原文链接:http://tecdat.cn/?p=26624
原文出处:拓端数据部落公众号
matlab软件在拟合数据时使用最小二乘法。拟合需要一个参数模型,该模型将因变量数据与具有一个或多个系数的预测数据相关联。拟合过程的结果是模型系数的估计。
为了获得系数估计,最小二乘法最小化残差的平方和。第i个数据点ri的残差定义为观测因变量值yi与拟合因变量值ŷi之间的差值,并标识为与数据相关的误差。
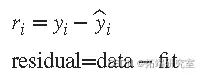
残差的平方和由下式给出
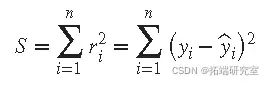
其中 n 是拟合中包含的数据点的数量, S 是误差估计的平方和。支持的最小二乘拟合类型包括:
-
线性最小二乘
-
加权线性最小二乘
-
稳健最小二乘
-
非线性最小二乘
误差分布
在拟合包含随机变化的数据时,通常会对误差做出两个重要假设:
-
误差仅存在于响应数据中,而不存在于预测数据中。
-
误差是随机的,并遵循均值为零且方差为 σ 2 的正态(高斯)分布。
第二个假设通常表示为
![]()
假设误差是正态分布的,因为正态分布通常为许多测量量的分布提供足够的近似值。
线性最小二乘
使用线性最小二乘法将线性模型拟合到数据。线性模型定义为系数为线性的 方程。例如,多项式是线性的,但高斯不是。为了说明线性最小二乘拟合过程,假设您有 n 个可以通过一次多项式建模的数据点。
![]()
为了求解未知系数 p 1 和 p 2 的这个方程,你可以将 S 写成一个由两个未知数组成的 n 个 联立线性方程组。如果 n 大于未知数的数量。
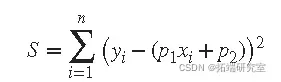
因为最小二乘拟合过程使残差的平方和最小化,所以通过 对每个参数对S 进行微分来确定系数,并将结果设置为零。
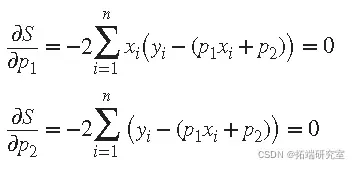
真实参数的估计值通常用 b表示。用b 1 和 b 2 代替 p 1和 p 2,前面的方程变为
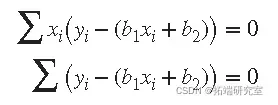
其中总和从 i = 1 到 n。方程 定义为
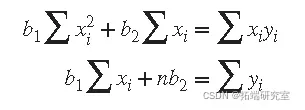
求解 b 1
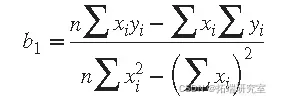
使用 b 1 值求解 b 2
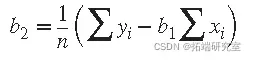
如您所见,估计系数 p 1 和 p 2 只需要一些简单的计算。将此示例扩展到更高次的多项式很简单,尽管有点乏味。所需要的只是添加到模型中的每个线性项的附加正规方程。
在矩阵形式中,线性模型由公式给出
![]()
其中
对于一次多项式,两个未知数中的 n 个 方程用 y、 X和 β 表示为
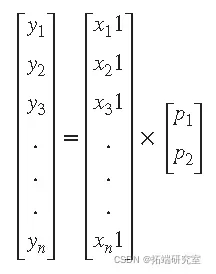
该问题的最小二乘解是一个向量 b,它估计系数 β 的未知向量。正规方程由下式给出
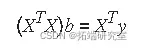
其中 XT 是设计矩阵 X的转置。求解 b,
![]()
您可以将 b插 回模型公式以获取预测的因变量值 ŷ。
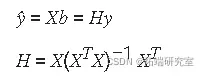
残差由下式给出
![]()
加权最小二乘
通常假设因变量数据具有恒定的方差。如果违反此假设,您的拟合可能会受到低质量数据的过度影响。为了改善拟合,您可以使用加权最小二乘回归,其中在拟合过程中包含一个额外的比例因子(权重)。加权最小二乘回归最小化误差估计
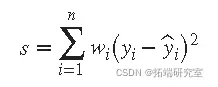
其中 wi 是权重。权重确定每个响应值对最终参数估计的影响程度。与低质量数据点相比,高质量数据点对拟合的影响更大。如果权重已知,或者有理由证明它们遵循特定形式,则建议对数据进行加权。
您通常可以通过拟合数据和绘制残差来确定方差是否不恒定。在下面显示的图中,数据包含各种质量的重复数据,并且假设拟合是正确的。残差图中显示了质量差的数据,残差图具有“漏斗”形状,其中小的预测值在因变量值中产生的散布比大的预测值更大。

稳健最小二乘
通常假设因变量误差服从正态分布,极值很少见。尽管如此,仍然会出现称为异常值的极端值 。
最小二乘拟合的主要缺点是它对异常值的敏感性。异常值对拟合有很大影响,因为对残差进行平方会放大这些极端数据点的影响。为了最大限度地减少异常值的影响,您可以使用稳健的最小二乘回归拟合您的数据。
-
最小绝对残差 (LAR) — LAR 方法找到一条曲线,该曲线使残差的绝对差值(而不是平方差)最小化。因此,极值对拟合的影响较小。
-
Bisquare weights – 此方法最小化加权平方和,其中赋予每个数据点的权重取决于该点与拟合线的距离。线附近的点获得全部权重。离线较远的点会减轻重量。比随机机会预期的距离线更远的点的权重为零。
在大多数情况下,双平方权重方法优于 LAR,因为它同时寻求使用通常的最小二乘法找到适合大部分数据的曲线,并且可以最大限度地减少异常值的影响。
双平方权重的稳健拟合使用迭代重新加权最小二乘算法,并遵循以下过程:
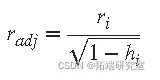
ri 是通常的最小二乘残差, hi 是 通过减少高杠杆 数据点的权重来调整残差的杠杆,这对最小二乘拟合有很大影响。标准化调整残差由下式给出
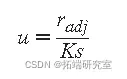
-
K 是等于 4.685 的调谐常数, s是由MAD /0.6745 给出的稳健标准偏差, 其中MAD 是残差的中值绝对偏差。
-
计算鲁棒权重作为 u的函数。双方权重由下式给出
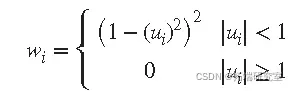
-
请注意,如果您提供自己的回归权重向量,则最终权重是稳健权重和回归权重的乘积。
-
如果拟合收敛,那么你就完成了。否则,通过返回第一步执行拟合过程的下一次迭代。
下图将常规线性拟合与使用双方权重的稳健拟合进行了比较。请注意,稳健拟合遵循大量数据,不受异常值的强烈影响。

非线性最小二乘
使用非线性最小二乘公式将非线性模型拟合到数据。非线性模型定义为系数为非线性的方程,或系数为线性和非线性的组合。例如,高斯、多项式的比率和幂函数都是非线性的。
在矩阵形式中,非线性模型由公式给出
![]()
其中
-
y 是一个 n ×1 响应向量。
-
f 是 β 和 X的函数。
-
β 是一个 m × 1 的系数向量。
-
X 是模型的 n × m 设计矩阵。
-
ε 是一个 n × 1 误差向量。
非线性模型比线性模型更难拟合,因为无法使用简单的矩阵技术估计系数。相反,需要遵循以下步骤的迭代方法:
-
从每个系数的初始估计开始。对于一些非线性模型,提供了一种启发式方法,可以产生合理的起始值。对于其他模型,提供了区间 [0,1] 上的随机值。
-
生成当前系数集的拟合曲线。拟合因变量值 ŷ 由下式给出
ŷ = f ( X , b )
并且涉及计算 f ( X,b ) 的雅可比行列式 , 它被定义为关于系数的偏导数矩阵。
-
调整系数并确定拟合是否有所改善。调整的方向和幅度取决于拟合算法。
-
通过返回到步骤 2 来迭代该过程,直到拟合达到指定的收敛标准。
您可以对非线性模型使用权重和稳健拟合,并相应地修改拟合过程。
稳健拟合示例
此示例显示如何比较排除异常值和稳健拟合的效果。该示例显示了如何从模型中排除大于 1.5 个标准差的任意距离处的异常值。然后,这些步骤将移除异常值与指定稳健拟合进行比较,从而降低异常值的权重。
创建基准正弦信号:
y0 = sin(xata);向具有非恒定方差的信号添加噪声。
ydta = y0 + gnise + snise;用基准正弦模型拟合噪声数据,并指定 3 个输出参数以获得包括残差在内的拟合信息。
f = ftye('a*sin(b*x)');
[fi1,gof,fifo] = fit(xdat检查 fitinfo 结构中的信息。

从 fitinfo 结构中获取残差。
rsiduls = fno.rsis;将“异常值”识别为距基准模型大于 1.5 标准差的任意距离处的点,并在排除异常值的情况下重新拟合数据。
I = abs( resls) > 1.5 * std( esda
outlrs = exclaa(xaa,dta,'ind
fit2 = fit(xdta,yda将排除异常值的效果与在稳健拟合中给予它们较低的双方权重的效果进行比较。
绘制数据、异常值和拟合结果。指定一个信息图例。
plot(fit1,'r-',xda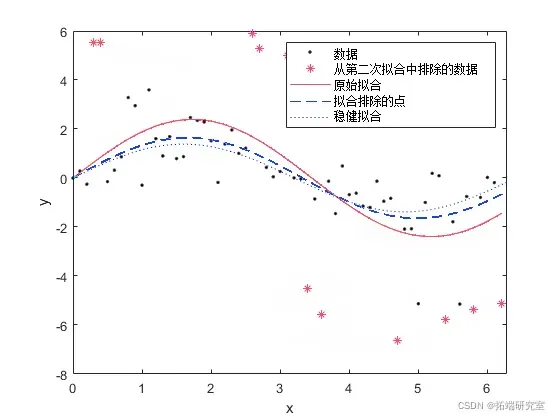
绘制考虑异常值的两个拟合的残差:
figure
plot(fit2,xdata,ydat
hold on
plot(fit3,xdata,ydat
hold off

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
5.R语言回归中的Hosmer-Lemeshow拟合优度检验
文章出处登录后可见!