用简单和高级的技术来填补缺失的数据
关于均值、众数、时间序列、KNN 和 MICE 插补的教程

当数据集中没有为感兴趣的变量存储数据时,就会发生数据丢失。根据其数量,缺失数据可能会损害任何数据分析的结果或机器学习模型的稳健性。[0]
在使用 Python 处理缺失数据时,Pandas 的 dropna() 函数会派上用场。我们使用它来删除包含空值的行和列。它还有几个参数,例如定义行或列是否丢弃的轴,如何确定任何或所有行/列中是否出现缺失值,以及选择一组列或标签以应用丢弃功能的子集。
df.dropna(axis=0, how='any', subset=None, inplace=False)但是,还有其他可能更好的方法来处理丢失的数据。在本文中,我们将了解如何使用简单和高级的技术来估算(替换)缺失数据。我们将首先介绍简单的单变量技术,例如均值和模式插补。然后,我们将看到时间序列数据的前向和后向填充,我们将探索诸如线性、多项式或二次插值来填充缺失值。稍后,我们将探索先进的多变量技术,并学习如何使用带有 KNN 和 MICE 的机器学习来估算缺失值。
在阅读本文时,我鼓励您查看我的 GitHub 上的 Jupyter Notebook 以获取完整的分析和代码。[0]
坚持住,让我们开始吧! 🦾
Data
在本文中,我们将使用来自 OpenMV.net 的旅行时间数据集。使用以下代码,我们将通过解析 Date 和 StartTime 列并将随机值转换为 MaxSpeed 列的 10% 上的缺失值来加载数据。[0][1]
让我们打印数据的前 5 行:

Detecting missing values
我们可以使用 isna() 或 isnull() 方法来检测数据中的缺失值。我们可以使用 sum() 获得每列中缺失值的总数,或者使用 mean() 取平均值。
df.isnull().sum()DayOfWeek: 0
GoingTo: 0
Distance: 0
MaxSpeed: 22
AvgSpeed: 0
AvgMovingSpeed: 0
FuelEconomy: 17
TotalTime: 0
MovingTime: 0
Take407All: 0
Comments: 181
df.isnull().mean()*100DayOfWeek: 0.00%
GoingTo: 0.00%
Distance: 0.00%
MaxSpeed: 10.73%
AvgSpeed: 0.00%
AvgMovingSpeed: 0.00%
FuelEconomy: 8.29%
TotalTime: 0.00%
MovingTime: 0.00%
Take407All: 0.00%
Comments: 88.29%
由于我们用 np.nan 随机替换了 MaxSpeed 列中 10% 的值,因此它有大约 10% 的缺失值也就不足为奇了。
我们还可以使用 missingno 包来生成数据缺失的可视化表示。如果您尝试检测缺失值之间的关系,例如与其他列一起缺失或在特定周、月等期间缺失,这是一个非常有用的工具。
在下面的矩阵视图中,我们可以看到带有空白行的缺失值,而不是带有黑线的缺失值。正如预期的那样,我们的缺失值在 MaxSpeed 列是随机的。

1. Basic Imputation Techniques
1.1。均值和众数插补
我们可以使用 scikit-learn 中的 SimpleImputer 函数将缺失值替换为填充值。 SimpleImputer 函数有一个名为 strategy 的参数,它为我们提供了四种选择插补方法的可能性:[0]
- strategy=’mean’ 使用列的平均值替换缺失值。
- strategy=’median’ 使用列的中值替换缺失值。
- strategy=’most_frequent’ 使用列的最频繁(或模式)替换缺失值。
- strategy=’constant’ 使用定义的填充值替换缺失值。
下面我们将在 MaxSpeed 列上使用 SimpleImputer 转换器,它有 10% 的随机缺失值。我们首先用 strategy=mean 定义均值 imputer,然后在列上应用 fit_transform。
# Mean Imputation
df_mean = df.copy()
mean_imputer = SimpleImputer(strategy='mean')
df_mean['MaxSpeed'] = mean_imputer.fit_transform(df_mean['MaxSpeed'].values.reshape(-1,1))让我们绘制一个散点图,其中 X 轴为 AvgSpeed,Y 轴为 MaxSpeed。我们知道 AvgSpeed 列没有缺失值,我们将 MaxSpeed 列中的缺失值替换为列均值。在下图中,绿点是转换后的数据,蓝点是原始的非缺失数据。
# Scatter plot
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mean.plot(x="AvgSpeed", y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='Mean Imputation', colorbar=False)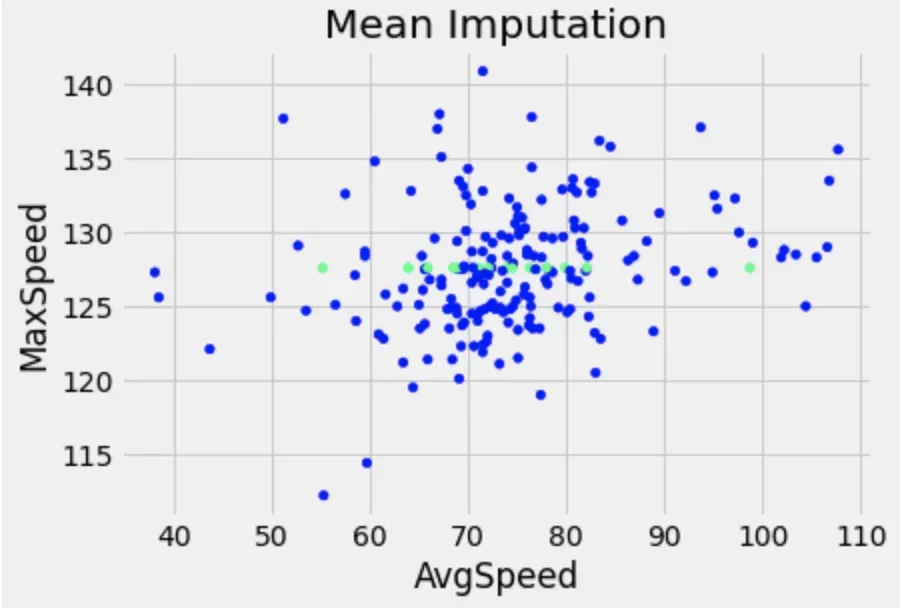
我们可以对中值、最频繁或常数值重复相同的操作。 🌀
这是使用最频繁值(模式)进行插补的示例。
# Mode Imputation
df_mode = df.copy()
mode_imputer = SimpleImputer(strategy='most_frequent')
df_mode['MaxSpeed'] = mode_imputer.fit_transform(df_mode['MaxSpeed'].values.reshape(-1,1))
# Scatter plot
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mode.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='Mode Imputation', colorbar=False)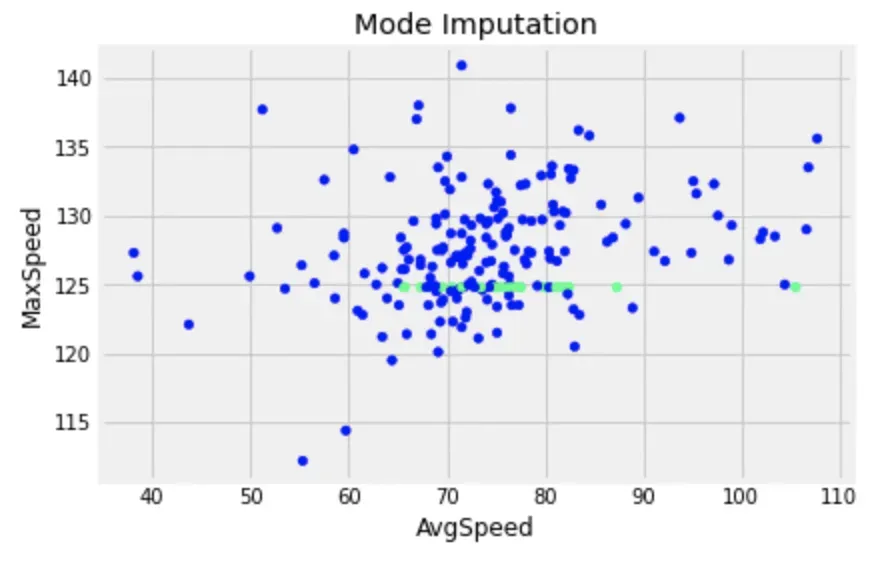
注意:如果有多个众数,则插补使用最小众数。
但是,均值插补可能会使标准误差产生偏差,并且如果没有随机缺失值,也会使列的实际均值/众数产生偏差。根据缺失的数量,以这种方式插补也会影响列之间的真实关系。如果该列有许多异常值,则中值插补应优于均值插补。
1.2. Time Series Imputation
在加载数据集时,我们使用 Date 和 StartTime 列的组合定义了索引,如果不清楚,请参阅上面的 Data 部分。☝️
在时间序列数据中估算缺失值的一种方法是用最后一个或下一个观察值填充它们。 Pandas 有 fillna() 函数,它有方法参数,我们可以选择“ffill”来填充下一个观察值或“bfill”来填充之前观察到的值。[0]
下图按时间显示 MaxSpeed 列的前 100 个数据点。
df['MaxSpeed'][:100].plot(title="MaxSpeed", marker="o")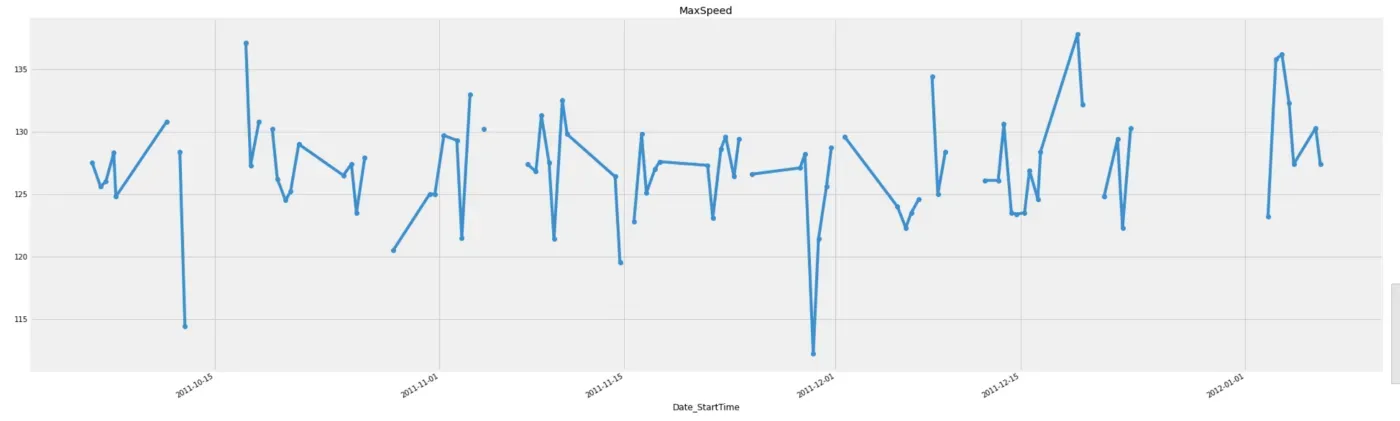
如果我们想用下一个观察值填充缺失值,我们应该使用 method=”ffill”。
# Ffill imputation
ffill_imputation = df.fillna(method='ffill')
# Plot imputed data
ffill_imp['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')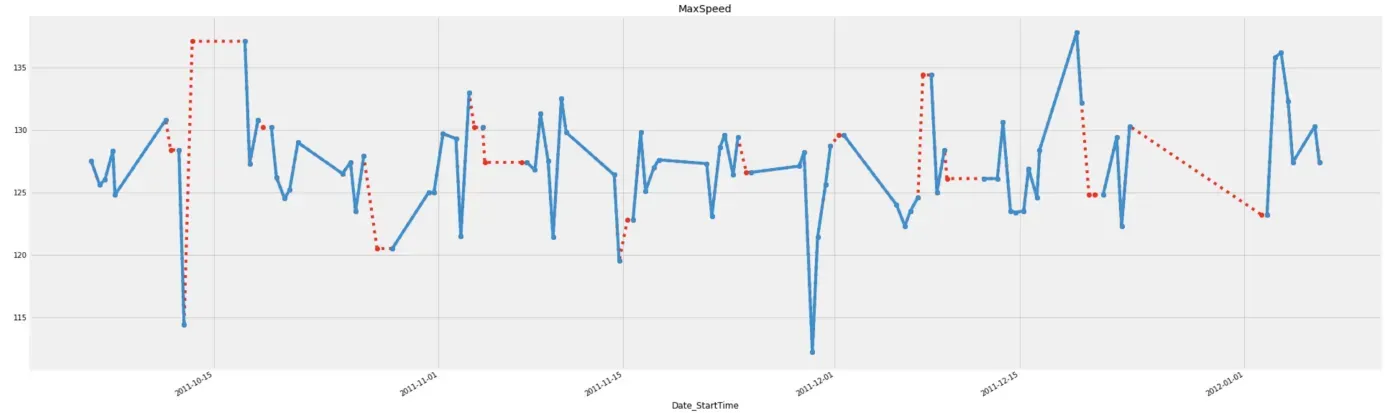
如果我们想用之前观察到的值填充缺失值,我们应该使用 method=”bfill”。
# Bfill imputation
bfill_imputation = df.fillna(method='bfill')
# Plot imputed data
bfill_imp['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')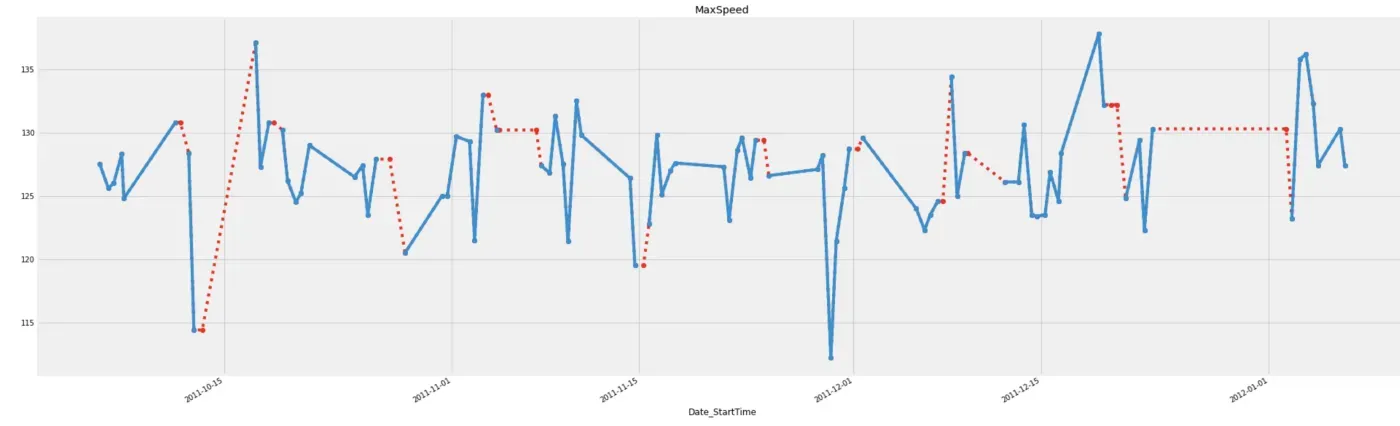
除了 bfill 和 ffill 之外,我们还可以使用 Pandas 中的 interpolate() 函数并选择 method=”linear” 以在前一个和下一个观察值之间按递增顺序填充缺失值。需要注意的是,此函数通过忽略索引来威胁值等距。[0]
# Imputing with linear interpolation
linear_interpolation = df.interpolate(method='linear')
# Plot imputed data
linear_int['MaxSpeed'][:100].plot(color='red', marker='o', linestyle='dotted')
df['MaxSpeed'][:100].plot(title='MaxSpeed', marker='o')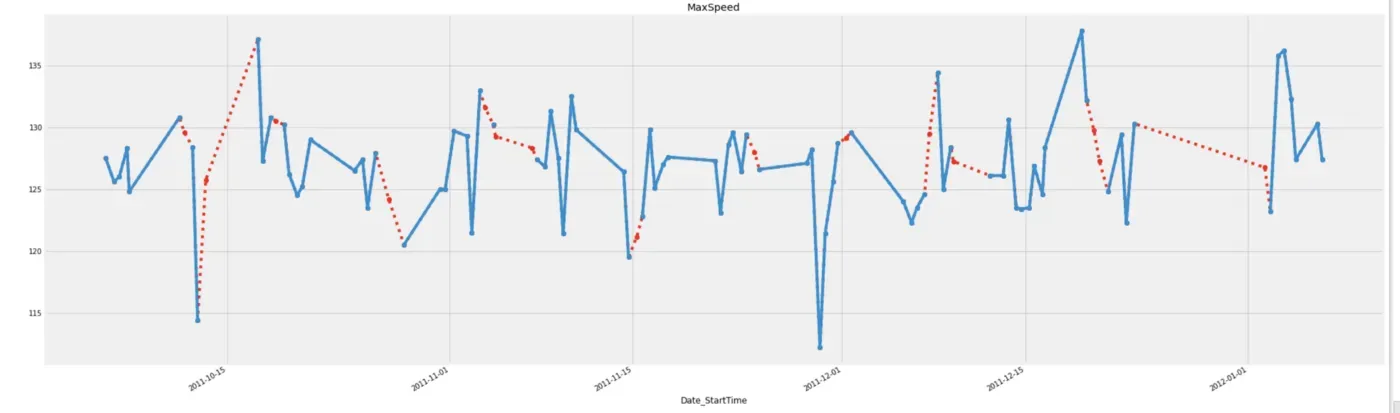
除了 method=linear 进行插值外,我们还可以选择多项式、样条、最近、二次等。如果您对插值技术感兴趣,请查看此 Pandas 文档。 📖[0]
2. Advanced Techniques
2.1。 K-最近邻 (KNN) 插补
估算缺失值的另一种方法是预测它们。最近邻插补被广泛使用并被证明是一种有效的缺失值插补方法。
我们可以使用来自 Scikit-learn 的 KNNImputer,其中缺失值是使用训练集中找到的 K-最近邻的平均值来估算的。[0]
from sklearn.impute import KNNImputerKNNImputer(missing_values=np.nan, n_neighbors=5, weights='uniform', metric='nan_euclidean')
KNNImputer 有几个参数,例如 missing_values,默认设置为 np.nan,n_neighbors 是选择的用于插补的相邻样本数,默认设置为 5,metric 是搜索邻居的距离度量,默认设置为 ‘nan -euclidean’ 但也可以使用用户定义的函数进行定义。
KNNImputer 可以处理连续、离散和分类数据类型,但不能处理文本数据。因此,我使用选定的列子集(距离、MaxSpeed、AvgSpeed 和 AvgMoovingSpeed)过滤数据。此外,我使用了 scikit-learn 的 MinMaxScaler 来规范化 0 到 1 之间的数值数据。由于 KNNImputer 是基于距离的算法,因此缩放是管道中的重要一步。
# Imputing with KNNImputer
from sklearn.impute import KNNImputer
from sklearn.preprocessing import MinMaxScaler
#Define a subset of the dataset
df_knn = df.filter(['Distance','MaxSpeed','AvgSpeed','AvgMovingSpeed'], axis=1).copy()
# Define scaler to set values between 0 and 1
scaler = MinMaxScaler(feature_range=(0, 1))
df_knn = pd.DataFrame(scaler.fit_transform(df_knn), columns = df_knn.columns)
# Define KNN imputer and fill missing values
knn_imputer = KNNImputer(n_neighbors=5, weights='uniform', metric='nan_euclidean')
df_knn_imputed = pd.DataFrame(knn_imputer.fit_transform(df_knn), columns=df_knn.columns)在定义 KNNImputer 之后,我们 fit_transform 并保存新的(估算的)数据。下面是插补数据与原始数据的散点图,绿色显示 MaxSpeed 的插补值。
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_knn_imputed.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='KNN Imputation', colorbar=False)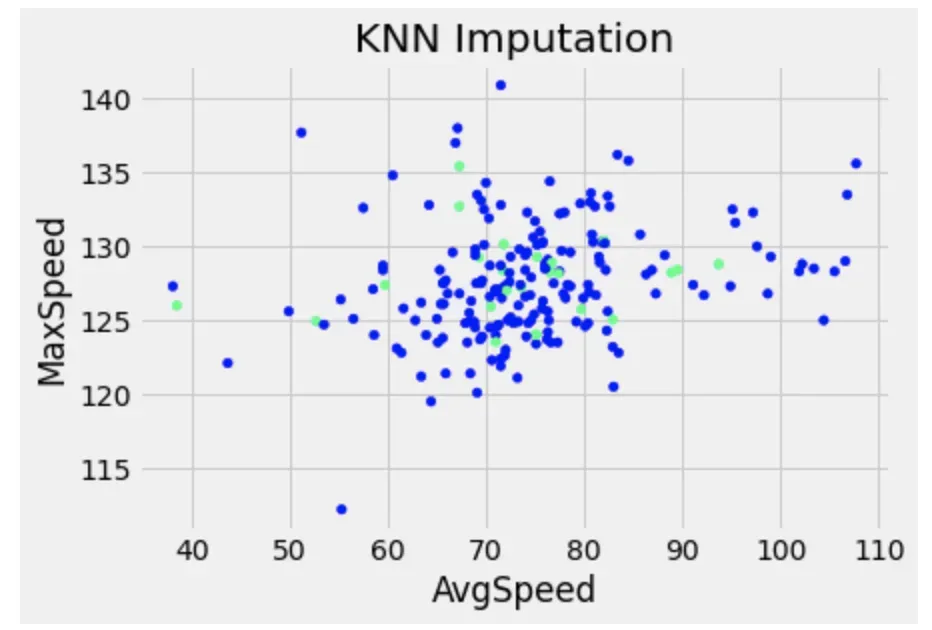
KNNImputer 具有几个优点,例如易于实现以及能够同时处理数字和分类数据类型。然而,定义邻居的数量 – k 可能会很棘手,因为它会在鲁棒性和速度之间进行权衡。如果我们选择一个小的 k,那么我们的计算速度很快,但结果却不太稳健。相比之下,如果我们选择一个大的 k,那么我们有一个更健壮但更慢的计算。
2.2.链式方程的多元插补——MICE
MICE 算法可能是最常用的插补技术之一,也是一个流行的面试问题。 😈
MICE 首先计算存在缺失值的每一列的平均值,并将平均值用作占位符。然后它运行一系列回归模型(链式方程)来按顺序估算每个缺失值。与任何回归模型一样,MICE 使用特征矩阵和目标变量进行训练,在这种情况下,目标变量是缺失值的列。 MICE 预测和更新目标列上的缺失值。迭代地,MICE 通过使用上一次迭代的预测不断更改占位符变量来重复此过程几次。最后,它达到了一个稳健的估计。
为了应用 MICE 算法,我们将使用 scikit-learn 中的 IterativeImputer。该估算器仍处于试验阶段,因此我们必须导入 enable_iterative_imputer。[0]
IterativeImputer(estimator=None, missing_values=np.nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy=’mean’, imputation_order=’ascending’)# Imputing with MICE
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn import linear_model
df_mice = df.filter(['Distance','MaxSpeed','AvgSpeed','AvgMovingSpeed'], axis=1).copy()
# Define MICE Imputer and fill missing values
mice_imputer = IterativeImputer(estimator=linear_model.BayesianRidge(), n_nearest_features=None, imputation_order='ascending')
df_mice_imputed = pd.DataFrame(mice_imputer.fit_transform(df_mice), columns=df_mice.columns)下面,查看估算数据与原始数据的散点图。
fig = plt.Figure()
null_values = df['MaxSpeed'].isnull()
fig = df_mice_imputed.plot(x='AvgSpeed', y='MaxSpeed', kind='scatter', c=null_values, cmap='winter', title='MICE Imputation', colorbar=False)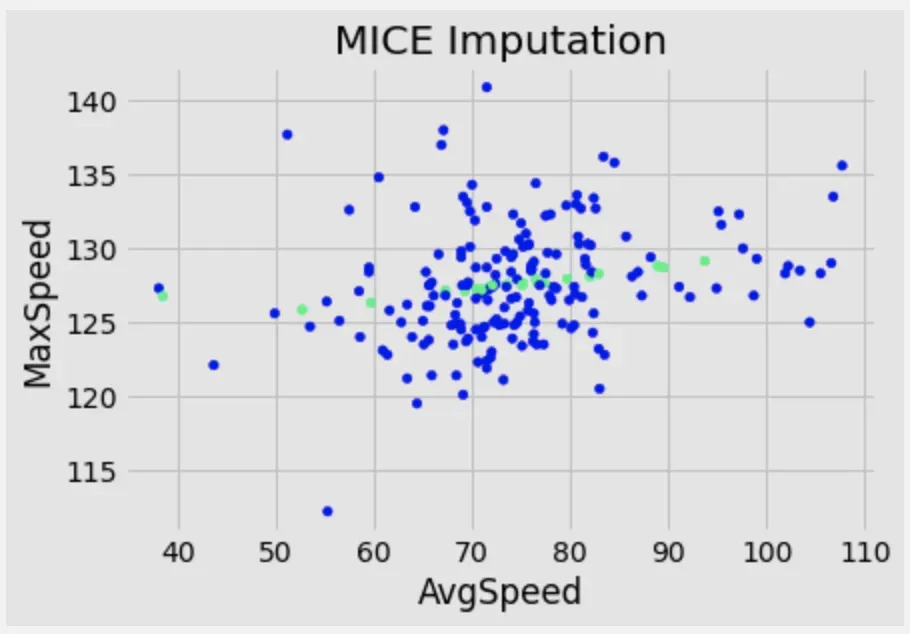
Conclusion
在本文中,我们探索了在数据集中估算缺失值的不同方法。我们从使用 missingno 包检测丢失的数据开始。然后我们将 Simple Imputer 与缺失数据列的平均值和最常见值一起使用。由于我们的数据中有时间元素,我们还讨论了回填、前向填充和线性插值,以使用时间序列填充缺失值。最后,我们转向更先进的技术; K-最近邻插补 (KNN) 和链式方程的多元插补 (MICE),它们使用机器学习来填充缺失值。
我希望您喜欢阅读有关估算缺失值的文章,并发现这篇文章对您完成的工作很有用!
如果你喜欢这篇文章,你可以在这里阅读我的其他文章并在 Medium 上关注我。如果您有任何问题或建议,请告诉我。✨[0][1]
喜欢这篇文章吗?成为会员获得更多![0]
References
文章出处登录后可见!