

(一)解决的问题:
数据的长尾分布,导致对样本分类时对多数类的偏向,使得训练出有偏分类器。
(二)动机:
提出了一种新的混合网络,包括监督对比损失学习图像特征和交叉熵损失分类器,以实现长尾图像分类。
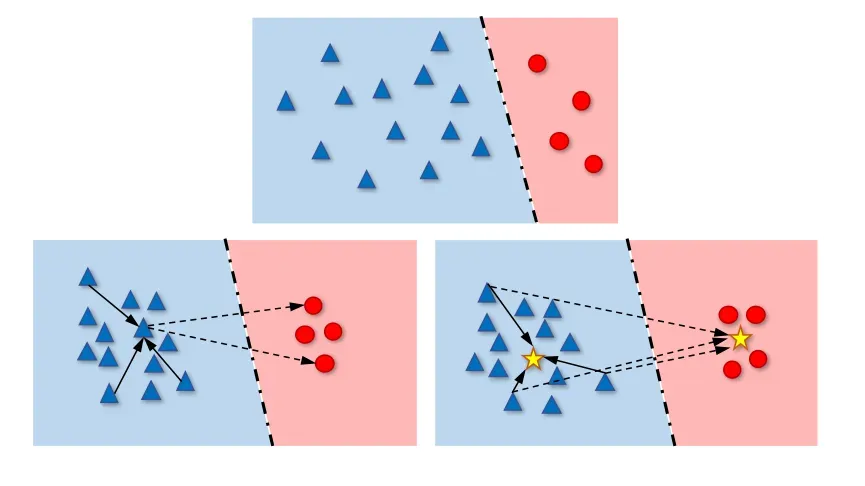

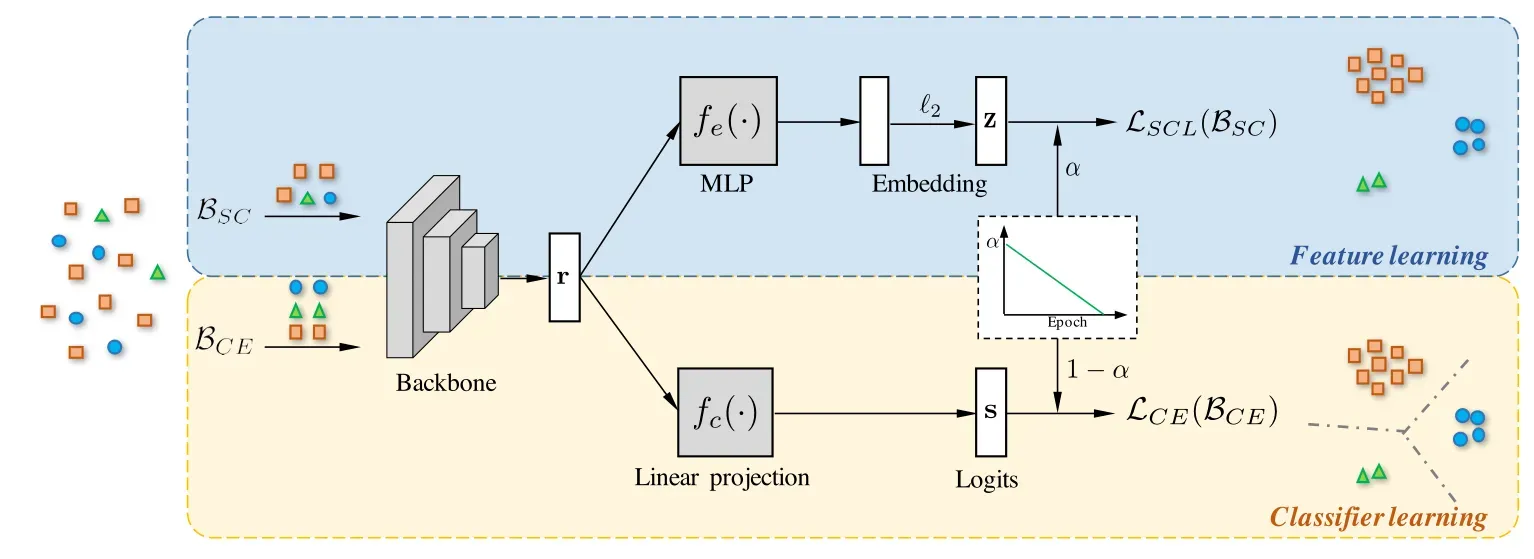

(三)步骤:
- 先对输入的图像通过Backbone(比如Resnet),得到一些图像的特征分布。
- 上面的结构主要对特征分布进行对比学习,正样本拉近、负样本原理的操作;下面的结构是一个分类器,主要对形成的特征空间进行分类。
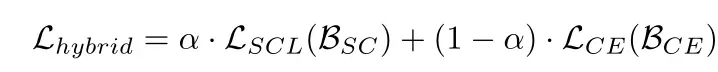

α会随着训练的进行逐渐减小,这样做是很合理的,因为前期的话模型会注重特征的分布,而不是注重分类器的分类,只有不断的训练模型,不断进行对比学习,各个类的特征分布才会更加明显,这样的话,模型才将重心放在分类器的训练上,让分类器更容易的去分类。
(四)SCL损失函数:
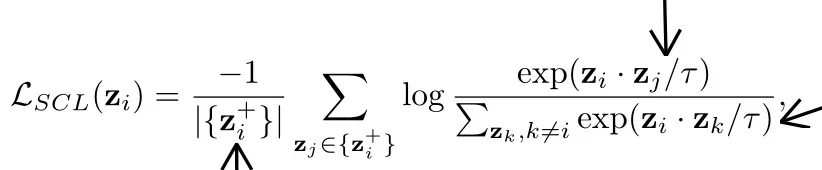

解释:
|{Zi+}|是正样本的个数。
分子中Zi·Zj是表示Zi与正样本的内积,越大表示越接近
(五)PSC损失函数


定义![]()

原式可化为![]()

分母排除了![]()

分母与SC也有区别,它是和每一个负样本所对应的prototype进行对比,和batch大小无关。
(六)MPSC损失函数
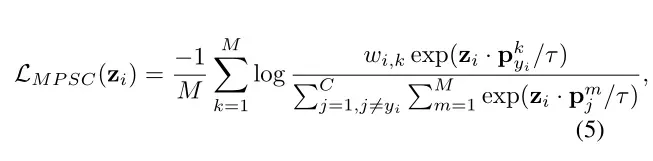

这是有多个prototype的情况
(七)消融实验:
(1)解耦模型与一般模型的对比
(2)PSC损失与交叉熵损失
(3)分类方式的对比:
在交叉熵损失下,类平衡抽样比随机抽样的准确率下降约5%。说明PSC损失对数据采样的敏感性,而 HybridPSC网络使用随机抽样和类平衡抽样的性能相当,这表明HybridPSC可以缓解过抽样(类平衡抽样属于过抽样)带来的过拟合问题。
(4)PSC和SC的对比:
PSC在iNaturalist中的效果好于SC
因为与iNaturalist数据集中的类数相比,SC的batch太小,无法提供足够的负样本来学习高质量的特征。PSC损失避免了这个问题,无论batch大小,每个样品都将与所有负prototype进行对比。由于这个原因,Hybrid-PSC具有优越的分类性能。
文章出处登录后可见!