了解 MixNMatch:创建更逼真的合成图像
将多个真实图像中的不同因素组合成单个合成图像
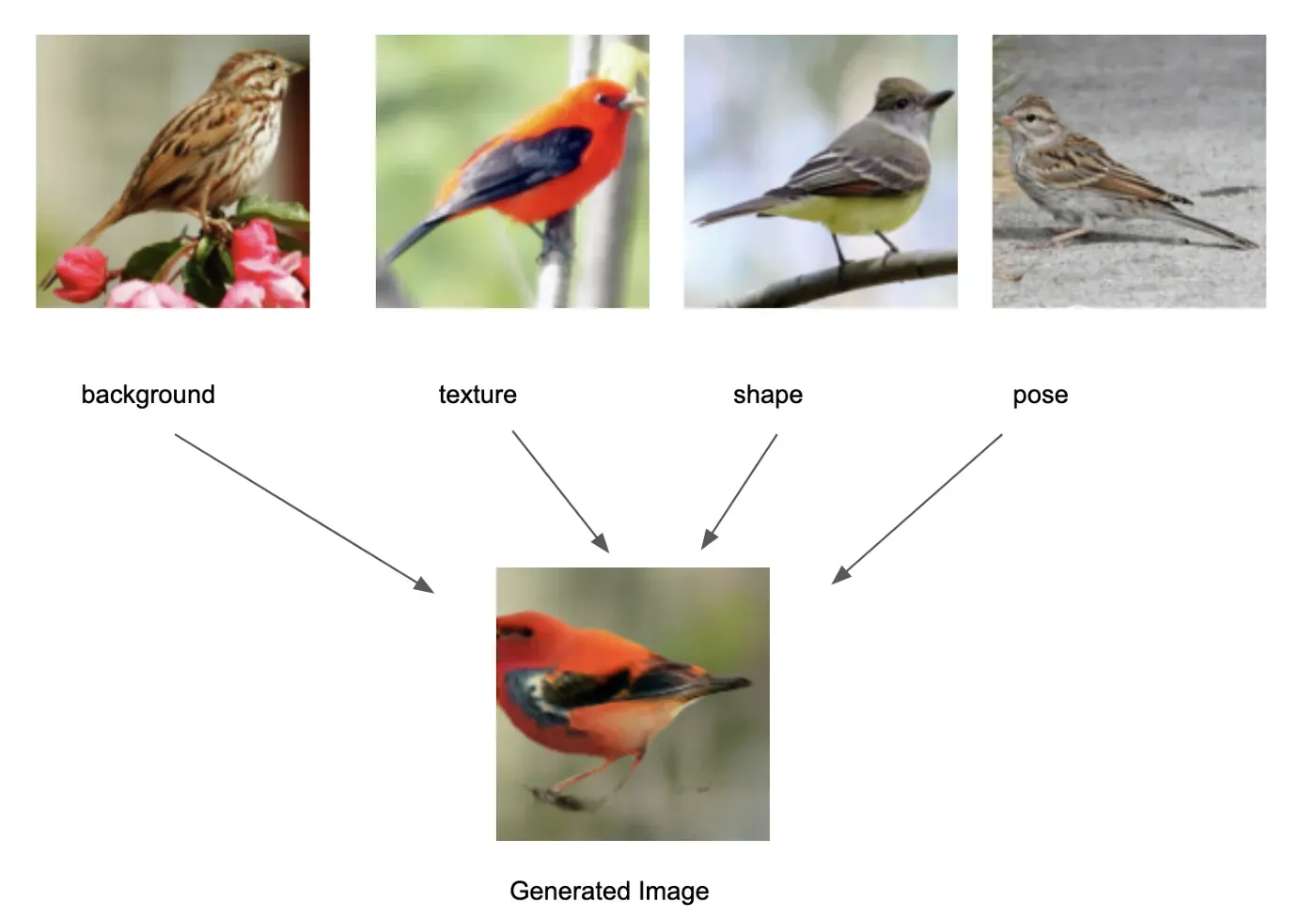
我最近偶然发现了这篇名为 MixNMatch 的论文,该论文旨在将多个真实图像中的不同因素组合成一个合成图像——只需最少的监督。这篇文章旨在详细说明,并且需要一些深度学习和生成模型的背景知识。如果您正在寻找 TLDR;它的版本,你可以在这里查看我的推特线程。[0][1]
如果您喜欢这篇文章,请与您的网络分享。
Summary
MixNMatch 的核心是使用条件生成对抗网络 (GAN) 的条件图像生成技术。 MixNMatch 将来自不同真实图像的多个因素解开并编码为单个合成图像。具体来说——它将来自不同真实图像的图像背景、姿势、形状和纹理组合成单个合成图像,而监督最少。
在训练过程中,MixNMatch 只需要在对象周围有一个松散的边界框来模拟背景,但不需要对象的姿势、形状或纹理。
Problem
在最少的监督下学习解开的表示是一个极具挑战性的问题,因为产生数据的潜在因素通常是高度相关和交织在一起的。
- 有大量工作通过获取两个输入参考图像来解开两个因素。例如,一张用于外观参考图像,另一张用于姿势参考图像。但他们无法解开其他因素,例如前景与背景外观或姿势与形状。由于只能控制两个因素,因此这些方法不能随意改变对象的背景、形状和纹理,同时保持其姿势不变。
- 另一组工作需要以关键点/掩码注释的形式进行强有力的监督;限制了它们的可扩展性,并且仍然无法解开 MixNMatch 中列出的所有四个因素
Main Idea
MixNMatch 学习在最小的监督下从真实图像中分离和编码背景、物体姿势、形状和纹理潜在因素。为了实现这一点,他们提出了一个可以同时学习的框架
- 一个编码器,将来自真实图像的潜在因素编码到一个解开的潜在代码空间中,以及
- 一个生成器,它从解开的代码空间中获取潜在因素以生成图像。
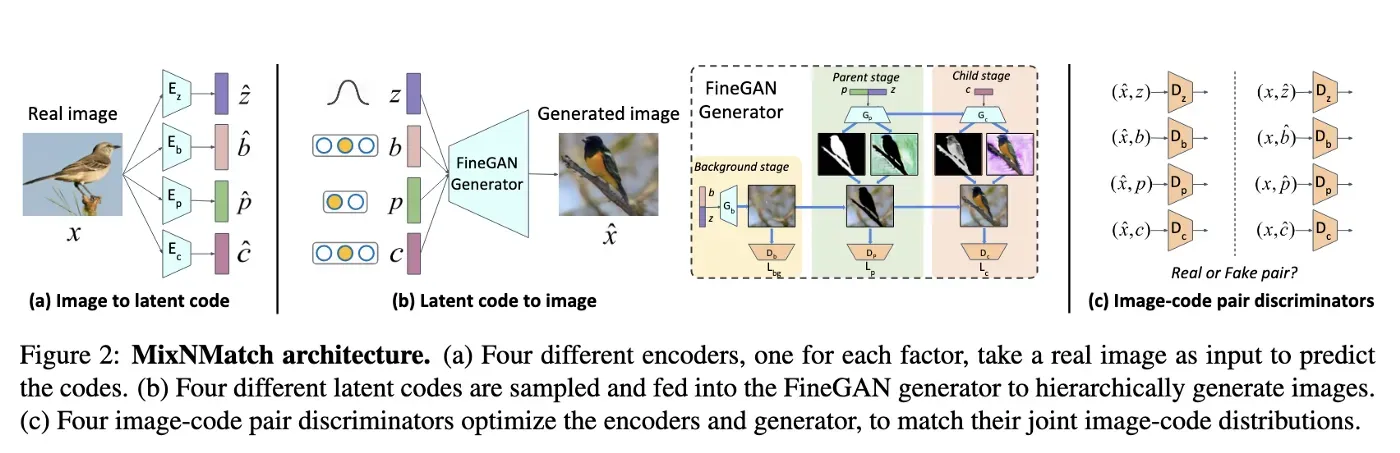
MixNMatch 的生成器建立在 FineGAN 的基础上——一种生成模型,它学习使用信息论在最少的监督下分层解开背景、物体姿势、形状和纹理。[0]
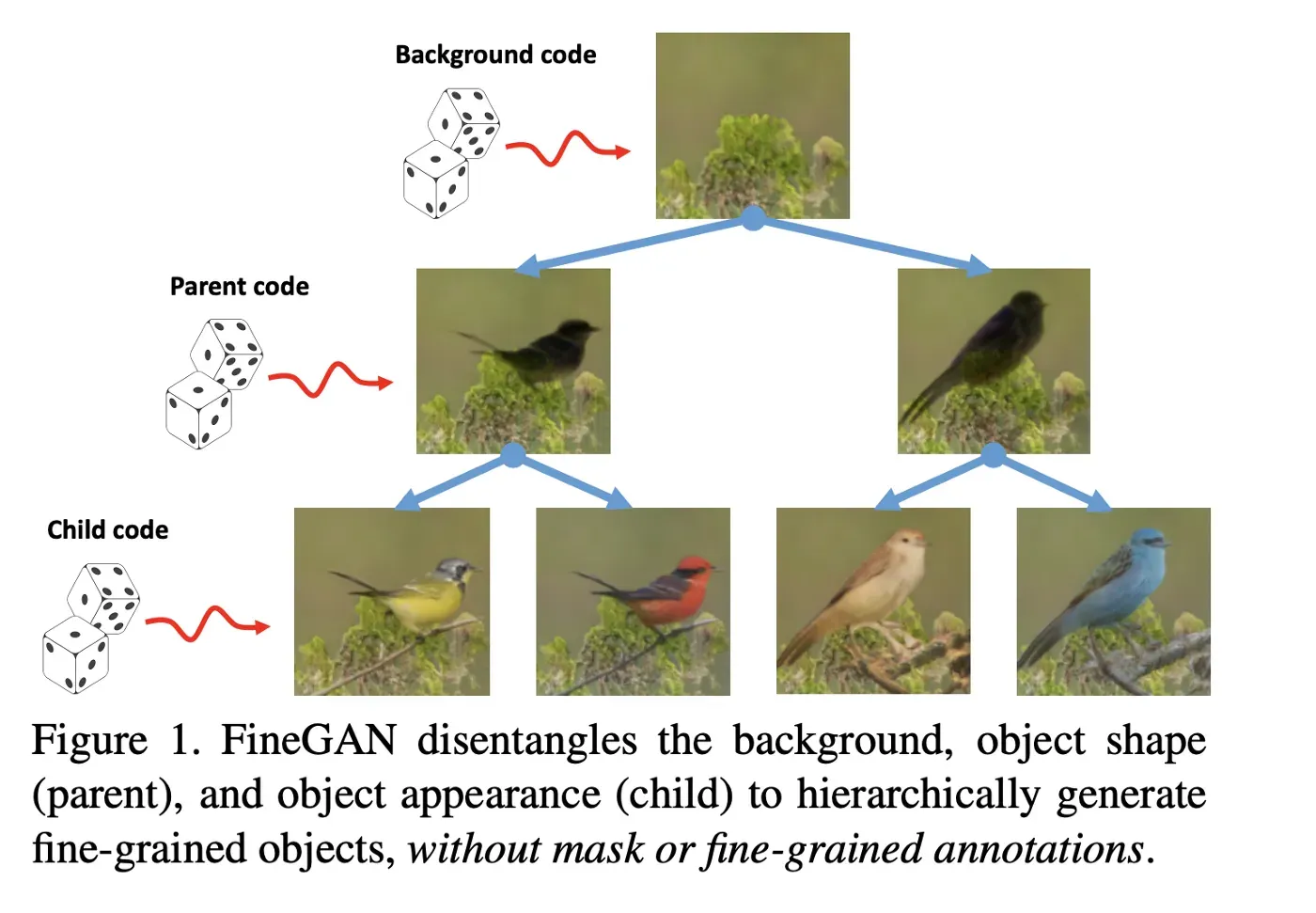
然而,FineGAN 仅以采样的潜在代码为条件,不能直接以真实图像为条件进行图像生成。因此,我们需要一种方法来从真实图像中提取控制背景、对象姿势、形状和纹理的潜在代码,同时保留 FineGAN 的分层解缠结属性。那么我们有哪些选择呢?
- FineGAN 的朴素扩展;意义——训练编码器将假图像映射到潜在代码。由于真实和虚假图像之间的域差距,这将不起作用
- 执行对抗学习,其中真实图像的联合分布及其从编码器提取的潜在代码,以及采样的潜在代码和生成器生成的相应图像的联合分布,被学习为不可区分,类似于 ALI 和 BiGAN
对抗性学习方法的优势是什么?
通过强制执行匹配的联合图像代码分布,编码器学习生成将采样代码的分布与所需解缠结属性相匹配的潜在代码,而生成器则学习生成逼真的图像。
更具体地说,对于每个真实图像 x,作者提出了四个独立的编码器来提取其 z、b、p、c 代码。但是,您不想将这些代码直接放到生成器中来重建图像。因为这会将这个模型变成一个“简单”的自动编码器。这并没有保留 FineGAN 的解缠结特性(分解为背景、姿势、形状、纹理)。因此,作者利用 ALI 和 BiGAN 的想法来帮助编码器学习逆映射;即,从真实图像到代码空间的投影,以保持所需的解缠结属性的方式。
Approach
由于 MixNMatch 基于 FineGAN,让我们先快速回顾一下 FineGAN 的工作原理。
How FineGAN works
作为输入,FineGAN 采用四个随机采样的嵌入,也就是。潜在代码(z,b,c,p)如图 2 所示。然后它分三个阶段分层生成图像(图 3)。
- 阶段 1:模型仅生成背景的背景阶段,以潜在的 one-hot 背景代码 b 为条件
- 阶段 2:模型生成对象形状的父阶段
以潜在的 one-hot 父代码 p 和连续代码 z 为条件,并将其缝合到现有的背景图像 - 阶段 3:模型填充对象纹理的子阶段,以潜在的 one-hot 子代码 c 为条件
在父子阶段,FineGAN 还生成对象的掩码以在没有监督的情况下捕获形状和纹理。
在训练期间,FineGAN 强制执行两个约束
- 约束 #1:它将子代码分组到一个不相交的集合中,因此每个集合都包含相同的父代码。该约束强制例如不同的鸭子香料将具有相同的形状但不同的质地。
- 约束 #2:它还强制对于每个生成的图像,子代码和背景代码对总是相同的——这意味着鸭子总是有水的背景
FineGAN 如何解开不同的特征?
- 为了解开背景,FineGAN 依赖于对象的边界框。
- 为了解开其他因素,FineGAN 依赖于 InfoGAN [5] 中的信息论,并在潜在代码的关系之间施加约束。
MixNMatch 与 FineGAN 有何不同
MixNMatch 的主要思想是进行对抗学习,使编码器产生的成对图像代码分布和生成器产生的成对图像代码分布相匹配。 MixNMatch 判别器的输入是一个图像代码对。
MixNMatch 中的解缠结是如何工作的
FineGAN 施加的约束对于真实图像可能很困难。如果您查看约束 #2,您会意识到它可能并不总是成立。例如——鸭子可能并不总是在水中。因此,为了绕过约束 #2,作者采用以下步骤
- 训练四个单独的鉴别器,每个代码类型一个。这可以防止任何鉴别器看到其他代码,因此无法根据代码之间的关系进行区分。
- 在训练编码器时,使用随机采样代码生成的假图像也作为输入提供。这些随机采样的代码已删除这些约束。这意味着,在这些生成的图像中,任何前景纹理都可以与任意背景和任意形状相结合。
如何捕捉准确的姿势和形状
到目前为止,我们已经了解了 MixNMatch 如何解开图像的 4 个不同方面并将它们编码到代码中。 MixNMatch 的生成器然后结合这 4 个因素来生成“逼真的”合成图像。作者将此过程称为“代码模式”。
但是“代码模式”不能保留某些应用所需的精确像素级姿势和形状。为什么它不能保留精确的像素级?因为姿势/形状的潜在代码维度不足以捕获那些细粒度的特征。为了克服这个问题——作者引入了一种叫做“特征模式”的东西
关键思想不是将参考图像编码为低维形状代码,而是直接学习从图像到更高维特征空间的映射,以保留参考图像的空间对齐形状和姿势(像素级)细节。
您可以在本文的第 3.4 节中找到更多相关信息。
References
- Krishna Kumar Singh、Utkarsh Ojha 和 Yong Jae Lee。用于细粒度对象生成和发现的无监督分层解缠结。在 CVPR,2019 年。
- 杰夫·多纳休、菲利普·克伦布尔和特雷弗·达雷尔。对抗性特征学习。在 ICLR,2017 年。
- Vincent Dumoulin、Ishmael Belghazi、Ben Poole、Alex Lamb、Martin Arjovsky、Olivier Mastropietro 和 Aaron Courville。对抗性学习推理。在 ICLR,2017 年
- Mehdi Mirza, Simon Osindero 条件生成对抗网络[0][1]
- Xi Chen、Yan Duan、Rein Houthooft、John Schulman、Ilya Sutskever 和 Pieter Abbeel。 Infogan:通过信息最大化生成对抗网络的可解释表示学习。在 NeurIPS,2016 年。
文章出处登录后可见!