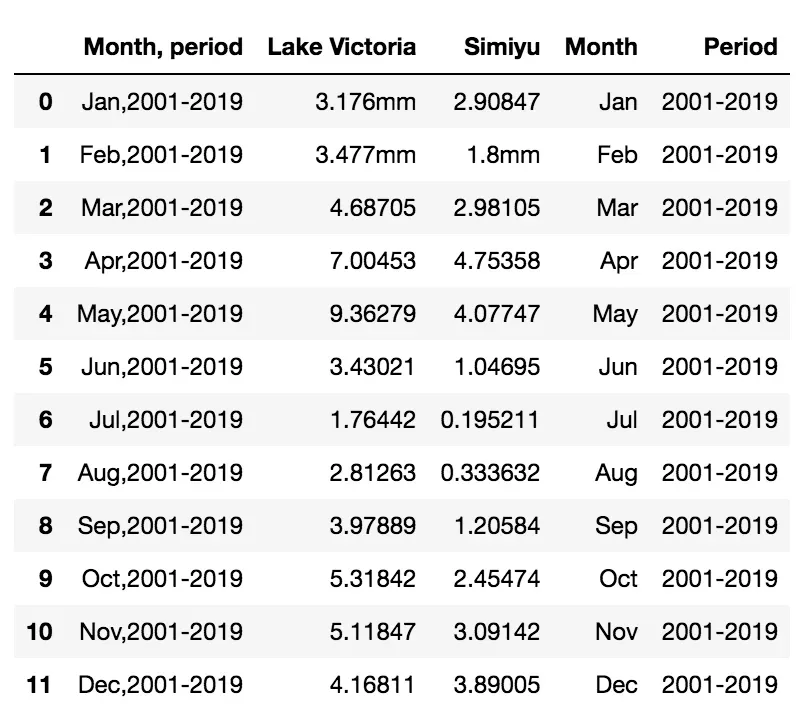
我删除了 Month,period 列:
df.drop('Month, period', axis=1, inplace=True)
df.head(15)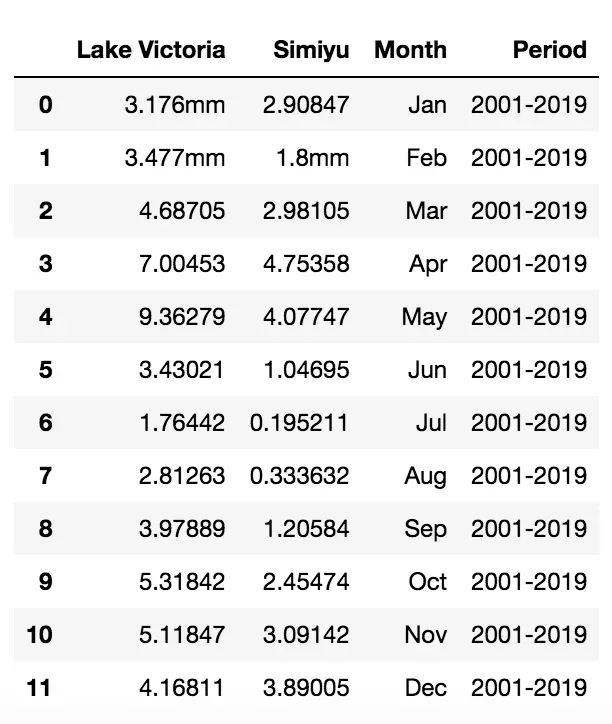
有些列包含字符串 mm,所以我定义了一个函数,它消除了它。
def remove_mm(x):
if type(x) is str:
return x.replace('mm', '')
else:
return x我将前面的函数应用于维多利亚湖和西米玉列:
df['Lake Victoria'] = df['Lake Victoria'].apply(lambda x: remove_mm(x))
df['Simiyu'] = df['Simiyu'].apply(lambda x: remove_mm(x))
df.head(20)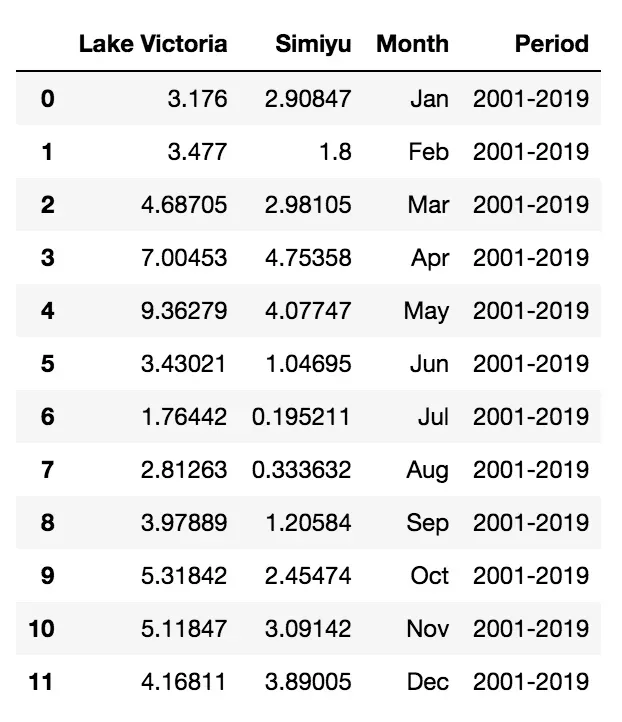
我描述了每列的类型
df.dtypes
维多利亚湖和思米峪柱应该是浮动的。所以我将它们转换为浮动:
df["Lake Victoria"] = pd.to_numeric(df["Lake Victoria"])
df["Simiyu"] = pd.to_numeric(df["Simiyu"])
df.dtypes
4 初步探索性数据分析
为了执行探索性数据分析 (EDA),我使用了 pandas 分析库。我可以按如下方式安装它:
pip install pandas-profiling然后,我用它来构建一个报告:
from pandas_profiling import ProfileReportprofile = ProfileReport(df, title="rainfall")
profile.to_file("rainfall.html")
该库构建一个 HTML 文件,其中包含每列的所有统计信息,并计算每对数字列之间的相关性。下图显示了生成报告的示例:
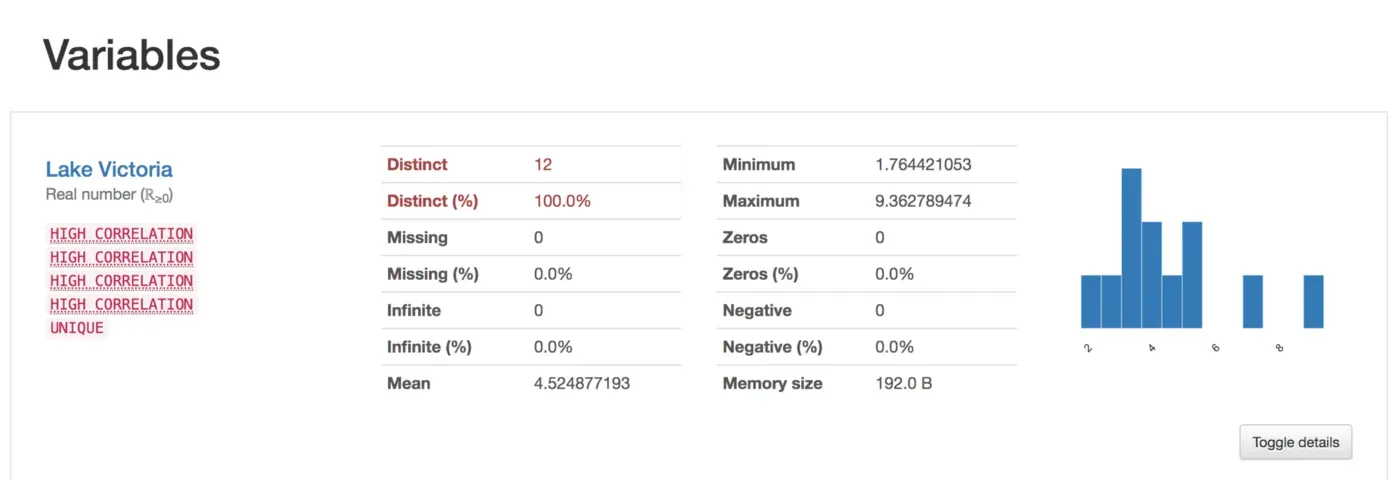
Summary
恭喜!您刚刚在 Python Pandas 中清理了您的第一个数据集!这个过程简单快捷!
您可以从我的 Github 存储库下载本文中使用的代码。[0]
如果你已经读了这么多,对我来说今天已经很多了。谢谢!您可以在此链接上阅读我的热门文章。[0]
Related Articles
你知道 scikit-learn 也提供数据清洗的功能吗?
阅读本文以了解如何处理 scikit-learn 中的缺失值。[0]
文章出处登录后可见!