随机种子和可重复性
在 Python、Numpy 和 PyTorch 中设置实验

Motivation
“程序员最可怕的噩梦是什么?”
就我而言,我可以肯定地说,作为一名程序员,我最糟糕的噩梦是一段代码,它的行为就像是随机的,每次运行它都会喷出不同的结果,即使我给它同样的输入!
实际上有一个著名的疯狂定义:
“精神错乱就是一遍又一遍地做同样的事情,却期待不同的结果。”
虽然它通常归因于阿尔伯特爱因斯坦,但研究表明情况并非如此。但是,抛开引用的作者身份不谈,事实仍然存在:一遍又一遍地向一段代码提供相同的输入,每次都得到不同的结果,这会让你发疯:-)[0]
这篇文章包含了我书中内容的部分复制品:“使用 PyTorch 逐步进行深度学习:初学者指南”。[0]
(Pseudo-) Random Numbers
“怎么可能调试和修复这样的东西?”
对我们程序员来说幸运的是,我们不必处理真正的随机性,而是处理伪随机性。
“你是什么意思?”
好吧,你知道,随机数并不是完全随机的……它们实际上是伪随机的,这意味着数字生成器会吐出一系列看起来像是随机的数字。但事实并非如此。
这种行为的好处是我们可以告诉生成器启动一个特定的伪随机数序列。在某种程度上,它就像我们告诉生成器:“请生成序列#42”,它会溢出一个数字序列。
这个数字,42,就像序列的索引一样,被称为种子。每次我们给它相同的种子时,它都会生成相同的数字。
“同样的老种子,同样的老数字。”
这意味着我们拥有两全其美:一方面,我们确实生成了一系列数字,出于所有意图和目的,这些数字被认为是随机的;另一方面,我们有能力复制任何给定的序列。我敢肯定,您会理解这对于调试目的和避免精神错乱是多么方便:-)
此外,您可以保证其他人能够重现您的结果。想象一下,运行从博客文章或书籍中获得的代码,并且每次都得到不同的输出,这将是多么烦人,不得不怀疑它是否有任何问题。
在学习一个新主题时,您需要做的最后一件事是失去平衡,因为每次运行一些代码时都会得到不同的结果(代码很可能是完全正确的,除了有一个种子集)。但是,通过正确设置随机种子,你和我,以及其他运行代码的人,可以实现相同的输出,即使它涉及生成随机数据!
Generating Random Numbers
虽然种子被称为随机,但它的选择肯定不是!通常,您会看到选择的随机种子是 42,这是人们可能选择的所有随机种子中的(第二个)最小随机性。[0][1]
因此,我们也在纪念这篇文章中将种子设置为 42 的悠久传统。在纯 Python 中,你使用 random.seed() 来设置种子,然后你可以使用 random.randint() 来绘制一个随机整数,例如:[0][1]
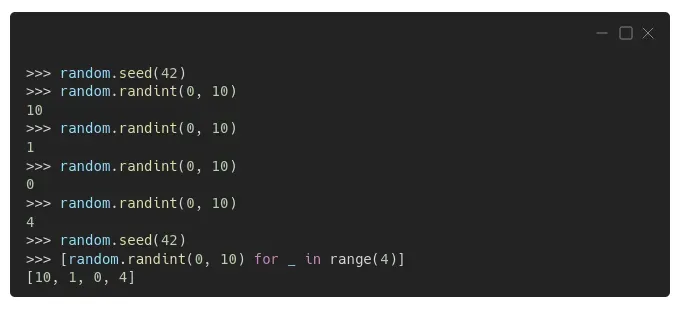
看?完全确定性!一旦将随机种子设置为 42(显然!),生成的前四个整数依次为 10、1、0 和 4,无论您是一个一个生成它们,还是在列表推导中生成它们。
如果您对生成本身感到好奇,Python 的 random 模块使用 Mersenne Twister 随机数生成器,这是一种完全确定性的算法。这意味着该算法非常适合解决可重复性问题,但完全不适合加密目的。
数字生成器有一个内部状态,它跟踪从特定序列中提取的最后一个元素(每个序列由其对应的种子标识),因此它知道从哪里选择下一个元素。
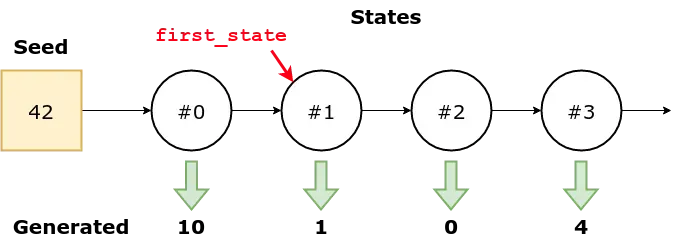
如果您愿意,可以使用 random.getstate() 和 random.setstate() 检索(和设置)该状态:[0][1]
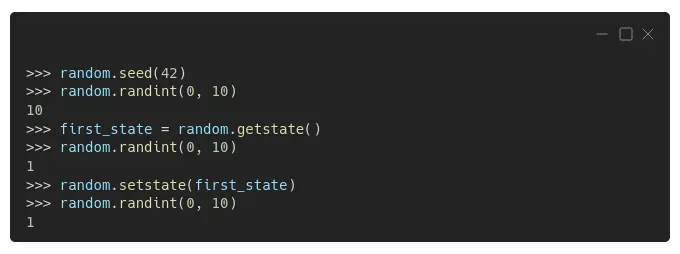
正如预期的那样,第一个数字又是 10(因为我们使用了相同的种子)。此时,生成器的内部状态记录了从序列中只抽取了一个数字。我们将此状态保存为 first_state。
所以我们再画一个,正如预期的那样,我们得到了数字 1。内部状态会相应地更新,但随后我们将其设置回第二个数字被绘制之前的状态。
现在,如果我们再绘制一个数字,我们将再次获得数字 1,因为我们通过更新其内部状态强制生成器“忘记”最后一次绘制。
这些数字看起来不再那么随机了,嗯?
“是的,但我要问……那种状态是什么?”
很高兴你问。这只是一个元组!第一个元素是版本 (3),第二个元素是一长串 625 个整数(内部状态),最后一个元素通常是 None(你现在可以放心地忽略它)。
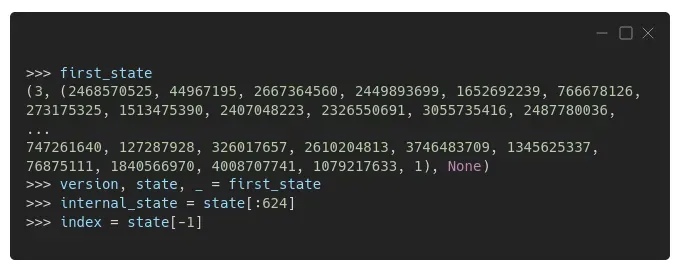
看到最后的“1”了吗?这是列表的第 625 个元素,它作为其他元素的索引——实际的内部状态由前 624 个元素表示。请记住这一点,我们很快就会回来!
“好的,所以我们很好,现在一切都可以完美重现了吗?”
我们还没有完全做到……如果你查看 Python 的“可重复性说明”,你会看到:[0]
“通过重新使用种子值,只要多个线程没有运行,相同的序列就应该可以在运行之间重现。”
所以,如果你是多线程的,那么可重复性就再见了!从好的方面来说,Python 的(伪)随机数生成器(我们从现在开始称其为 RNG)有两个保证(转录自“注释”):
- 如果添加了新的播种方法,则将提供向后兼容的播种机。
- 当兼容的播种机被赋予相同的种子时,生成器的 random() 方法将继续产生相同的序列。
“好的,现在我们好了?”
对不起,不行! Python 自己的 RNG 并不是您可能需要为其设置种子的唯一一个。
Numpy
如果您也在使用 Numpy,则需要为其自己的 RNG 设置种子。您可以为此使用 np.random.seed() :[0]
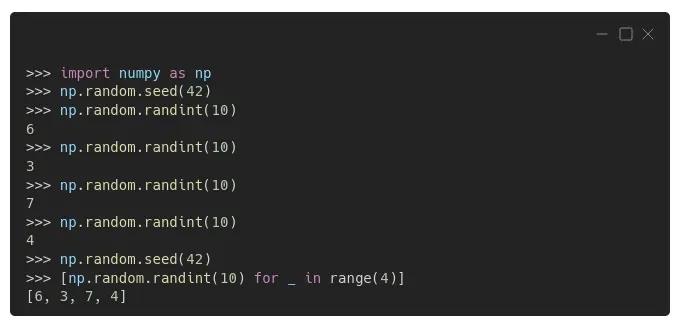
您可以从上面的示例中看到,Numpy 的 RNG 的行为方式与 Python 的 RNG 相同:一旦设置了种子,生成器就会输出完全相同的数字序列 6、3、7 和 4。
尽管上面的代码是最常见的“在野外”,并且许多人继续这样使用它(包括我自己,被指控有罪),但它已经被认为是遗留代码。
更新的 Numpy 版本,从 1.17 开始,使用不同的方式来生成(伪)随机数:首先创建一个生成器,然后从中提取数字。可以使用 np.random.default_rng() 创建默认生成器:[0]
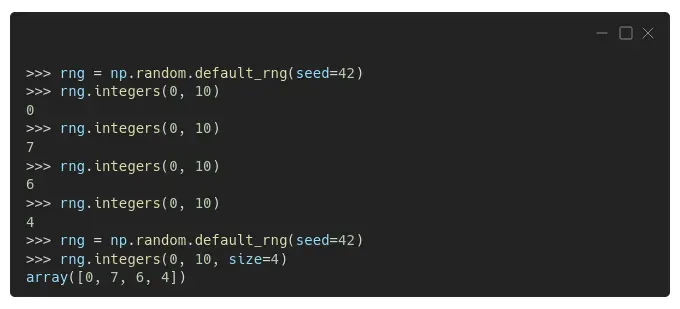
“等等,现在的数字不一样了吗?”
是的,它们是不同的,即使我们使用的是相同的种子,42。
“Why is that?”
数字不同是因为生成器不同,也就是说,它使用了不同的算法。 Numpy 的遗留代码使用 Mersenne Twister (MT) 算法,就像 Python 的 random 模块一样,而 Numpy 的新默认生成器使用 Permute Congruential Generator (PCG) 算法。
但是,事实证明,即使 Numpy 的遗留代码和 Python 的 random 模块使用相同的算法,并且我们在它们中使用相同的种子,生成的数字仍然不同!
“你在开玩笑吧!为什么?!”
我知道您可能会感到沮丧,差异归结为 Python 的随机模块和 Numpy 处理生成器内部状态中那个讨厌的“索引”的方式。如果您对更多细节感兴趣,请查看下面的旁白——否则,请随意跳过它。
匹配内部状态
如果我们使用相同的 624 个数字列表来更新两个生成器的状态,同时将“索引”设置为 624(正如 Numpy 默认情况下所做的那样),这就是我们得到的:匹配序列!
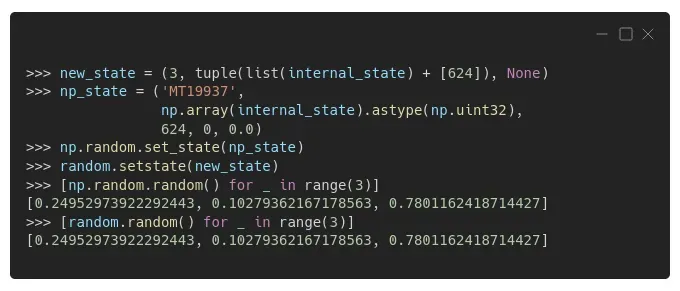
正如您在上面的代码中看到的,也可以分别使用 set_state() 和 get_state() 检索或设置 Numpy 生成器的内部状态,并且状态本身在其元组中还有更多元素(’MT19937’代表对于 Mersenne Twister (MT) 和它的范围 (2¹⁹⁹³⁷-1),顺便说一下),但我们不会对此进行更深入的研究。毕竟,你几乎不可能在 Numpy 中修改生成器的内部状态……[0][1]
还有一件事需要指出,取自 Numpy 的生成器文档,标题为“无兼容性保证”的部分:[0]
生成器不提供版本兼容性保证。特别是,随着更好的算法发展,比特流可能会改变。
谁说确保重现性很容易?不是我!
请记住:为了真正的可重复性,您需要使用相同的随机种子、相同的模块/包和相同的版本!
是时候换一个套餐了!
PyTorch
就像 Numpy 一样,PyTorch 也有自己的设置种子的方法,torch.manual_seed(),它为所有设备(CPU 和 GPU/CUDA)设置种子:[0]
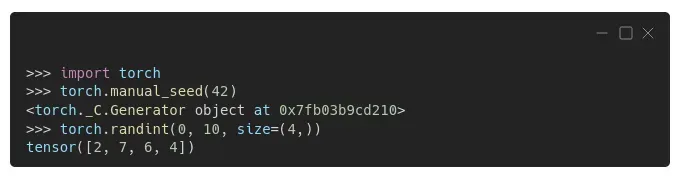
正如您可能已经预料到的那样,生成的序列再次不同。新包装,新序列。
但还有更多!如果你在不同的设备上生成一个序列,比如你的 GPU(’cuda’),你会得到另一个序列!
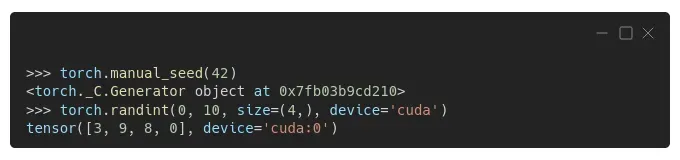
在这一点上,这对您来说应该不足为奇,对吧?此外,PyTorch 关于再现性的文档非常简单:[0]
“不保证在 PyTorch 版本、单个提交或不同平台之间完全可重现的结果。此外,即使使用相同的种子,CPU 和 GPU 执行之间的结果也可能无法重现。”
因此,我相应地更新了上一节中的建议:
请记住:为了真正的可重复性,您需要使用相同的随机种子、相同的模块/包、相同的版本、相同的平台、相同的设备,也许还有相同的驱动程序(例如,您的 GPU 的 CUDA 版本) !
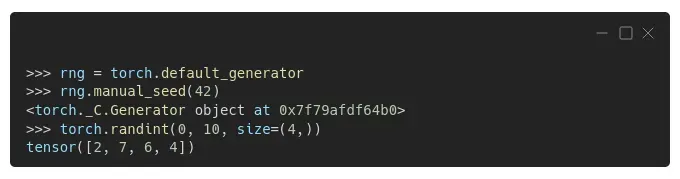
也许您注意到上面的输出中有一个生成器……不出所料,PyTorch 也使用生成器,就像 Numpy 一样,并且该生成器是 PyTorch 的默认生成器。我们可以使用 torch.default_generator 检索它并使用 manual_seed() 方法设置它的种子:[0][1]
您还可以创建另一个生成器,并将其用作其他函数或对象的参数:
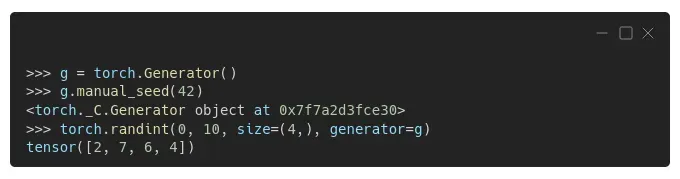
在一种情况下,使用自己的生成器特别有用:在数据加载器中采样。
Data Loaders
在为训练集创建数据加载器时,我们通常将其参数 shuffle 设置为 True(因为在大多数情况下,对数据点进行混洗可以提高梯度下降的性能)。这是一种非常方便的改组数据的方法,该方法在后台使用 RandomSampler 实现。每次请求新的 mini-batch 时,它都会随机采样一些索引,并返回与这些索引对应的数据点。[0]
即使不涉及改组,这在用于验证集的数据加载器中是典型的,也会使用 SequentialSampler。在这种情况下,每当请求新的小批量时,此采样器都会按顺序返回一系列索引,并返回与这些索引对应的数据点。[0]
从 PyTorch 1.7 开始,为了保证重现性,我们需要给 DataLoader 分配一个生成器,所以在对应的采样器中使用(当然前提是它使用了生成器)。[0]
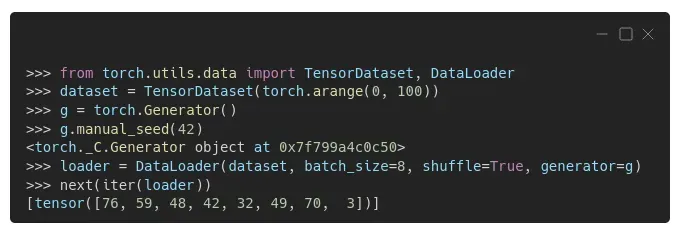
我们实际上可以从加载器中检索采样器,检查它的初始种子,如果需要,可以手动设置不同的种子:
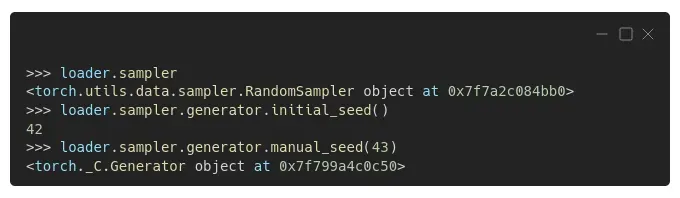
我们将在几个部分中做到这一点,同时编写一个函数来使用“一个种子来统治它们”:-)
将生成器分配给数据加载器将使您有所了解,但前提是您在主进程中加载数据(num_workers=0,默认值)。如果您想使用多处理来加载数据,即指定更多的工作人员,您还需要为您的数据加载程序分配一个 worker_init_fn() 以避免所有工作人员绘制完全相同的序列的数字。让我们看看为什么会发生这种情况!
在上述情况下,PyTorch 实际上可以照顾自己——它用不同的编号为每个工人播种,即 base_seed + worker_id,但它不能照顾其他包(例如 Numpy 或 Python 的随机模块)。[0]
我们可以使用作为参数传递给数据加载器的 seed_worker() 函数中的一些打印语句来看看发生了什么:
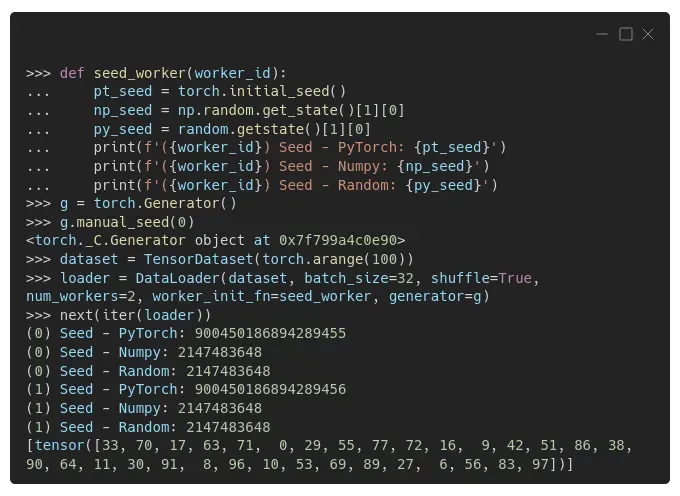
有两个 worker,(0) 和 (1),每次调用 worker 执行其职责时,seed_worker() 函数都会打印 PyTorch、Numpy 和 Python 的 random 模块使用的种子。
你可以看到 PyTorch 使用的种子很好——第一个 worker 使用了一个以 55 结尾的数字;第二个工人的,一个以 56 结尾的数字,正如预期的那样。
但是 Numpy 和 Python 的 random 模块使用的种子在 worker 中是相同的,这就是我们想要避免的。不过,种子跨模块相同是可以的。
幸运的是,有一个简单的解决方法:我们不是打印语句,而是在 seed_worker() 函数中包含一些种子设置语句,使用 PyTorch 的初始种子(并对其进行调整以使其成为 32 位整数):
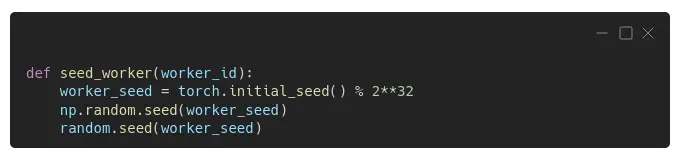
现在每个工人都将为 PyTorch、Numpy 和 Python 的随机模块使用不同的种子。
“好的,我明白这一点,但是如果我只使用 PyTorch,为什么我需要为其他包播种?”
播种 PyTorch 还不够!
你可能会认为,如果你没有在代码中明确使用 Numpy 或 Python 的 random 模块,你就不需要关心为它们设置种子,对吧?
也许你不知道,但最好谨慎行事并为所有内容设置种子:PyTorch、Numpy 甚至 Python 的随机模块,这就是我们在上一节中所做的。
“Why is that?”
事实证明,PyTorch 可能正在使用不是它自己的生成器!老实说,当我发现这件事时,我也感到很惊讶!听起来很奇怪,在 Torchvision 0.8 之前的版本中,仍然有一些代码依赖于 Python 的随机模块,而不是 PyTorch 自己的随机生成器。当使用一些用于数据增强的随机转换时,就会出现问题,例如 RandomRotation()、RandomAffine() 等。
CUDA
手动设置 PyTorch 的种子适用于 CPU 和 CUDA/GPU,正如我们在前几节中看到的那样。但是 CUDA 卷积操作使用的 cuDNN 库仍然可能是非确定性行为的来源。
事实证明,该库尝试使用最快的算法,具体取决于提供的参数以及底层硬件和环境。但是我们可以通过禁用这个所谓的基准测试功能,将 torch.backends.cudnn.benchmark 设置为 False 来强制确定性地选择算法。
虽然使用上面的配置可以确定算法的选择,但算法本身可能不是!
“Oh, c’mon!”
我听到你了。为了解决这个问题,我们还需要进行另一个配置:将 torch.backends.cudnn.deterministic 设置为 True。

使用 CUDA 的可重复性还有其他含义:由于 CUDA 10.2 版中引入的更改,RNN 和 LSTM 层也可能表现出不确定的行为(有关详细信息,请参阅文档)。[0]
PyTorch 的文档建议将环境变量 CUBLAS_WORKSPACE_CONFIG 设置为 :16:8 或 :4096:2 以强制执行确定性行为。
伴唱:老麦克托奇有个模特
“老麦克火炬有一个模型,E-I-E-I-O
在它的模型上,它有一些种子,E-I-E-I-O
这里有种子,那里有种子
这里一粒种子,那里一粒种子,到处都是种子
老麦克火炬有一个模型,E-I-E-I-O”
你觉得上面的歌曲,来自“程序员童谣”吗?顺便说一句,我在开玩笑,那不是一本真正的书,我编的!也许我应该写这样一本书……但我离题了!
回到我们的主题,它可能感觉就像这首歌——种子和更多的种子——到处都是种子!
如果只有……
“一粒种子,统治一切!”
没有这样的事情,但我们可以尝试下一个最好的事情:我们自己的函数来设置尽可能多的种子!下面的代码为 PyTorch、Numpy、Python 的随机模块和采样器的生成器设置种子;除了配置 PyTorch 的后端以使 CUDA 卷积操作具有确定性。
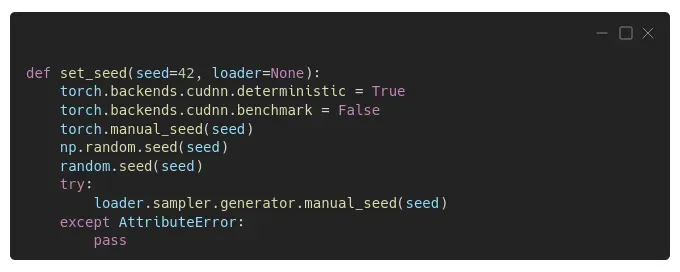
“Is this enough?”
不一定,不。某些操作可能仍然是不确定的,从而使您的结果无法完全重现。但是,可以强制 PyTorch 仅使用确定性算法设置 torch.use_deterministic_algorithms(True),但有一个问题……[0]
“I knew it!”
可能您正在执行的某些操作仅具有可用的非确定性算法,然后您的代码在调用时会抛出 RuntimeError。出于这个原因,我没有将它包含在上面的 set_seed 函数中——我们不会破坏代码以确保其可重复性。
此外,如果您使用的是 CUDA(10.2 或更高版本),除了设置 torch.use_deterministic_algorithms(True) 之外,您还需要设置环境变量 CUBLAS_WORKSPACE_CONFIG,如上一节所述。
那些不确定的算法可能来自最意想不到的地方。例如,在 PyTorch 的文档中,有一条关于在图像中使用填充时可能出现的再现性问题的注释警告:
“使用 CUDA 后端时,此操作可能会在其后向传递中引发非确定性行为,这种行为不容易关闭。请参阅有关背景再现性的说明。”
让我觉得有点奇怪的是,如此简单的操作会危及可重复性。去搞清楚!
Random Seed Tuning
“(正确的)随机种子就是你所需要的!”
看起来像个笑话,但随机种子的选择可能会对模型训练产生影响。有些种子比其他种子“更幸运”,因为它们允许模型更快地训练,或者实现更低的损失。当然,没有办法事先告诉它,不,42 不是“什么是正确的随机种子”问题的答案:-)
如果您对这个话题感到好奇,可以查看 David Picard 的论文:“Torch.manual_seed(3407) is all you need: On the impact of random seed in deep learning architectures for computer vision”。这是摘要:[0]
“在本文中,我研究了在使用流行的深度学习架构进行计算机视觉时随机种子选择对准确性的影响。我在 CIFAR 10 上扫描了大量种子(最多 104 个),我还在 Imagenet 上使用 pre 扫描了更少的种子- 用于调查大规模数据集的训练模型。结论是,即使方差不是很大,也很容易找到比平均值表现更好或更差的异常值。
Final Thoughts
Reproducibility is hard!
而且我们甚至没有谈论更基本的问题,例如确保您正确使用数据以避免多年后其他人试图复制您发布的结果时的尴尬(参见 Reinhart 和 Rogoff 的 Excel Blunder,也被称为“如何不要在经济学中表现出色”)![0][1]
我们只关注(伪)随机数生成器,即便如此,仍需要考虑许多不同的(伪)随机性来源以确保可重复性。这是很多工作,但值得麻烦。
确保始终在代码一开始就初始化随机种子,以确保(或尝试!)结果的可重复性。
愿您未来的实验完全可重复!
如果您有任何想法、意见或问题,请在下方发表评论或通过我的 bio.link 页面联系。[0]
如果您喜欢我的帖子,请考虑通过使用我的推荐页面注册成为 Medium 会员来直接支持我的工作。对于每一个新用户,我都会从 Medium 获得一小笔佣金 :-)[0]
文章出处登录后可见!