

如何打造 AI 时装设计师
使用 StyleGAN 和 GANSpace 进行时装设计的服装语义编辑


Overview
这是我的旧项目 ClothingGAN 的一篇文章。该项目使用 StyleGAN 使用 AI 生成服装设计,并使用袖子、尺寸、连衣裙、夹克等属性对其进行语义编辑。您还可以通过首先生成 2 种不同的服装设计(输出 1)进行风格转换,如上图所示具有不同的种子数。然后,它将生成混合前 2 个设计的第三个设计(输出 2)。然后,您可以调整希望它从两个原始设计继承多少样式或结构。[0]
Outline
- Inspiration
- 我是如何建造的
- Training StyleGAN model
- 使用 GANSpace 进行语义编辑
- 使用 Gradio 构建 UI
- 部署到 HuggingFace 空间
Inspiration
GAN 或 Generative Adversarial Network 是一种生成模型,能够通过学习大型图像数据集的概率分布来生成图像。我总是觉得 GAN 很吸引人,因为即使没有绘画的技术或艺术技巧,它也能让我产生高质量的艺术或设计。最近,我看到了很多关于 GAN 的人脸编辑演示,但很少在其他数据集中看到语义操作。因此,我创建了 ClothingGAN 应用程序,您可以在其中使用 AI 协作设计衣服,而无需高超的技术专长。
我是如何建造的
第一步是有一个可以生成服装的生成模型。我没有找到可以生成质量不错的图像的公共模型,因此我决定使用 StyleGAN 训练我自己的 GAN 服装模型。然后我使用了基于潜在空间的语义编辑方法 GANSpace 来提供编辑功能。它在 GAN 潜在空间中找到可能代表某些视觉属性的重要方向,然后我手动标记这些属性。最后,我使用 Gradio 库构建了演示界面并将其部署到 HuggingFace Space。
Training StyleGAN model
我在项目时使用了 StyleGAN2-ADA[2] 模型,最新的 StyleGAN 模型是 StyleGAN2-ADA 模型。但是,您可能想要使用当前最新版本,即 StyleGAN3。虽然我不确定 StyleGAN3 与我的方法或我正在使用的其他库的兼容性如何。
为了训练模型,我使用了 Donggeun Yoo 在 PixelDTGAN [1] 论文中创建的服装数据集。该数据集包含 84,748 张图像,其中包括 9,732 张具有干净背景的上衣图像,这些图像与其余 75,016 张时装模特图像相关联。我只使用图像干净背景的服装图像。因此,用于训练 StyleGAN 模型的总图像约为 9k 图像,分辨率为 512×512。这是作者网站上共享的数据集的链接。 PixelDTGAN 论文受 MIT 许可。[0][1][2]

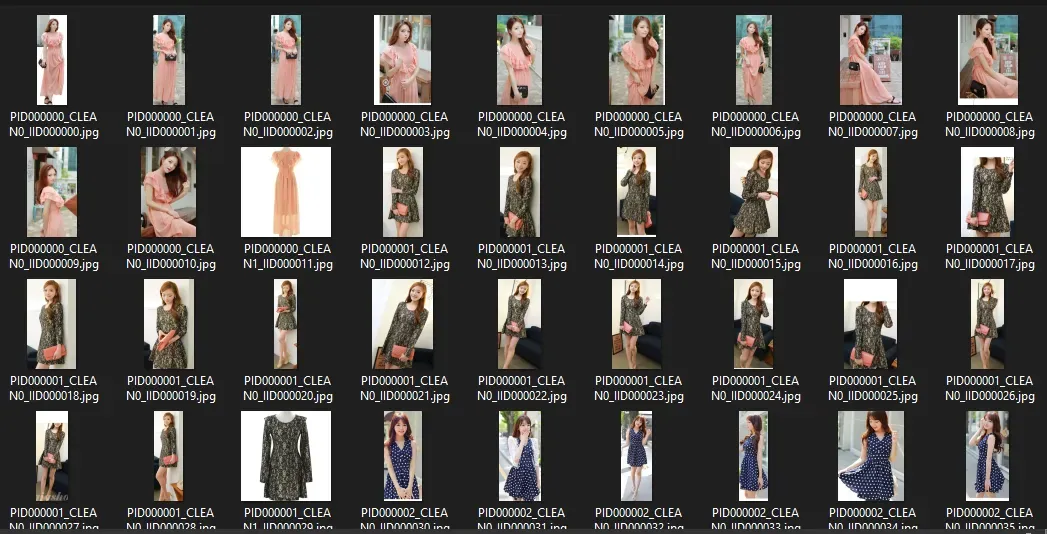
我不会讨论如何训练模型的确切步骤,因为我之前已经写过一篇关于这个主题的文章。只需对选定的数据集执行相同的步骤。
这是训练后的结果。




使用 GANSpace 进行语义编辑
语义图像编辑是修改给定源图像中的语义属性(例如样式或结构)的任务。例如,修改一个人的头发颜色,同时保留该人的身份。图像编辑的应用范围广泛,从照片增强、用于艺术和设计目的的样式处理到数据增强。语义图像编辑通常有两个目标:允许同时连续操作多个属性,并尽可能地保留源图像的身份,同时保持图像的真实性。
使用 GAN 进行语义图像编辑的现有方法主要可分为图像空间编辑或潜在空间编辑。图像空间编辑学习直接将源图像转换为目标域中的另一个图像的网络。这些方法通常只允许二进制属性更改,而不是允许连续更改。这些方法的示例是 pix2pix、StarGAN 和 DRIT++。
相反,潜在空间编辑通过在 GAN 模型的潜在空间中操纵输入向量来间接操纵图像。这些方法主要集中于在潜在空间中寻找代表生成图像语义属性的路径。在这些路径中导航输入向量允许对属性进行连续编辑。
无监督、自我监督和监督的潜在空间编辑方法都已被提出。 GANSpace[3] 在潜在空间或特征空间中使用主成分分析 (PCA) 以无监督的方式找到重要方向。使用封闭形式分解(来自 SeFa 论文)也可以类似地找到重要方向。自监督方法也能够在没有标签的情况下找到这些方向,因为它们会生成自己的标签,但通常仅限于几何属性,例如旋转或缩放。另一方面,诸如 InterfaceGAN 之类的监督方法需要标签信息或属性分类器。[0]
GANSpace[3] 讨论了使用预训练的 GAN 模型对生成的图像进行样式设置。 GAN 模型学习将噪声分布 z 映射到图像分布的函数。因此,给定不同的噪声输入 z,生成的输出将不同。然而,深度学习模型往往是一个黑匣子,并不清楚噪声输入与生成输出之间的关系,因此无法明确控制输出。然而,GAN 模型可以在给定类标签的情况下生成特定类输出,如条件 GAN 中所研究的那样。但是,在训练期间需要数据集的标签信息来调节 GAN 模型,这在某些情况下可能不可行。[0]
另一方面,GANSpace 的 [3] 论文提出,可以在 z 潜在空间中找到某些重要方向,这些方向表示生成的输出中的已知语义概念,例如输出的风格。为了找到这个方向,对几个样本观察中间层中的激活,并根据中间网络激活空间中的值计算 PCA 方向 v。然后,将方向v转移到z潜在空间中找到对应的方向u。整个过程如下图所示,取自 GANSpace 论文。

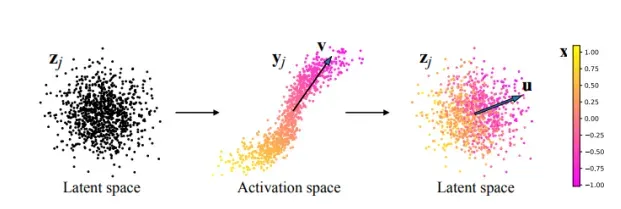
重要方向 u 可以在不同的层中计算,并且每一层中的方向可以代表不同的语义概念。在早期层中发现的方向通常代表高级特征,例如布料结构,而在最后几层中发现的方向通常代表低级特征,例如照明或颜色。通过在这些已知方向上操纵噪声输入 z,我们可以将生成的输出操纵到所需的特征。下图显示了将 GANSpace 方法应用于不同 GAN 模型时的操作结果。


在训练模型中查找方向
此处显示的代码是在 Google Colab 上测试的,您可以跟随我的笔记本或在您自己的环境中进行操作,但如果您在 Colab 环境之外进行操作,请确保您的环境具有预安装在 Colab 中的依赖项。[0]
如果您想跟随,这是教程笔记本[0]
首先,我们需要安装 GANSpace 所需的依赖项。
!pip install ninja gradio fbpca boto3 requests==2.23.0 urllib3==1.25.11`运行代码后重新启动运行时,然后克隆 GANSpace 存储库。
!git clone https://github.com/mfrashad/ClothingGAN.git%cd ClothingGAN/
运行以下代码以进行进一步设置。确保您位于 GANSpace 文件夹中。
!git submodule update --init --recursive!python -c "import nltk; nltk.download('wordnet')"
接下来,我们将不得不修改 GANSpace 代码以添加我们的自定义模型。对于 StyleGAN2,我们需要模型文件的 PyTorch 版本。由于我们的 StyleGAN 模型文件是 Tensorflow .pkl 格式的,我们需要使用 rosinality 制作的转换器将其更改为 pytorch 格式的 .pt 文件。只需按照本笔记本中的步骤操作即可。 (该项目在 StyleGAN2 PyTorch 官方版本实施之前完成,如果您的模型文件已经是 .pt 或 Pytorch 格式,您可以跳过此部分)。[0]
接下来,回到 GANspace 文件夹并修改 models/wrappers.py 以添加我们的模型文件。首先,转到 StyleGAN2 类并在配置变量中添加我们的模型名称和输出分辨率。

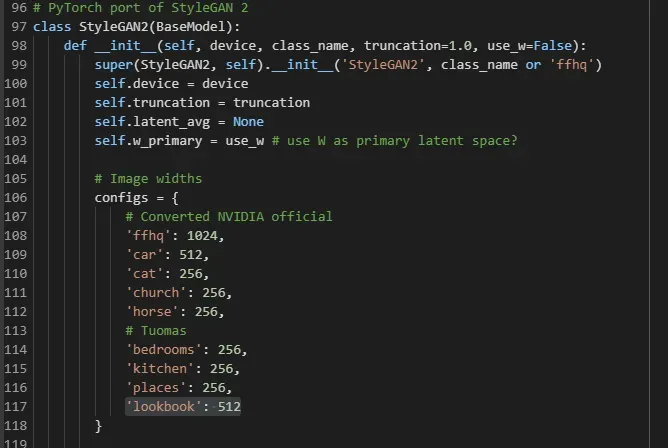
接下来,进一步向下滚动并在 checkpoints 变量中添加模型的链接。要生成我们模型的链接,只需将模型文件上传到 Google 驱动器并使用此站点生成指向它的直接链接。[0]

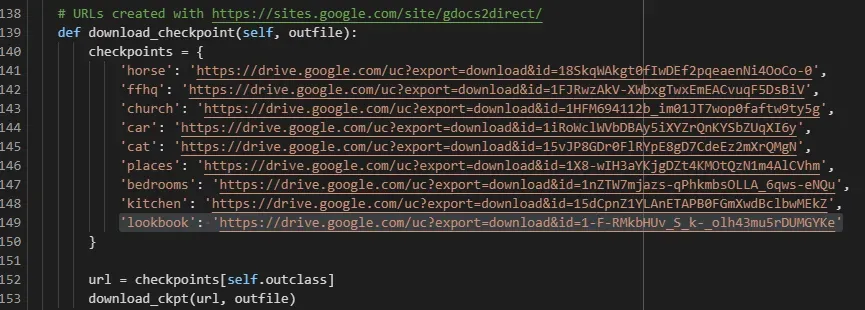
将模型添加到文件后。运行 Visualize.pyc 脚本以执行 PCA,并在将输入沿计算的主成分方向移动时可视化视觉变化。


–use_w 选项意味着我们将操纵中间潜在代码 w 而不是 StyleGAN 中的原始潜在代码 z。 num_components 用于指定要保留多少个方向或主成分。最大分量为 512 或 inputz 或 wdimension。 –video 选项是在主成分方向移动时生成视觉变化的视频,而不仅仅是生成图像。该脚本可能需要大约 30 分钟才能完成。
完成后,它将在 out 文件夹中生成可视化的更改。就我而言,它位于 out/StyleGAN2-lookbook 文件夹下。

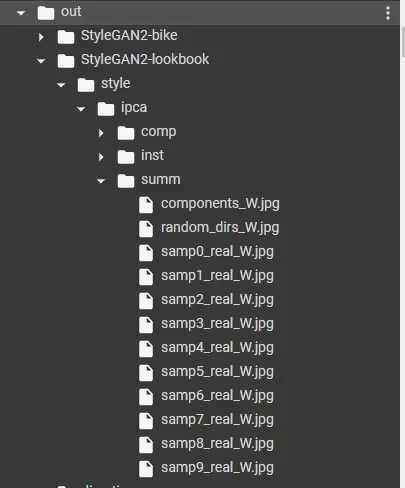
我们将看一下 style/ipca/summ/components_W.jpg,因为它可视化了前 14 个主成分。


从上图中,我们可以开始选择要放入演示中的主要组件并标记它们。例如,我认为C0可以标记为袖长,C1可以标记为夹克,C2和C3可以标记为外套,C4和C5可以标记为衣服的亮度,C6可以标记为较短的衣服。
您还可以在附加文件 sampX_real_W.jpg 中查看不同样本的可视化效果,以确保主成分引起的变化在不同样本之间保持一致。 Visualize.py 脚本生成了 9 个额外的示例。
这是另一个示例的可视化。

您可以看到,即使使用不同的样本(C0 作为袖长,C1 作为夹克等),这些变化也大致一致。
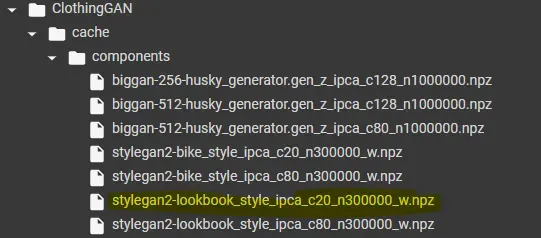
此外,您还可以在 comp 或 inst 文件夹中以视频的形式查看每个组件的可视化。主成分本身以 .npz 格式保存在 cache/components/ 文件夹中

一旦我们有了组件,我们就可以开始构建演示 UI。
使用 Gradio 构建 UI
Gradio 是一个 python 库,只需几行代码,就可以非常轻松地为 ML 项目构建 UI/demo。以下是 Gradio 的简单示例:[0]

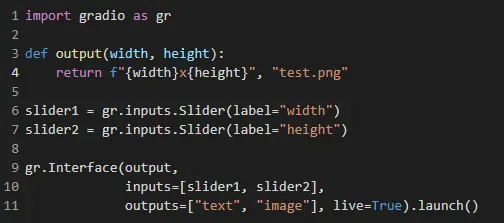

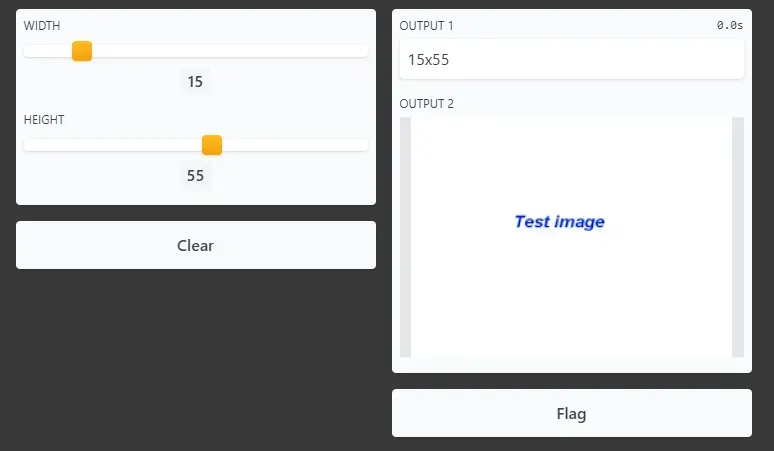
当您想将 ML 应用程序演示为单个函数时,Gradio 非常适合。
首先,我们需要将生成器模型以及主要组件加载到内存中。
#@title Load Model
# The model name, change this only
selected_model = 'lookbook'
# Load model
import torch
import numpy as np
from PIL import Image
from models import get_instrumented_model
from decomposition import get_or_compute
from config import Config
# Speed up computation
torch.autograd.set_grad_enabled(False)
torch.backends.cudnn.benchmark = True
# Specify model to use
config = Config(
model='StyleGAN2',
layer='style',
output_class=selected_model,
components=20,
use_w=True,
batch_size=5_000, # style layer quite small
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
inst = get_instrumented_model(config.model, config.output_class,
config.layer, device, use_w=config.use_w)
path_to_components = get_or_compute(config, inst)
model = inst.model
comps = np.load(path_to_components)
lst = comps.files
latent_dirs = []
latent_stdevs = []
load_activations = False
for item in lst:
if load_activations:
if item == 'act_comp':
for i in range(comps[item].shape[0]):
latent_dirs.append(comps[item][i])
if item == 'act_stdev':
for i in range(comps[item].shape[0]):
latent_stdevs.append(comps[item][i])
else:
if item == 'lat_comp':
for i in range(comps[item].shape[0]):
latent_dirs.append(comps[item][i])
if item == 'lat_stdev':
for i in range(comps[item].shape[0]):
latent_stdevs.append(comps[item][i])然后,我们将定义一个效用函数来操纵指定方向上的 w 输入并使用生成器生成图像。
#@title Define functions
def display_sample_pytorch(seed, truncation, directions, distances, scale, start, end, w=None, disp=True, save=None, noise_spec=None):
# blockPrint()
model.truncation = truncation
if w is None:
w = model.sample_latent(1, seed=seed).detach().cpu().numpy()
w = [w]*model.get_max_latents() # one per layer
else:
w = [np.expand_dims(x, 0) for x in w]
for l in range(start, end):
for i in range(len(directions)):
w[l] = w[l] + directions[i] * distances[i] * scale
torch.cuda.empty_cache()
#save image and display
out = model.sample_np(w)
final_im = Image.fromarray((out * 255).astype(np.uint8)).resize((500,500),Image.LANCZOS)
if save is not None:
if disp == False:
print(save)
final_im.save(f'out/{seed}_{save:05}.png')
if disp:
display(final_im)
return final_im最后,我们可以定义主函数 generate_image 并使用 Gradio 库为该函数构建 UI。
#@title Demo UI
import gradio as gr
import numpy as np
def generate_image(seed, c0, c1, c2, c3, c4, c5, c6):
seed = int(seed)
params = {'c0': c0,
'c1': c1,
'c2': c2,
'c3': c3,
'c4': c4,
'c5': c5,
'c6': c6}
# Assigns slider to the principal components
param_indexes = {'c0': 0,
'c1': 1,
'c2': 2,
'c3': 3,
'c4': 4,
'c5': 5,
'c6': 6}
# Save the values from the sliders
directions = []
distances = []
for k, v in params.items():
directions.append(latent_dirs[param_indexes[k]])
distances.append(v)
# Additional settings for image generation
start_layer = 0
end_layer = 14
truncation = 0.5
return display_sample_pytorch(seed, truncation, directions, distances, scale, int(start_layer), int(end_layer), disp=False)
# Create a number input for seed
seed = gr.inputs.Number(default=0, label="Seed 1")
slider_max_val = 20
slider_min_val = -20
slider_step = 1
# Create the sliders input
c0 = gr.inputs.Slider(label="Sleeve & Size", minimum=slider_min_val, maximum=slider_max_val, default=0)
c1 = gr.inputs.Slider(label="Dress - Jacket", minimum=slider_min_val, maximum=slider_max_val, default=0)
c2 = gr.inputs.Slider(label="Female Coat", minimum=slider_min_val, maximum=slider_max_val, default=0)
c3 = gr.inputs.Slider(label="Coat", minimum=slider_min_val, maximum=slider_max_val, default=0)
c4 = gr.inputs.Slider(label="Graphics", minimum=slider_min_val, maximum=slider_max_val, default=0)
c5 = gr.inputs.Slider(label="Dark", minimum=slider_min_val, maximum=slider_max_val, default=0)
c6 = gr.inputs.Slider(label="Less Cleavage", minimum=slider_min_val, maximum=slider_max_val, default=0)
inputs = [seed, c0, c1, c2, c3, c4, c5, c6]
# Launch demo
gr.Interface(generate_image, inputs, ["image"], live=True, title="ClothingGAN").launch(debug=True)这就是结果!

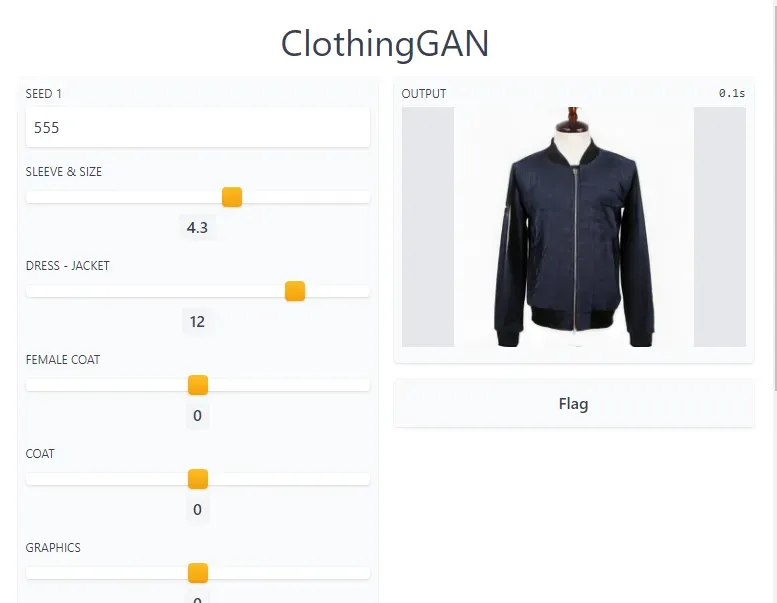
Gradio 还将提供一个链接,您可以将其分享给您的朋友或其他任何人可以尝试演示的地方。但是,演示的托管不是永久性的,Colab 服务器会在 12 或 24 小时内自行终止。对于永久托管,您可以简单地在云或您自己的服务器中运行代码。但幸运的是,Hugging Face 创造了 Spaces,一个平台,您可以简单地上传您的 ML 应用程序并免费永久托管它(如果您想要 GPU,则需要付费)。此外,它还可以很好地与 Gradio 和 Streamlit 集成,并且开箱即用。[0]
部署到 HuggingFace 空间
首先,前往 Spaces 并登录/注册您的帐户。然后单击“创建新空间”。[0]

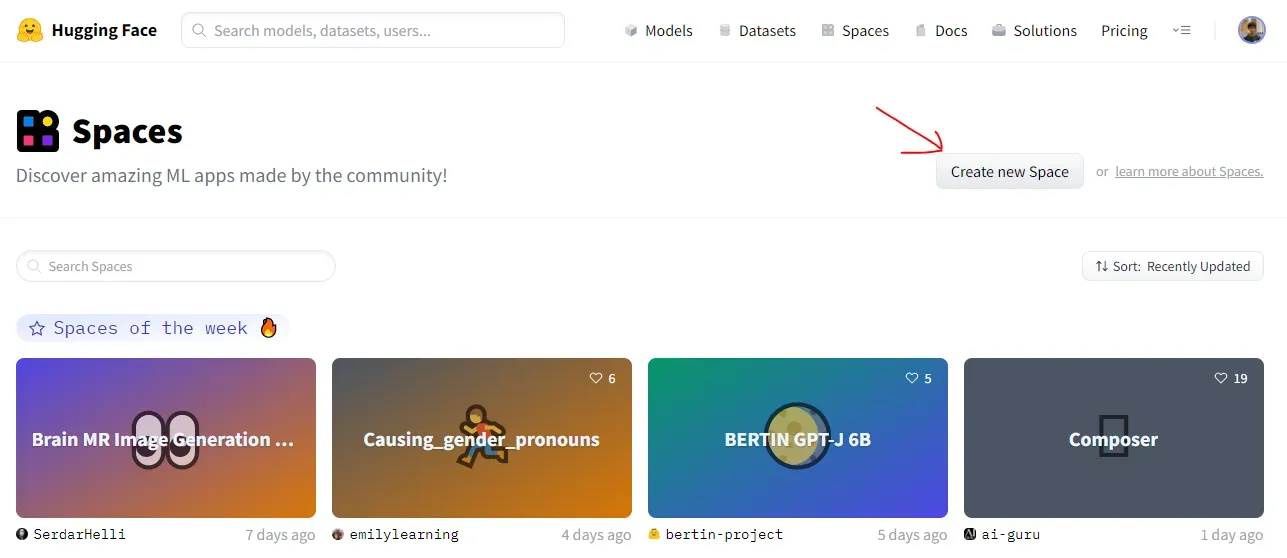
然后,选择您想要的名称和许可证,并选择 Gradio 作为空间 SDK。

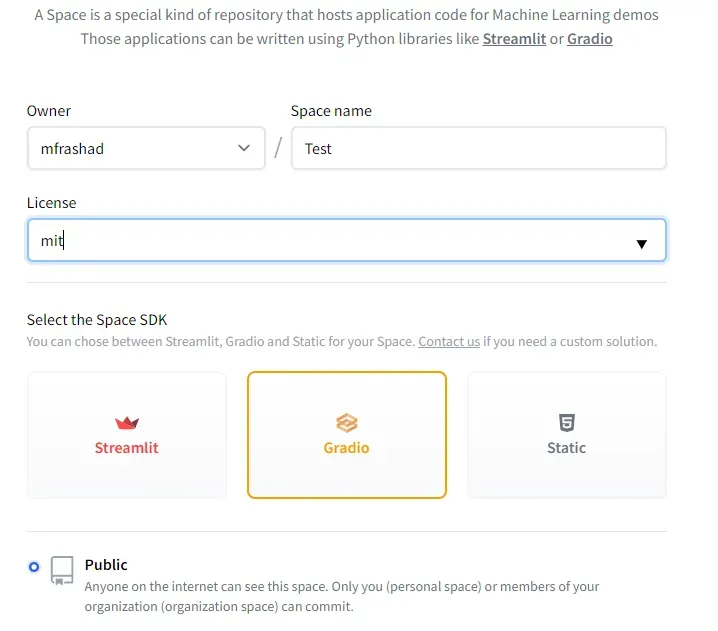
接下来,克隆拥抱脸回购。

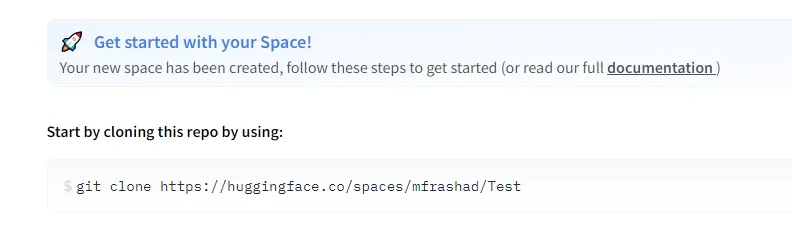
就个人而言,我在推送到 repo 时遇到了身份验证问题,我必须通过将远程 URL 设置为以下方式来使用令牌作为身份验证方法:
https://HF_TOKEN@huggingface.co/spaces/mfrashad/Test或者您也可以使用 URL 中您的拥抱脸帐户的用户名和密码进行身份验证。
https://HF_USERNAME:PASSWORD@huggingface.co/spaces/mfrashad/Test克隆后,我们可以开始创建演示所需的文件。 Spaces repo 中有 3 个重要的文件:requirements.txt 指定要使用 pip install 安装的所有 python 依赖项,packages.txt 指定要使用 apt install 安装的依赖项,以及主 python文件 app.py 应该包含您的 Gradio 演示代码。
此外,您需要使用 git-lfs 将任何二进制文件上传到 repo,例如图像。
所以我所做的只是将 Colab 中的所有代码复制到 Spaces 存储库中。删除演示不需要的图像、二进制文件和文件。将我们 notebook 中的所有 python 代码放入一个 python 文件 app.py 中。然后创建 requirements.txt 和 packages.txt 。完成后,只需 git push 即可!该演示将在 Hugging Face Space 中提供,任何人都可以尝试(假设您没有收到任何错误)。
有关代码的完整内容,您可以查看 ClothingGAN Space 存储库中的文件。[0]

恭喜!您设法一直阅读到这一点,并希望设法完成所有工作。对于更多挑战,您可以尝试训练自己的 StyleGAN 模型并应用语义编辑。例如,我也将相同的方法应用于角色和时装模特的生成。
你可以在这里尝试 CharacterGAN 的演示。[0]


如果您喜欢阅读此类教程并希望支持我作为作家,请考虑注册成为 Medium 会员。每月 5 美元,让您可以无限制地访问 Medium 上的故事。如果您使用我的链接注册,我将赚取少量佣金。
另外,看看我的其他故事。
Reference
[1] Yoo, D.、Kim, N.、Park, S.、Paek, A. S. 和 Kweon, I. S.(2016 年 10 月)。像素级域转移。在欧洲计算机视觉会议上(第 517-532 页)。施普林格,湛。
[2] Karras, T.、Aittala, M.、Hellsten, J.、Laine, S.、Lehtinen, J. 和 Aila, T. (2020)。用有限的数据训练生成对抗网络
[3] Härkönen, E.、Hertzmann, A.、Lehtinen, J. 和 Paris, S. (2020)。 Ganspace:发现可解释的 gan 控件。神经信息处理系统的进展,33, 9841–9850。
文章出处登录后可见!