
检测和处理异常值的完整指南
检测异常值的 6 种方法和处理异常值的 4 种不同方法
异常值可能是数据分析或机器学习中的一个大问题。只有少数异常值可以完全改变机器学习算法的性能或完全破坏可视化。因此,重要的是要检测异常值并仔细处理它们。
Detecting Outliers
检测异常值一点也不难。您可以使用以下方法检测异常值:
- Boxplot
- Histogram
- 均值和标准差
- IQR(四分位间距)
- Z-score
- Percentile
在深入研究异常值检测之前,我想介绍一下我今天将用于本教程的数据。我们将使用可以从 seaborn 库加载的“tips”数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsdf = sns.load_dataset("tips")
df
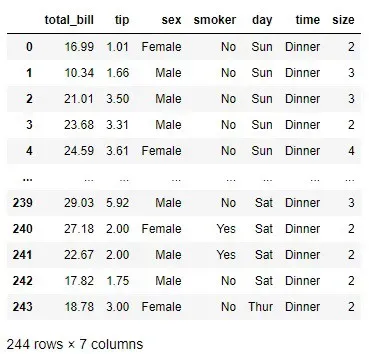
我们将主要关注总账单列。
Detection of Outliers
检测异常值的方法有很多种。有些是非常简单的可视化,仅告诉您数据中是否存在异常值。有些是非常具体的计算,可以告诉您异常值的确切数据。
Boxplot
Boxplot 默认显示异常值。这是 total_bill 部分的箱线图:
plt.boxplot(df['total_bill'])
plt.title("Boxplot of Total Bill")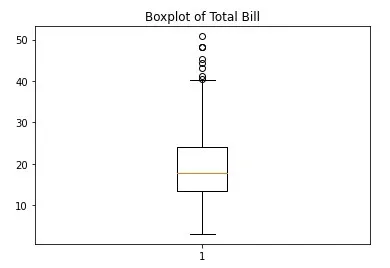
上端的一些点距离更远一些。您可以将它们视为异常值。它没有为您提供异常值的确切点,但它表明该数据列中存在异常值。
Histogram
查看分布还可以告诉您数据中是否存在异常值:
plt.hist(df['total_bill'])
plt.title("Distribution of Total Bill")
plt.show()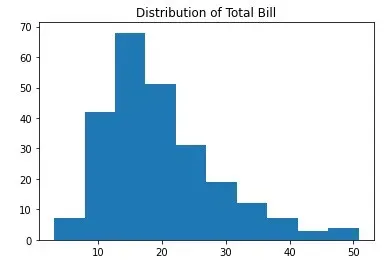
该分布还显示数据存在偏差,右侧存在异常值。
从这一点开始,我们将执行一些特定的计算来找出异常值的确切点。
均值和标准差法
在这种方法中,我们将使用均值、标准差和指定因子来找出异常值。
首先,我将总账单列保存为数据:
data = df.total_bill我们将在这里使用三倍。高于平均值的三个标准差和低于平均值的三个标准差将被视为异常值。首先,获取数据的均值和标准差:
mean = np.mean(data)
std = np.std(data)现在,找到比平均值高三个标准差的数据:
outlier_upper = [i for i in data if i > mean+3*std]
outlier_upperoutput:
[48.27, 48.17, 50.81, 48.33]在这里,我们找出低于平均值三个标准差的数据:
outlier_lower = [i for i in data if i < mean-3*std]
outlier_lowerOutput:
[]如您所见,我们在上端有一些异常值,但在下端,这种方法没有异常值。
在这里,我使用了 3 个标准。但是,如果您愿意,可以使用任何其他数字的因子。通常使用 2、3 或 4 的系数。请随意使用 2 或 4 并检查异常值。
Inter Quartile Range
在这种方法中,我们需要计算第一个四分位数和第三个四分位数以获得四分位数间距(IQR)。然后我们将考虑第一个四分位数减去 1.5 倍 IQR 作为数据的下限,第三个四分位数加上 1.5 倍 IQR 作为数据的上限。
data1 = sorted(data)
q1 = np.percentile(data1, 25)
q3 = np.percentile(data1, 75)
IQR = q3-q1
lower = q1-(1.5*IQR)
upper = q3 + (1.5*IQR)如果某个值低于下限且高于上限,则将其视为异常值。
outliers = [i for i in data1 if i > upper or i < lower]Output:
[40.55, 41.19, 43.11, 44.3, 45.35, 48.17, 48.27, 48.33, 50.81]这些是此方法中的异常值。
Z-score
只需修复一个 z 分数阈值,如果 z 分数高于此阈值,则数据为异常值。
thres = 2.5
mean = np.mean(data)
std = np.std(data)outliers = [i for i in data if (i-mean)/std > thres]
outliers
Output:
[48.27, 44.3, 48.17, 50.81, 45.35, 43.11, 48.33]Percentile Calculation
您可以简单地为上限和下限固定一个百分位数。在此示例中,我们将下限视为第 10 个百分位,将上限视为第 90 个百分位。
fifth_perc = np.percentile(data, 5)
nintyfifth_perc = np.percentile(data, 95)outliers = [i for i in data1 if i > nintyfifth_perc or i < fifth_perc]
outliers
Output:
[3.07,
5.75,
7.25,
7.25,
7.51,
7.56,
7.74,
8.35,
8.51,
8.52,
8.58,
8.77,
9.55,
38.07,
38.73,
39.42,
40.17,
40.55,
41.19,
43.11,
44.3,
45.35,
48.17,
48.27,
48.33,
50.81]这些是异常值。
这些都是我今天想分享的检测异常值的方法。现在让我们看看如何处理异常值:
Dealing with Outliers
Removing the outliers
这是一种常见的方式。有时很容易从数据中删除异常值。
在这里,我删除了从最后一个百分位数计算中检测到的异常值:
no_outliers = [i for i in data if i not in outliers]让我们用 no_outliers 数据制作一个箱线图:
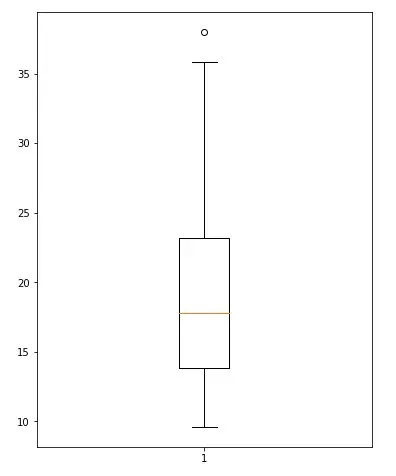
你可以看到异常值已经消失了。
基于百分比的地板和封顶
在最后的异常值检测方法中,计算了第 5 和第 95 个百分位数以找到异常值。您也可以使用这些百分位数来处理异常值。
低于第五个百分位的数据可以用第五个百分位代替,高于第95个百分位的数据可以用第95个百分位值代替。
data_fixed = np.where(data < tenth_perc, tenth_perc, data)
data_fixed = np.where(data_fixed > nineteeth_perc, nineteeth_perc, data_fixed)让我们再次查看带有新 data_fixed 的箱线图
plt.figure(figsize = (6, 8))
plt.boxplot(data_fixed)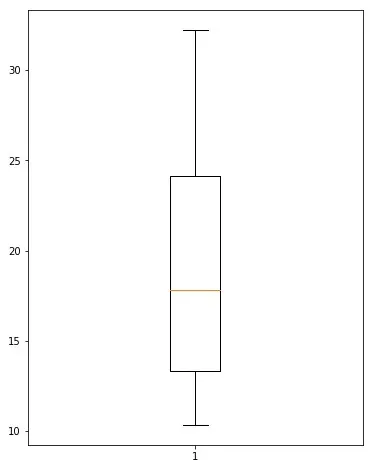
No more outliers.
Binning
对数据进行分箱并对它们进行分类将完全避免异常值。相反,它将使数据分类。
df['total_bill'] = pd.cut(df['total_bill'], bins = [0, 10, 20, 30, 40, 55], labels = ['Very Low', 'Low', 'Average', 'High', 'Very High'])
df['total_bill']Output:
0 Low
1 Low
2 Average
3 Average
4 Average
...
239 Average
240 Average
241 Average
242 Low
243 Low
Name: total_bill, Length: 244, dtype: category
Categories (5, object): ['Very Low' < 'Low' < 'Average' < 'High' < 'Very High']total_bill 列不再是连续变量。它现在是一个分类变量。
Considering Null Values
处理异常值的另一种方法是将它们视为空值并使用填充空值的技术来填充它们。在这里,您将找到处理空值的提示:
Conclusion
本文想重点介绍检测异常值的方法和处理它们的技巧。我希望这可以帮到你。如果您发现任何其他更有用的方法,请随时在评论部分分享。
More Reading
文章出处登录后可见!