原文链接:https://arxiv.org/abs/2109.05923
论文来源:CVPR 2022
作者团队:南洋理工大学+香港城市大学
Abstract
将弱光图像增强为正常曝光的图像是非常不适定的,即它们之间的映射关系是一对多的。以往的工作基于像素级重建损失和确定性过程,无法捕捉正常曝光图像的复杂条件分布,导致不正确的亮度、残余噪声和伪影。在本文中,我们通过一个正则化流模型来模拟这种一对多关系。一种可逆网络,以微光图像/特征为条件,学习将正常曝光图像的分布映射为高斯分布。这样,可以很好地模拟正常曝光图像的条件分布,以及增强过程,即可逆网络的另一个推理方向相当于受一个损失函数的约束,该损失函数可以更好地描述训练过程中自然图像的流形结构。在现有基准数据集上的实验结果表明,我们的方法获得了更好的定量和定性结果,获得了更好的曝光照明、更少的噪声和伪影,以及更丰富的颜色。
1 Introduction
微光图像增强旨在提高微光图像的可见性,并抑制捕获的噪声和伪影。基于深度学习的方法通过利用大量数据收集的能力,实现了良好的性能。然而,它们中的大多数主要依赖于网络训练中的像素损失函数(例如,l1或l2),该函数在弱光图像和正常曝光图像之间导出确定性映射。这种增强模式遇到两个问题。首先,这种像素级的损失无法在不同的环境中对局部结构进行有效的正则化。由于一幅微光图像可能对应于多幅具有不同亮度的参考图像,这种像素到像素的确定性映射很容易陷入“回归到均值”问题,并获得多幅理想图像的融合结果,这不可避免地会导致不正确的曝光区域和伪影。其次,由于简化了图像分布的像素损失假设,这些损失可能无法描述参考图像和增强图像之间真实的视觉距离,如图1所示,这进一步削弱了网络性能(相同的l1损失,但b图更接近参考图像)。尽管基于GAN的方案可以部分缓解这一问题,但这些方法需要在训练期间进行仔细调整(Wolf等人,2021年),并且可能会过度拟合某些视觉特征或训练数据的属性。

最近,研究人员在计算摄影领域展示了正则化流的有效性。正则化流能够学习比经典像素损失更复杂的条件分布,这可以很好地解决上述两个问题。除了以前基于CNN的模型学习从弱光图像到特定亮度图像的确定性映射之外,正则化流学习将多模态图像流形映射到潜在分布。然后,施加在潜在空间上的损失等价地构成了增强图像流形上的有效约束。它可以更好地描述各种背景下的结构细节,并更好地测量高质量曝光良好图像的视觉距离,这有助于有效调整照明和抑制图像伪影。然而,由于经典的正则化流程偏向于学习图像的图形特性,例如局部像素相关性,因此它可能无法模拟一些全局图像特性,例如颜色饱和度,这可能会在将这些方法应用于微光图像增强问题时影响性能。
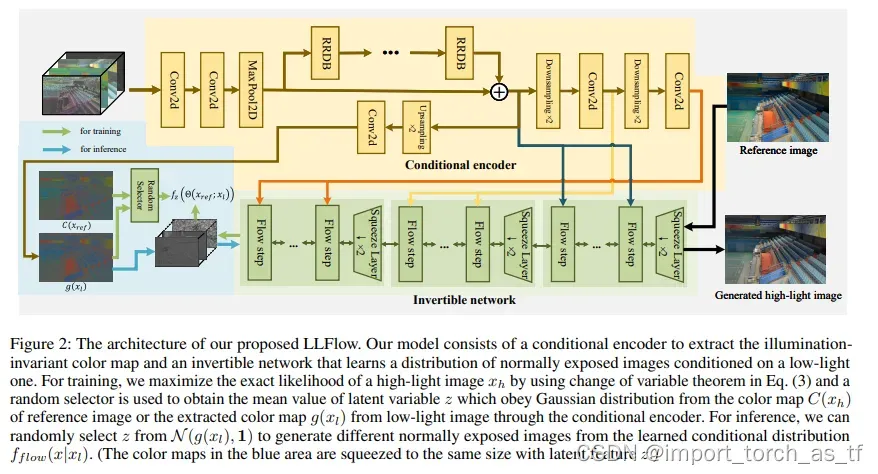
为了解决上述问题,本文提出了LLFlow,这是一种基于流的微光图像增强方法,通过对正常曝光图像上的分布进行建模,准确地了解局部像素相关性和全局图像特性。如图2所示,为了将全局图像信息合并到潜在空间中,而不是使用标准高斯分布作为潜在特征的先验,我们建议使用光照不变颜色映射作为先验分布的平均值。更具体地说,编码器被设计为学习一对一映射以提取颜色映射,该颜色映射可被视为场景的固有属性,且不随照明而改变。同时,我们的框架的另一个组成部分,可逆网络,旨在学习从弱光图像到正常曝光图像分布的一对多映射。因此,我们希望通过我们提出的框架实现更好的微光图像增强性能。总之,贡献可以总结如下。
- 我们提出了一个条件正则化流程来模拟正常曝光图像的条件分布。它等效地对增强图像流形实施有效约束。通过更好地描述结构细节和更好地测量视觉距离,它可以更好地调整照明,并抑制噪声和伪影。
- 我们进一步引入了一个新的模块来提取光照不变的颜色映射,作为弱光图像增强任务的先验,这丰富了饱和度并减少了颜色失真。
- 我们在流行的基准数据集上进行了大量实验,以证明我们提出的框架的有效性。烧蚀研究和相关分析表明了该方法中各模块的合理性。
2 Related works
2.2 Normalizing flow
正则化流程是通过一系列可逆和可微映射(Kobyzev、Prince和Brubaker 2020)将简单概率分布(例如,标准正态分布)转换为更复杂的分布。同时,通过将样本转换回简单分布,可以准确地获得样本的概率密度函数(PDF)值。为了使网络可逆且易于计算,需要仔细设计网络的层,以便容易获得Jacbian矩阵的求逆和行列式,这限制了生成模型的容量。为此,提出了许多强大的转换来增强模型的表达能力。例如,仿射耦合层(Dinh、Krueger和Bengio 2014)、拆分和级联(Dinh、Krueger和Bengio 2014;Dinh、Sohl-Dickstein和Bengio 2016;Kingma和Dhariwal 2018)、置换(Dinh、Krueger和Bengio 2014;Dinh、Sohl-Dickstein和Bengio 2016;Kingma和Dhariwal 2018)和1×1卷积(Kingma和Dhariwal 2018)。最近,为了提高模型的表达能力,研究了条件规范化流。(Tripe和Turner 2018)建议对每种情况使用不同的正常化流程。最近,使用条件仿射耦合层(Ardizzone et al.2019;Winkler et al.2019;Lugmayr et al.2020)与条件特征建立更强的连接,并提高内存和计算资源的效率。得益于规范化流程的发展,其应用范围大大扩大。例如,(Liu等人2019)生成具有特定属性的人脸,(Pumarola等人2020;Yang等人2019)使用条件流生成点云。在超分辨率任务中,(Lugmayr等人,2020年;Winkler等人,2019年;Wolf等人,2021年)基于一个基于条件归一化流的低分辨率输入生成高分辨率图像的分布。此外,在图像去噪(Abdelhamed、Brubaker和Brown 2019;Liu等人2021b)中也使用了条件归一化流来生成额外数据或恢复干净的图像。此外,探讨了标准化流的诱导偏差(Jaini等人,2020年;Kirichenko、Izmailov和Wilson,2020年)。(Kirichenko、Izmailov和Wilson 2020)揭示,标准化流倾向于编码简单的图形结构,这可能有助于抑制微光图像中的噪声。
3 Methodology
在本节中,我们首先介绍以前基于像素级重建损耗的微光增强方法的局限性。然后,介绍了图2中框架的总体范例。最后,分别对我们提出的框架的两个组成部分进行了说明。
3.1 Preliminary
微光图像增强的目标是使用微光图像xl生成正常曝光的高质量图像xh。配对样本(xl,xref)通常通过以下方式最小化重建损失来训练模型Θ:
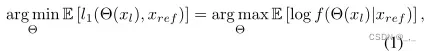
式中,Θ(xl)是由模型生成的正常光图像,f是以参考图像xref为条件的概率密度函数,定义如下:
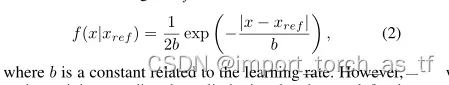
其中b是一个与学习率相关的常数。然而,这种训练范式有一个局限性,即图像的预定义分布(例如,等式2中的分布)不足以区分生成的真实正常曝光图像和具有噪声或伪影的图像,如图1中的示例。
3.2 Framework
为此,我们使用规范化流对正常曝光图像的复杂分布进行建模,以便正常曝光图像的条件PDF可以表示为![]() 。更具体地说,条件规范化流Θ用于将微光图像本身和/或其特征作为输入,并将正常曝光的图像x映射到与x具有相同维度的潜在代码z,即
。更具体地说,条件规范化流Θ用于将微光图像本身和/或其特征作为输入,并将正常曝光的图像x映射到与x具有相同维度的潜在代码z,即![]() 。利用变量变化定理,我们可以得到f flow(x | xl)和fz(z)之间的关系,如下所示:
。利用变量变化定理,我们可以得到f flow(x | xl)和fz(z)之间的关系,如下所示:

为了使模型更好地描述高质量正常曝光图像的特性,我们使用最大似然估计来估计参数Θ。具体来说,我们最小化负对数似然(NLL)而不是L1损失来训练模型
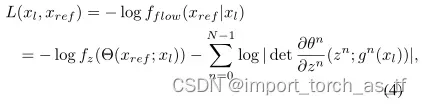
其中可逆网络Θ被分成N个可逆层序列{θ1,θ2,…,θN},hi+1=θi(hi;gi(xl))是层θi的输出,h0=xref,z=hN。gn(xl)是来自编码器g的潜在特征,其具有与层θn兼容的形状。fzi是潜在特征z的PDF。
总之,我们提出的框架包括两个组件:一个编码器g,它将微光图像xl作为输入,输出光照不变颜色贴图g(xl)(可以被视为受Retinex理论启发的反射贴图),以及一个可逆网络,它将正常曝光的图像映射到潜在代码z。以下小节将介绍这两个组件的细节。
Encoder for illumination invariant color map: 为了生成鲁棒且高质量的光照不变颜色贴图,首先对输入图像进行处理以提取有用的特征,然后将提取的特征作为编码器输入的一部分进行连接,该编码器由残余密集块中的残余(RRDB)构建(Wang et al.2018)。由于空间有限,编码器g的详细结构见附录。每个组件的可视化如图3所示,细节如下:

1) Histogram equalized image h(xl): 直方图均衡化是为了提高微光图像的整体对比度。直方图均衡后的图像可以看作是一种更具光照不变性的图像。通过将直方图均衡图像作为网络输入的一部分,网络可以更好地处理过暗或过亮的区域。
2) Color map C(x): 受Retinex理论的启发,我们建议计算图像x的颜色映射,如下所示:
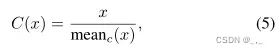
其中MeanC计算RGB通道中每个像素的平均值。图4示出了来自微光图像、参考图像和由编码器g微调的颜色映射之间的比较。正如我们所看到的,颜色贴图C(xl)和C(外部参照)在不同照明下在一定程度上是一致的,因此它们可以被视为与反射贴图类似的表示,在C(xl)中会因强烈的噪声而退化。我们还发现,编码器g可以生成高质量的颜色映射,在一定程度上抑制强噪声,并保留颜色信息。

3) Noise map N(xl): 为了去除C(xl)中的噪声,估计噪声映射N(xl)并将其作为注意映射输入编码器。噪声图N(xl)估计如下:

Invertible network: 与编码器学习一对一映射以提取照明不变颜色映射不同,可逆网络的目标是学习一对多关系,因为同一场景中的照明可能不同。我们的可逆网络由三个层次组成,每个层次上有一个挤压层和12个flow step。有关该体系结构的更多详细信息,请参见附录。
根据我们的假设,标准化流旨在学习以微光图像/照明不变颜色贴图为条件的正常曝光图像的条件分布,标准化流应该在g(xl)和C(xref)上都能很好地工作,因为这两个贴图预期是相似的。为此,我们以以下方式训练整个框架(编码器和可逆网络):

其中p是一个超参数,我们在所有实验中将p设置为0.2。如图4所示,即使没有像素重建损失的帮助,编码器g也可以学习与参考图像相似的颜色映射。
为了使用微光图像生成正常曝光的图像,微光图像首先通过编码器来提取颜色映射g(xl),然后使用编码器的潜在特征作为可逆网络的条件。对于z的抽样策略,可以从分布N(g(xL),1)中随机选择一批z来获得不同的输出,然后计算生成的正常曝光图像的平均值,以获得更好的性能。为了加快推理速度,我们直接选择g(xl)作为输入z,实证发现它可以获得足够好的结果。因此,对于所有实验,如果没有指定,我们只使用平均值g(xl)作为条件规范化流的潜在特征z。
4 Experiments
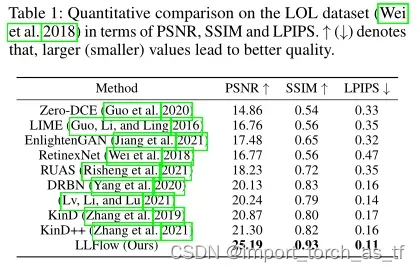
4.2 Evaluation on LOL

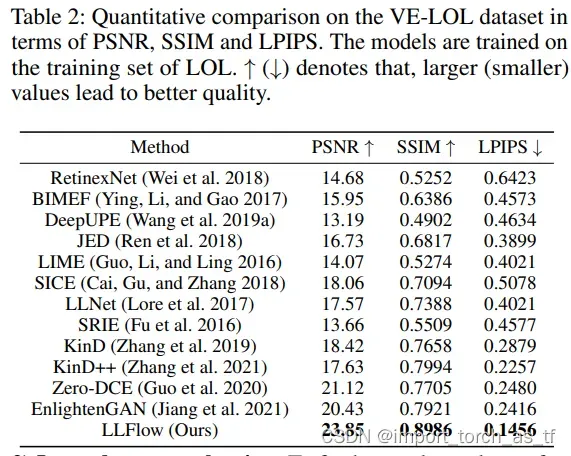
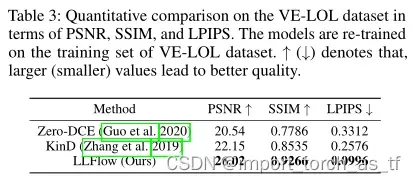
4.3 Evaluation on VE-LOL

4.4 Ablation study
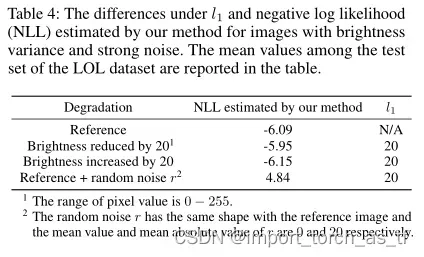
1) The losses estimated by our method and l1: 为了验证我们的动机,即与像素重建损失相比,条件归一化流可以模拟更复杂的误差分布,我们进一步比较了通过我们的方法和l1获得的损失。如表4所示,在l1损失的测量下,强噪声图像和亮度稍有不同的图像具有相同的似然值,而在我们的模型测量下,后者的似然值比前者高得多,后者更符合人类感知。
2) The effect of different z: 与现有方法相比,我们的方法的一个主要优点是LLFlow可以更好地将亮度方差编码到潜在空间z中。为了验证这种策略的有效性,我们在从−0.4到0.4,步长为0.2。图6中的结果表明,图像的亮度与z值是单调的,这表明我们的模型可以编码数据集的方差,即收集数据对时不可避免的不确定性。

3) The activation area of LLFlow: 为了更好地理解我们的模型如何建立更强大的约束,我们可视化了我们方法的梯度激活图。对于正常曝光的图像xhigh,其可以是参考图像或来自其对应的微光图像xlow的微光增强网络的输出,梯度激活图G可以如下获得:
![]()
其中h是直方图均衡化操作,以更好地可视化结果。从图8的结果中,我们可以发现有伪影的区域具有更高的梯度激活值。这表明,即使没有参考图像,我们的模型也可以根据学习到的条件分布来区分不现实的区域。

4) The effectiveness of model components and training paradigm: 为了研究我们的训练模式和框架中不同组件的有效性,我们分别评估了我们的条件编码器的性能,并通过使用l1loss对它们进行训练来评估整个框架的性能。
对于l1loss下的整个框架评估,我们经验发现,直接使用它进行培训无法收敛。为此,我们首先通过最小化负对数似然L(xl,xref),对框架进行1000次迭代的预训练。在相关实验中,所有网络均采用相同的批量大小、patch大小、图像预处理进行训练。我们在很大范围内微调其他超参数,例如学习率和权重衰减,以实现最佳性能。
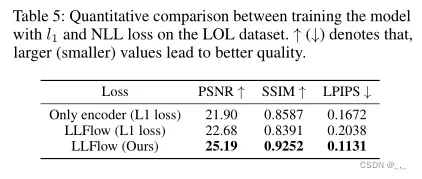
在LOL数据集(Wei等人,2018)上评估的结果如表5所示。与l1loss训练的模型相比,通过最小化NLL损失训练的模型在所有指标上都有很大的改进。(损失函数是最关键的涨点原因)l1loss训练模型与NLL训练模型结果的直观比较如图9所示。从结果来看,l1损失训练的模型产生了更明显的伪影。定量和定性结果都表明,与简化的像素损失相比,基于流的方法在模拟正常亮度图像的分布方面具有优势。

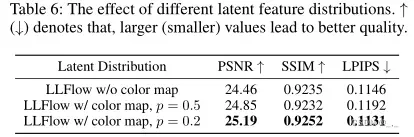
5) The effect of different latent feature distributions: 为了评估我们提出的光照不变颜色图和不同超参数p的有效性,我们使用LOL数据集对其进行了评估(Wei等人,2018年)。表6中的结果表明,使用新设计的彩色地图,我们的整个模型获得了更好的PSNR值。较高的SSIM和LPIPS值表明,颜色贴图有助于改善图像颜色和亮度的一致性。
这图片水印我真是吐了,本来就一个特别小的图片再加上水印完全看不清里面的字,被逼无奈只能换个用户昵称才能弱化水印的干扰…
文章出处登录后可见!