


CubeSLAM: Monocular 3-D Object SLAM
Shichao Yang and Sebastian Scherer
摘要
In this paper, we present a method for single image three-dimensional (3-D) cuboid object detection and multiview object simultaneous localization and mapping in both static and dynamic environments, and demonstrate that the two parts can improve each other. First, for single image object detection, we generate high-quality cuboid proposals from two-dimensional (2-D) bounding boxes and vanishing points sampling. The proposals are further scored and selected based on the alignment with image edges. Second, multiview bundle adjustment with new object measurements is proposed to jointly optimize poses of cameras, objects, and points. Objects can provide long-range geometric and scale constraints to improve camera pose estimation and reduce monocular drift. Instead of treating dynamic regions as outliers, we utilize object representation and motion model constraints to improve the camera pose estimation. The 3-D detection experiments on SUN RGBD and KITTI show better accuracy and robustness over existing approaches. On the public TUM, KITTI odometry and our own collected datasets, our SLAM method achieves the state-of-the-art monocular camera pose estimation and at the same time, improves the 3-D object detection accuracy.
引言
Object SLAM:作为SLAM路标的目标也可以提供额外的语义和几何约束来提高相机的位姿估计。本文提出了CubeSLAM,联合2D和3D目标检测和SLAM位姿估计,在静态和动态环境中,如下图所示。
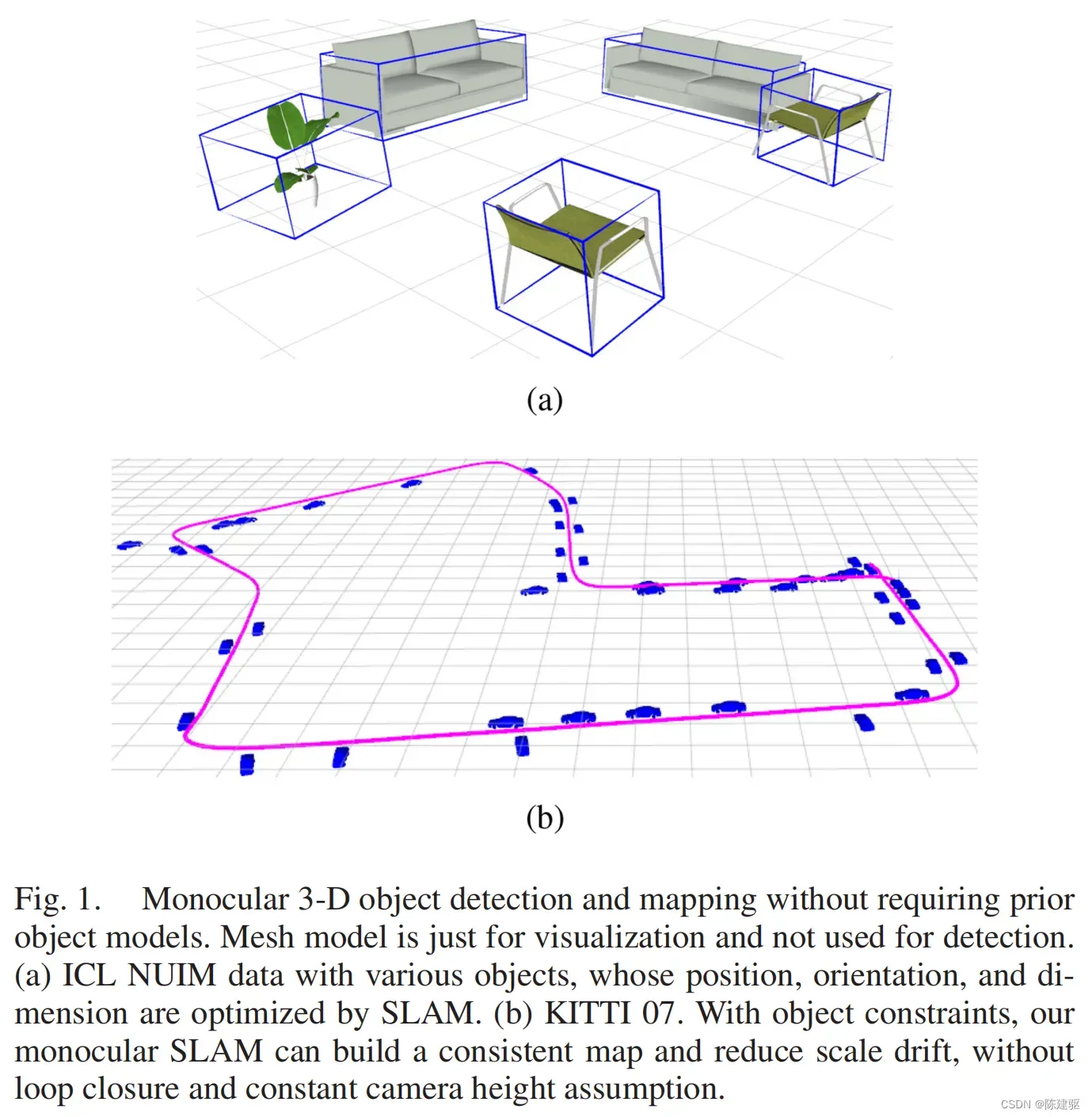

首先假设3D框在投影后会紧紧的落在2D包围框上。给定一个2D框,通过消失点(VP)采样,生成很多3D框proposal。然后通过多视图BA对所选的3D框proposal进行点和相机的优化。目标的作用两个:为BA提供几何和尺度约束;为难以三角化的点提供初始深度信息。SLAM中估计的相机位姿也用于单视角目标检测。最后,在动态情况下,基于动态点观测和运动模型约束共同优化相机和目标的轨迹,而不是将运动目标作为离群值。论文的贡献:
- An efficient, accurate, and robust single image 3-D cuboid detection approach without requiring prior object models.
- An object SLAM method with novel measurements between cameras, objects, and points, that achieves better pose estimation on many datasets, including KITTI benchmark.
- Results demonstrating that object detection and SLAM benefit each other.
- A method to utilize moving objects to improve pose estimation in dynamic scenarios.
3D目标检测
A. 3D Box Proposal Generation
(1) 原理
而不是在3D空间中随机的采样,本文利用检测得到的2D包围框生成3D proposal。一个3D包围框可以由9个参数表示:3DoF的位置

已知相机的内参
VP是平行线投影到投影图后的交点。一个3D包围框有3个正交轴,根据物体关于相机坐标系的旋转矩阵和相机内参矩阵K,可以得到3个VP:
其中
(2) 从VP获得2D角点
这里描述如何跟踪VP来获得8个3D框投影到图像的角点。由于最多可以同时观测到3D包围框的3面,可以根据图2所示的可观测面数量将3D框构型分为三个常见类别。每种构型都可以是左右对称的。
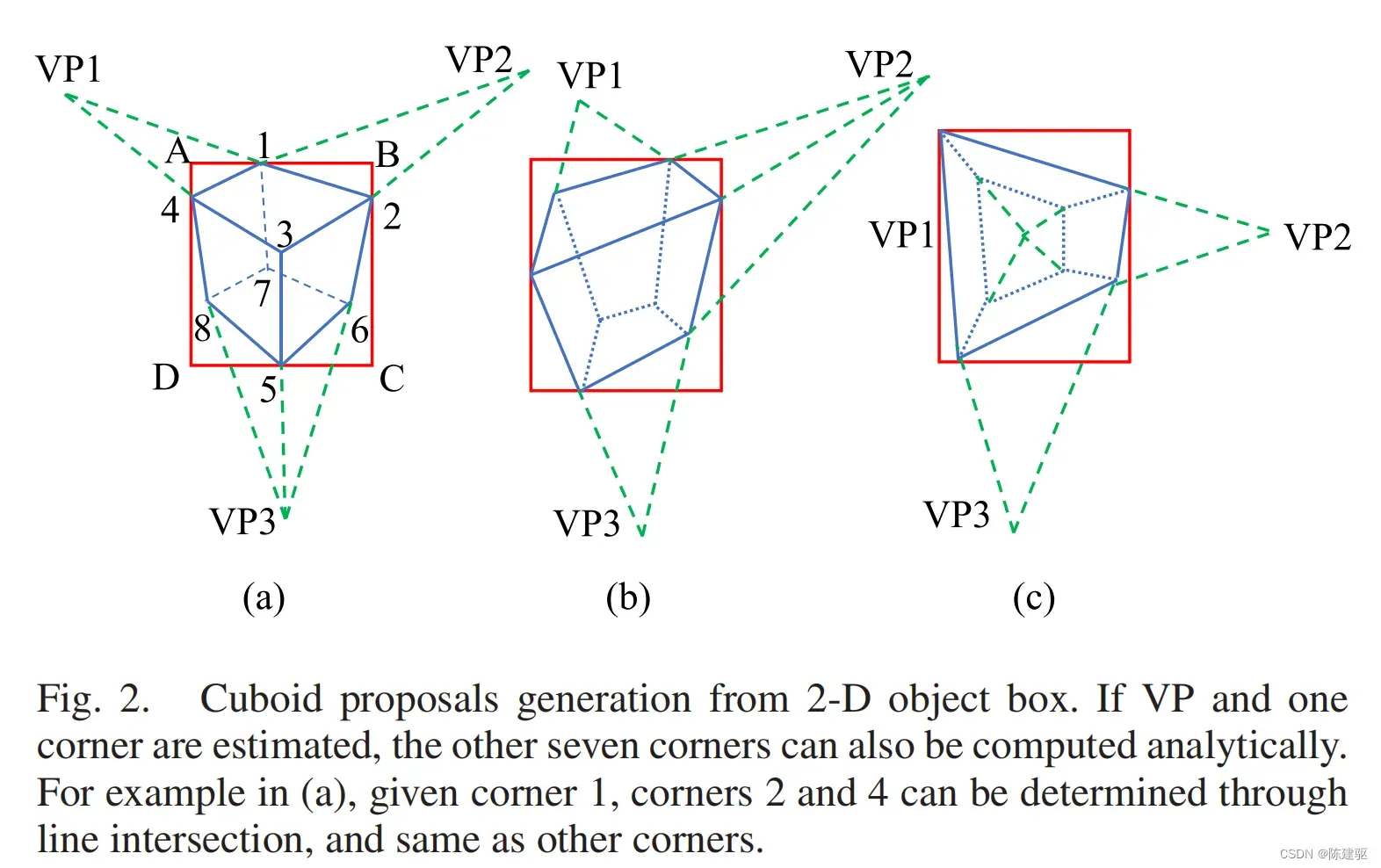

以 图2(a) 为例。假设3个VP点和位于2D框顶部的角点
其它点同理。
(3) 从2D角点中获得3D Box 位姿
在获得2D图像上的3D框角点之后,需要估计3D框的3D角点和位姿。将3D划分为两种物体:
任意位姿的物体:
由于单目尺度的不确定性,使用PnP求解器求解3D框的3D位置和尺度因子。从数学上说,3D框的8个角点在物体坐标系的坐标为
其中
地面上的物体:
对于在地面上物体,可以简化上面的过程。在地面上建立世界坐标系,然后物体的roll/pitch角为零。与前一节类似,从VP得到8个二维角。不使用(2)中PnP求解器,而是直接将地面上的角点像素坐标反投影到3D地平面上,然后计算其他角点,形成一个3D框。这种方法非常有效,并具有解析表达式。
3D地面可以表示为
这个尺度通过在投影过程中的相机高度确定。
(4) 采样VP
根据前两节的分析,box估计的问题变成了如何得到3个VP和一个顶部的2d角,在得到VP之后,可以使用Section III-A2来计算2d角,然后使用Section III-A3来计算3d框。
从(1)中,VP由目标旋转矩阵
对于一般的目标,需要采样完整旋转矩阵R;而对于地面上的目标,相机的roll/pitch角加上采样物体的yaw角,即可计算
在SUN RGBD或KITTI等数据集中,已经提供了相机的roll/pitch角。对于多视角视频数据,使用SLAM来估计相机位姿。从而大大减小了采样空间,提高了采样精度。在本文的实验中只考虑了地面上的物体。
B. Proposal Scoring
在采样得到很多3D proposals后,定义一个代价函数来评估这些proposal。现在有很多不同的评分方法,比如基于语义分割的、边缘距离的、HOG特征点。这里使用对齐图像边缘特征来定义代价函数。由于VP和鲁棒边缘滤波的限制,这种方法最适合于“有清晰边缘的方框” 目标。
首先记图像为
其中
(1) 距离误差
距离误差
(2) 角度对齐误差
角度对齐误差 $\phi_{\text{angle}}(O,I) $: 距离误差对false positive边缘(如物体表面纹理)很敏感。因此,这里检测较长的线段(如图3中的绿色线所示),并测量其角度是否与VP一致。


基于点-线支持关系,这些线首先与三个VP中的一个相关联。然后对于每个
(3) 形状误差 
前两个误差仅在2D图像空间上计算,然而相同的2D角点可能会生成不同的3D框。42
其中
Object SLAM
将前面单图像3D目标检测拓展到多视图object-SLAM,来优化物体的位姿和相机的位姿。这一块基于ORB SLAM2。ORB SLAM2包括用于相机跟踪的前端和用于BA的后端。这里主要修改了其BA部分,将物体、点、相机位姿一起进行优化。
A. BA的形式
BA是联合优化各种地图组件的过程,例如相机的位姿和点。这里用到了点,因为光物体不能完全约束相机的位姿。记相机位姿的集合为
其中
object SLAM的框架如下:
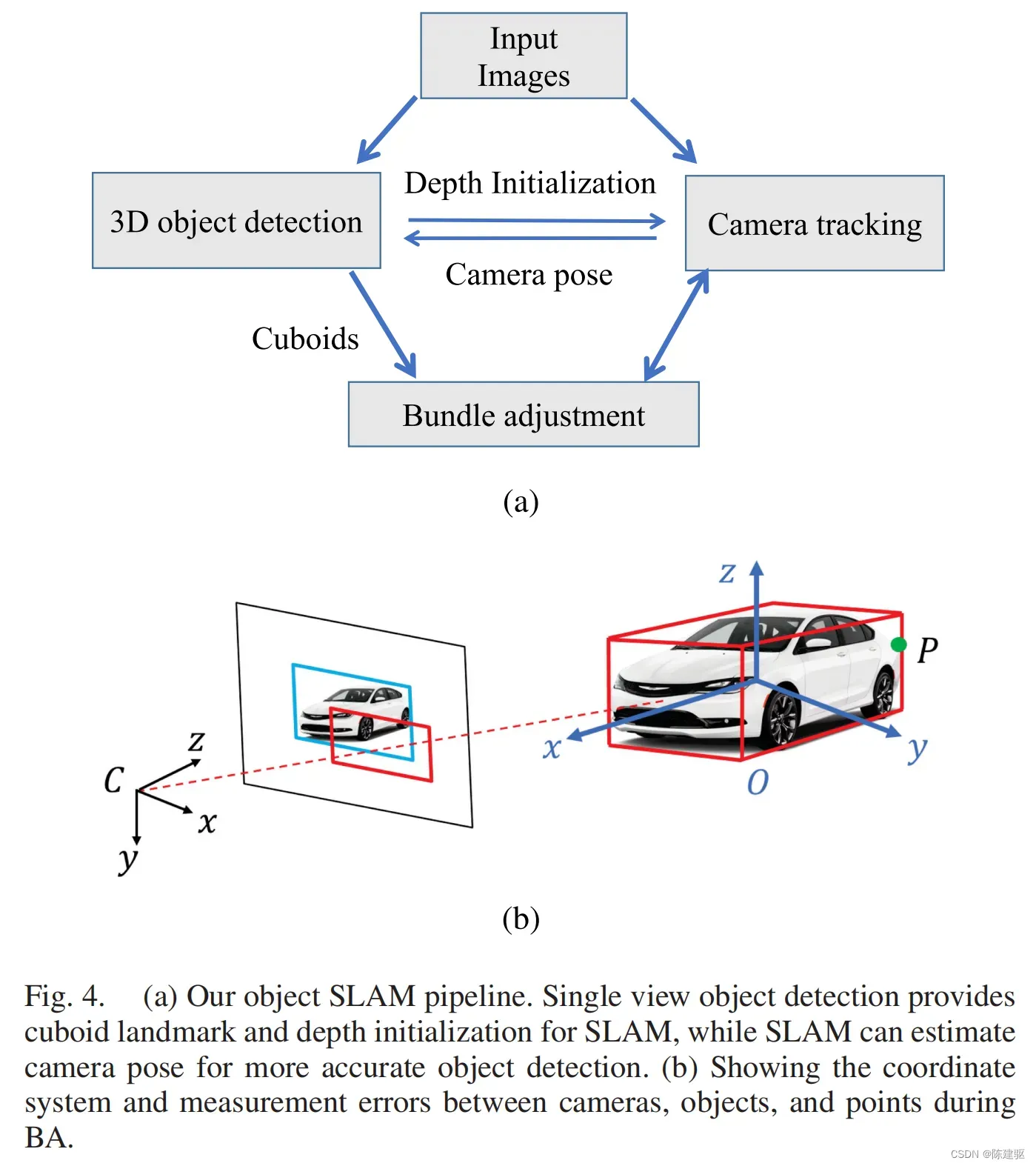

记号
相机位姿通过
3D包围框可以通过9自由度的参数表示:
B. 测量误差
(1) Camera-Object测量
在物体和相机之间使用两种测量误差:
(a) 3D测量
当3D目标检测精确时使用的方法。从单图像目标检测中检测到的物体位姿
其中
需要注意的是,如果没有先验的物体模型,基于图像的包围框检测无法区分物体的正面或背面。例如,即使旋转物体坐标系90◦和交换长度与宽度,也能表示相同的包围框。因此,需要沿着高度方向旋转
(b) 2D测量
对于2D测量,将gt物体路标投影到图像平面,得到2D gt 包围框,然后将其与检测到的2D包围框相比较。如下图所示:
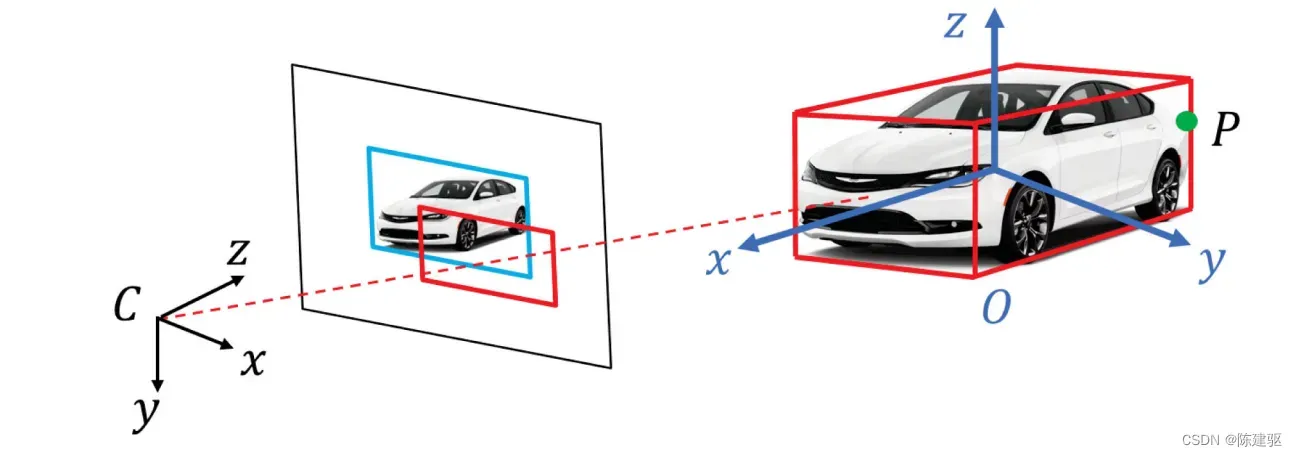

具体实现上,将3D包围框的8个角点投影到图像,然后找到这些投影点的最大和最小值,组成一个矩形:
其中
这个测量误差与3D误差 (8) 相比,不确定性更小,这是因为2D物体检测比3D检测更精确。这个投影过程类似于重投影误差。然而,由于许多不同的3-D包围框可以投影到同一个2D矩形上,因此需要更多的观测来完全约束相机位姿和3D包围框,因此投影后也会丢失信息。
由于复杂的检测过程,无法直接建模和估计误差协方差矩阵
(2) Object-Point测量
点和物体互相约束。如果点
使用
(3) Camera-Point测量
使用基于特征点SLAM中标准的3D点重投影误差:
其中
C. 数据关联
跨帧数据关联是SLAM的另一个重要组成部分。与点匹配相比,目标关联更容易,因为它包含了更多的纹理信息,可以使用许多二维目标跟踪或模板匹配方法。甚至在一些简单的场景中,可以直接使用2D框的IoU来进行匹配。但是,如图5所示,当存在严重的目标遮挡时,这些方法都不具有鲁棒性。此外,当前SLAM优化中需要检测和去除动态目标,但标准的目标跟踪方法无法区分其是否是静态的,除非使用特定的运动分割。
因此,本文提出了一种基于特征点匹配的物体关联方法。对于基于点的SLAM方法,通过描述子匹配和对极几何检查,可以有效地匹配不同视图中的特征点。因此,如果在二维物体包围框中至少观测到两帧的点,且这些点到3D框中心的3D距离小于 1 m,首先将特征点与它们对应的目标关联起来。例如在图5中,特征点与其关联目标具有相同的颜色。注意,在(11)中的BA计算目标点测量误差时,也使用了这种目标点关联。最后,在不同帧中,如果两个目标之间共享的特征点数量最多,且数量也超过一定的阈值(默认为10个),则对两个目标进行匹配。
根据实验,这种方法对于宽基线匹配、重复目标、遮挡的效果很好。由于运动目标的动态特征点不能满足极线约束,因此将其丢弃。因此,将关联特征点较少的目标视为动态目标,如图5中的前青色汽车。


动态SLAM
上一节处理的是静态物体SLAM,而在本节提出联合相机位姿和动态物体轨迹。这里对目标做了一些假设,以减少未知量的数量并使问题可解决。常用的两种假设是:目标物体是刚体,并且遵循物理上可行的运动模型。
刚体假设表明,一个点在其关联物体上的位置不随时间而改变。这可以通过标准的3D地图点重投影误差来优化它的位置。
对于运动模型,最简单的形式是匀速恒速运动模型。对于某些特定的目标,如车辆,额外地约束遵循非完整的车轮模型(有一些侧滑)。
A. 记号
对于动态物体
B. SLAM优化
动态物体估计的因子图如图6所示。蓝色的节点是SLAM的静态元素,红色的节点是动态物体、点和运动速度,绿色的节点表示测量因子,包括(10)中的camera-object因子,(14)中的object-velocity因子,(15)中的point-camera-object因子。通过这些因子,相机位姿也可以通过动态元素来约束。
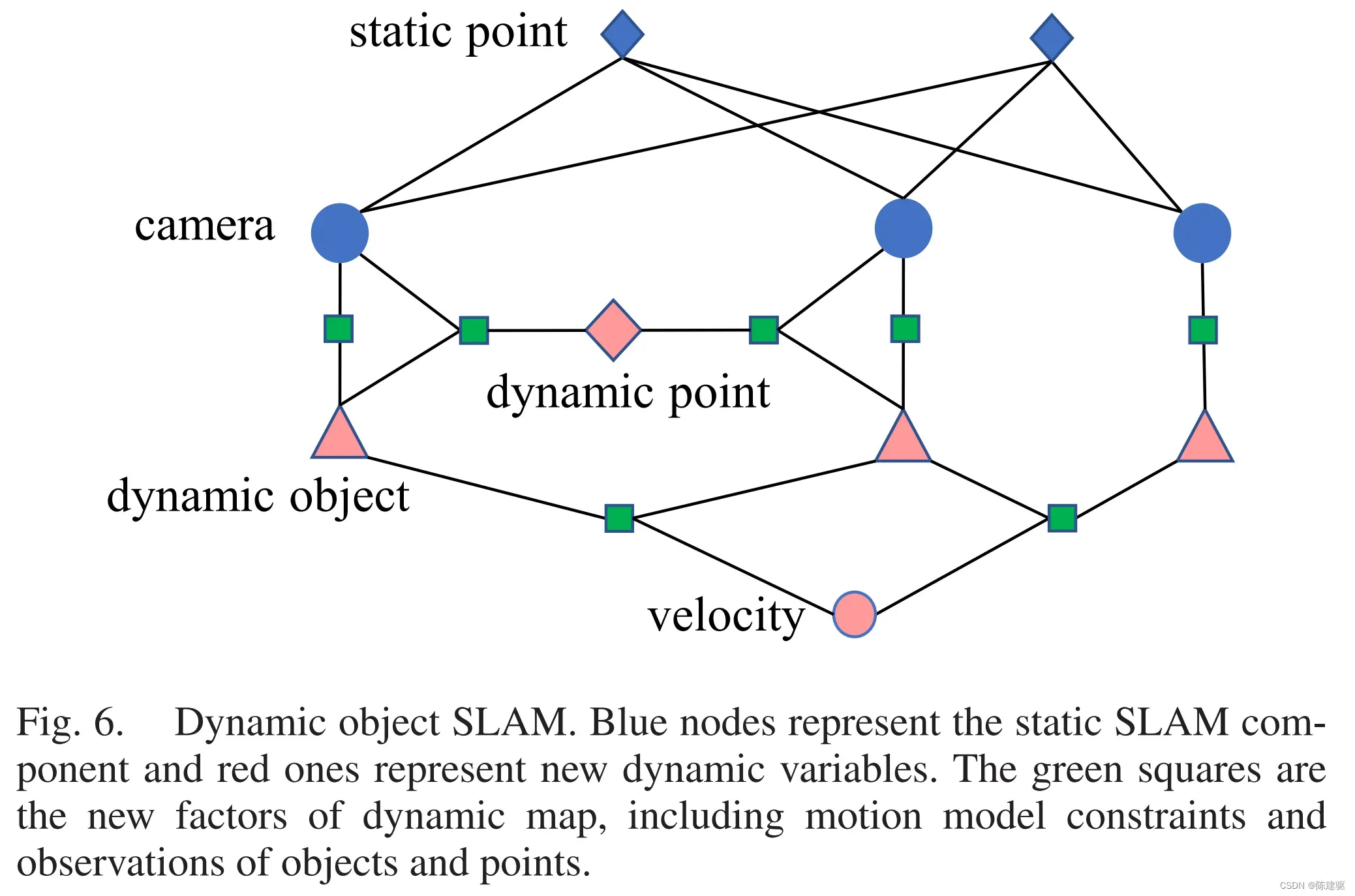

(1)物体运动模型
通用的3D物体运动可由位姿变换矩阵
其中 L 是前后轮中心之间的距离。注意,这个模型要求
(2) 动态点观测
如上面所说的那样,动态点被固定在其所在的物体上,因此它首先需要被转换到世界坐标系,然后投影到相机坐标系。假设第i个物体的第k个点的局部位置是
其中
C. 动态数据关联
通过实验,发现前面的静态环境关联方法不适合动态情况,因为动态点特征匹配存在困难。跟踪特征点的典型方法是预测其投影位置,搜索其描述子的附近的特征,然后检查对极几何约束。然而,在单目动态情况下,很难准确预测物体和点的运动,当物体运动不准确时,对极几何也不准确。
因此,这里对点的数据关联和物体的数据关联设计了不同的方法。特征点通过2D KLT稀疏光流来直接跟踪,这不需要点的3D位置。像素跟踪之后,动态特征的3D点通过三角化得到,这种三角化考虑了物体的运动。
数学上说,假设两帧的投影矩阵为
将
当像素位移较大时,例如,当另一辆车接近并朝向摄像机时,KLT跟踪仍然可能失败。因此,对于动态物体跟踪,不使用前面object slam中提到的特征点匹配方法,而是使用 KCF目标跟踪算法来跟踪。跟踪目标的二维包围框并根据前一帧预测其位置,然后与当前帧中重叠比例最大的检测到的包围框进行匹配。
实现
A. 目标检测
对于二维物体检测,对于室内场景,使用概率阈值为0.25的YOLO算法,而对于室外场景(KITTI),使用概率阈值为0.5MS-CNN。两者都在GPU上实时运行。
如果一个精确的相机位姿是已知的,例如,在SUN RGBD数据集中,只需要采样物体的yaw角来计算VPs。如IV-B1节所述,在yaw角90◦范围内的物体的15个采样被生成为可以旋转的包围框。
然后在2-D包围框的上边缘上采样10个点,作为p1点。注意,并不是所有的采样都能生成有效的3D框proposal,因为一些框的角点可能位于2D框之外。
在没有gt相机位姿提供的场景中,在初始估计角度的20范围内采样相机的滚动/俯仰。对于没有先验信息的单一图像,简单地估计相机是平行于地面的。对于多视图场景,SLAM用于估计相机位姿。本方法的一个优点是,它不需要大量的训练数据,因为我们只需要调整(4)中的两个成本权值。它也可以实时运行,包括二维目标检测和边缘检测。
B. Object SLAM
整个SLAM算法的流程下图所示。系统是基于ORB-SLAM2的,但是没有改变相机跟踪和关键帧创建模块。
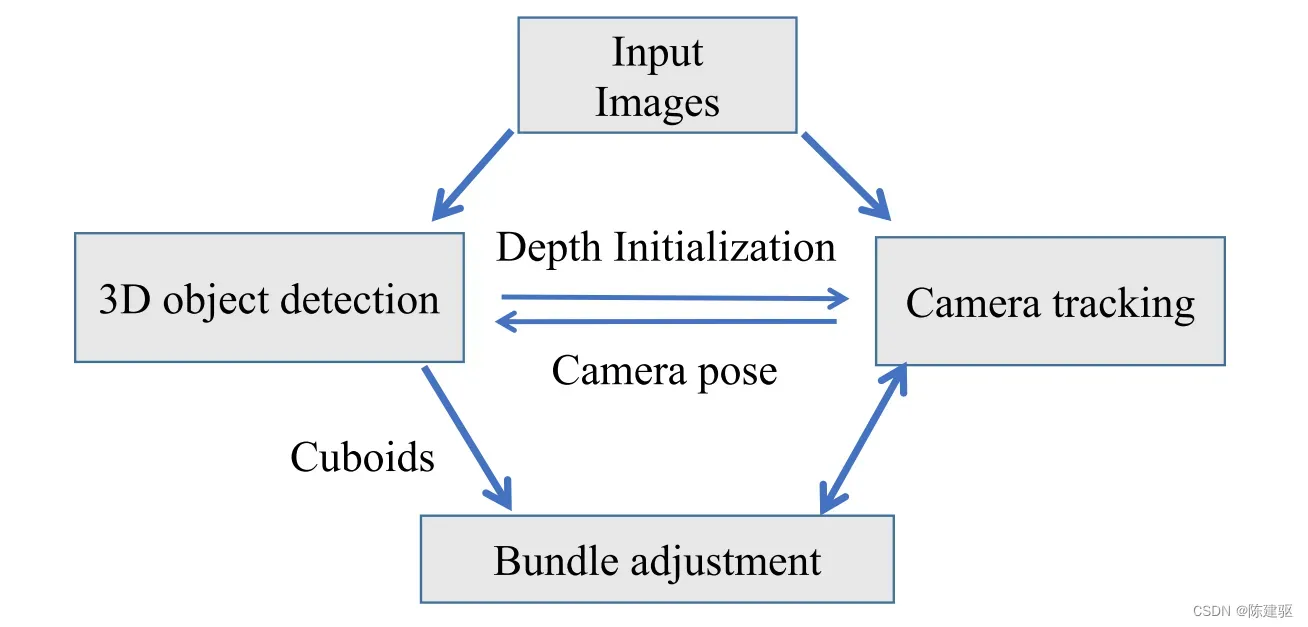

对于新创建的关键帧,检测3D包围框,并进行帧间数据关联,然后与相机的位姿和点执行BA。
对于动态物体,根据不同的任务选择重建或忽略它们。对于双目基线或视差角小于阈值时难以进行三角化的特征点,利用3D包围框对其深度进行初始化。实验证明,这可以在一些具有挑战性的场景中提高鲁棒性,如大的相机旋转。由于目标的数量远远少于点,目标关联和BA优化是实时高效运行的。为了得到单目SLAM的绝对地图尺度,该方法提供了初始帧的相机高度来对地图进行缩放。
object SLAM也可以在没有点的情况下独立工作。在一些特征点较少的具有挑战性的环境中,ORB SLAM无法工作,但该算法仍然可以仅使用 物体-相机测量 来估计相机位姿。
优化过程中存在不同的代价函数,有些代价在像素空间中,如(10),有些代价在欧氏空间中,如(8)和(11),因此有必要调优它们之间的权值。由于3D框检测的不确定度难以分析,因此主要通过检测测量的数量和大小来手工调整物体代价权重,使不同类型的测量贡献大致相同。例如,与点相比,只有很少的物体,但它们在(10)中的重投影误差要比点大得多。从实验来看,物体相机和点相机的测量具有相似的权重。
C. 动态物体
动态物体的实现与上一节类似。恒定运动模型的假设可能不适用于实际数据集,因为物体可能会加速或减速(如图13所示)。通过对gt物体速度的分析,我们发现速度在5 s左右基本保持不变。因此,在SLAM中,运动模型约束只应用于最近5 s的观测。
实验-3D目标检测
A. Proposal Recall
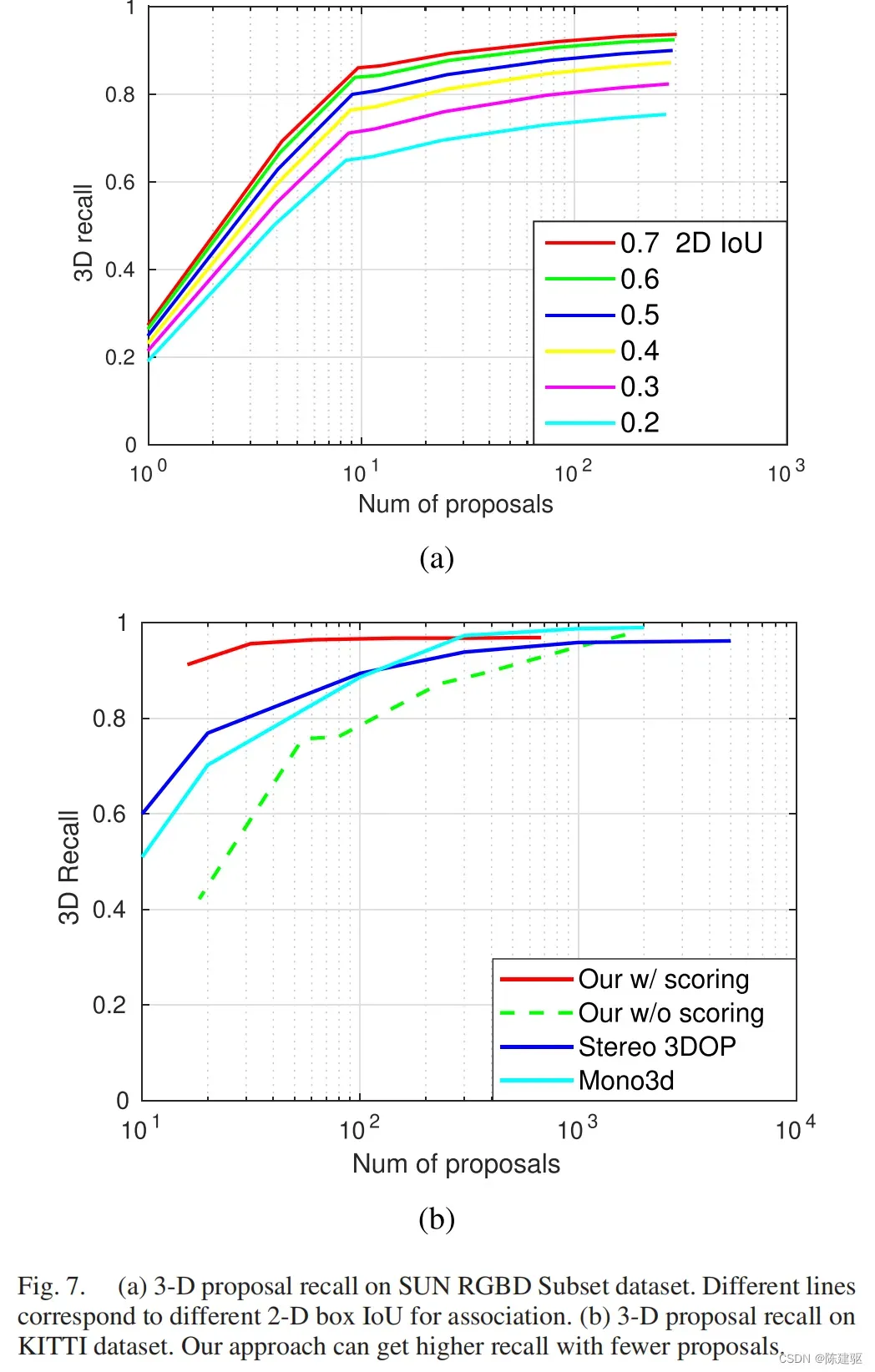

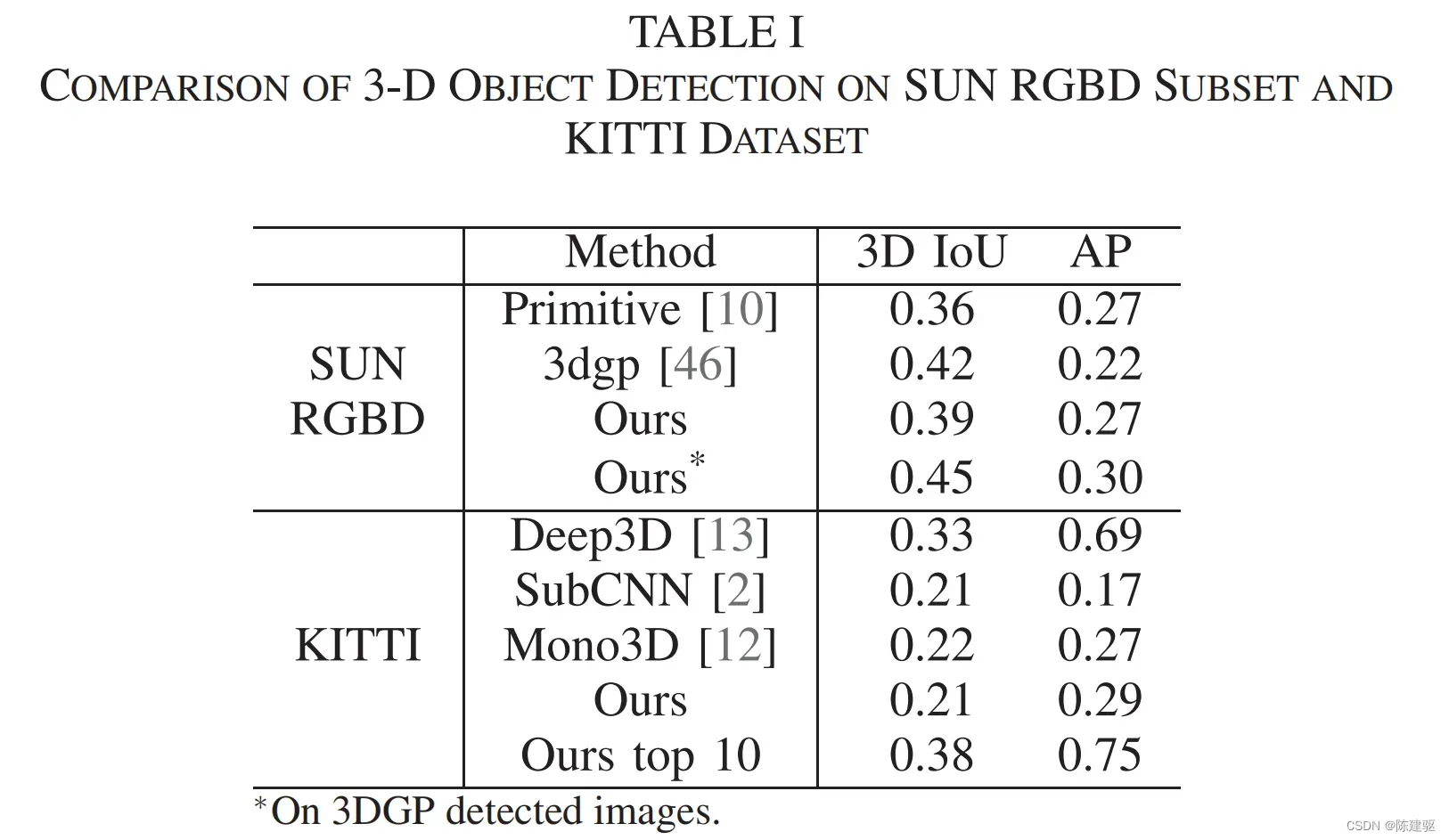
B. Final Detection



实验-Object SLAM
A. TUM RGBD and ICL-NUIM Dataset


B. Collected Chair Dataset


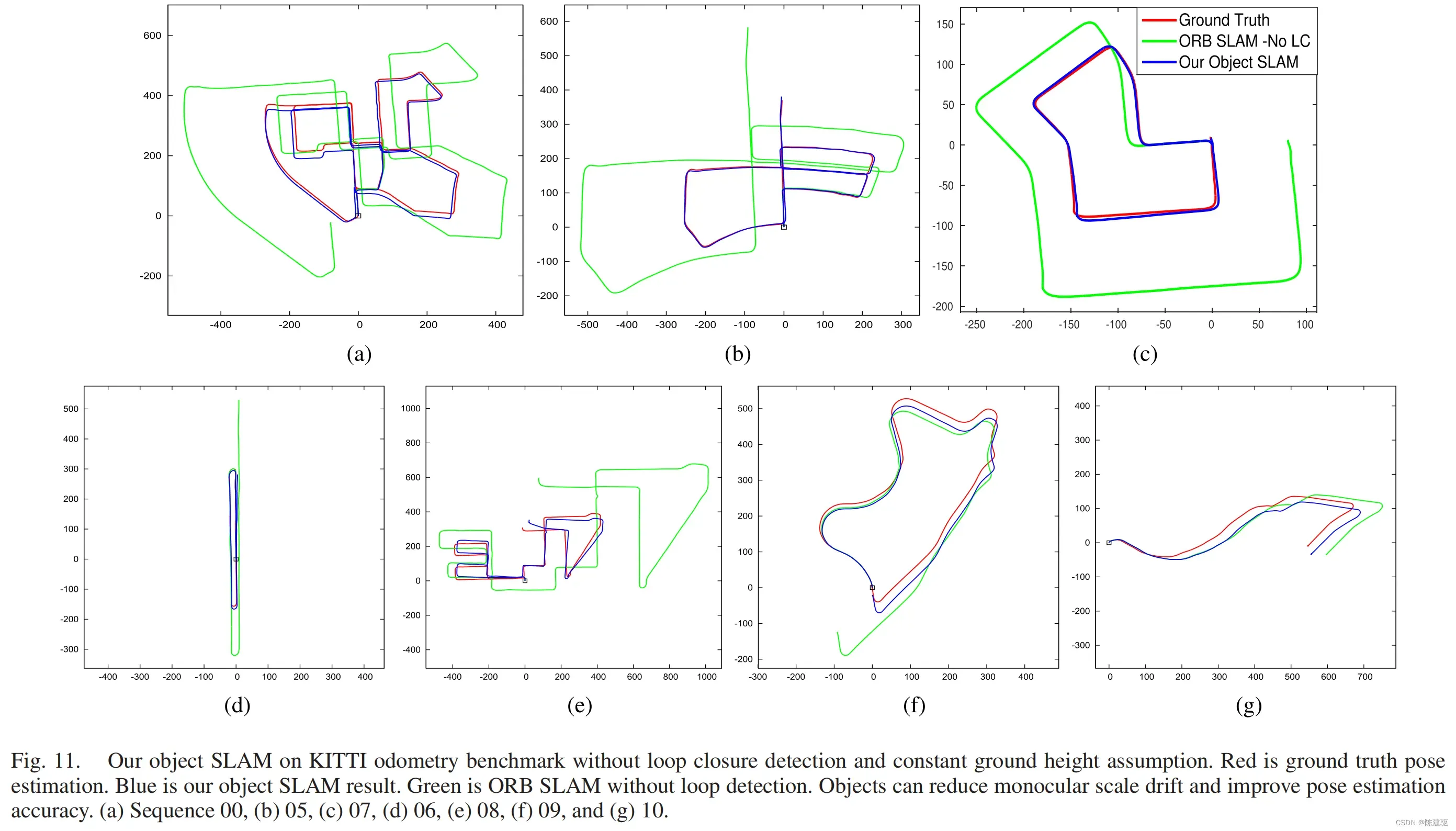
C. KITTI Dataset

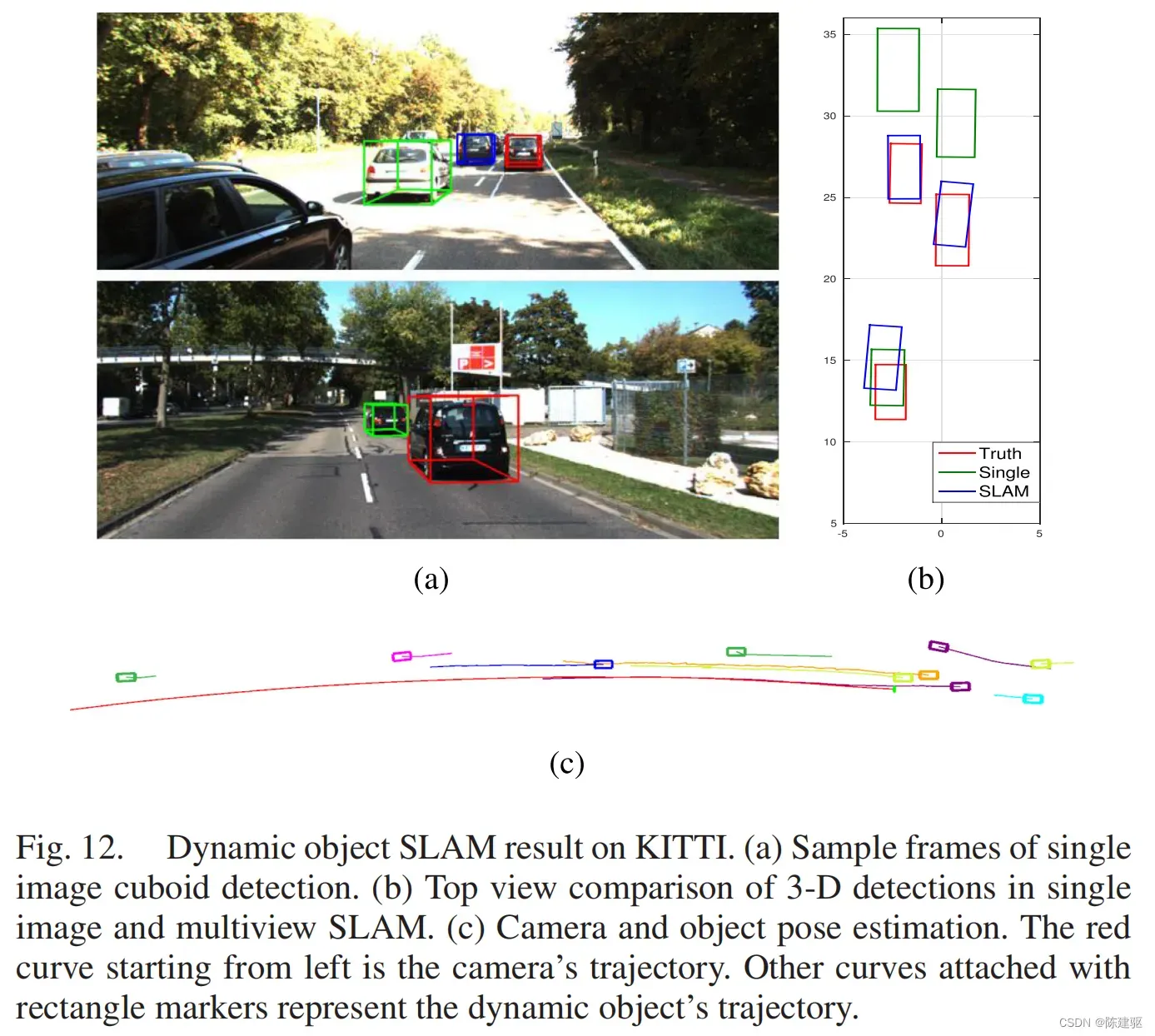
D. Dynamic Object

E. Time Analysis


文章出处登录后可见!