目录
一、numpy基本介绍
1、什么是numpy
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
2、numpy的数据结构
numpy的数据结构是ndarray,它是一种N维的数组类型,它描述了相同类型的“items”的集合,同时在ndarray中的数据类型都是相同的因此他含有的数据类型相同,因此numpy运算的数据的速度非常的快。
3、numpy数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。
| 名称 | 描述 |
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型 |
| intp | 用于索引的整数类型 |
| … | … |
4、numpy数组的属性
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
| 属性 | 说明 |
| ndarray.ndim() | 秩,即轴的数量或维度的数量 |
| ndarray.shape() | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size() | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype() | ndarray 对象的元素类型 |
| ndarray.itemsize() | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags() | ndarray 对象的内存信息 |
| ndarray.real() | ndarray元素的实部 |
| ndarray.imag() | ndarray 元素的虚部 |
| ndarray.data() | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
5、numpy常用函数
(1)常用创建函数
| 函数名 | 作用 |
| np.ndarray() | 创建数组 |
| np.arange(n) | 元素从0到n-1的ndarray类型 |
| np.ones(shape) | 根据shape生成一个全1数组,shape是元组类型 |
| np.zeros((shape) | 根据shape生成一个全0数组,shape是元组类型 |
| np.full(shape, val) | 根据shape生成一个数组,每个元素值都是val |
| np.eye(n) | 创建一个正方的n*n单位矩阵,对角线为1,其余为0 |
| np.ones_like(a) | 根据数组array_03的形状生成一个全1数组 |
| np.zeros_like(a) | 根据数组a的形状生成一个全0数组 |
| np.full_like(array_03,99) | 根据数组a的形状生成一个数组,每个元素值都是val |
| np.linspace(1,10,10) | 根据起止数据等间距地填充数据,形成数组 |
| np.concatenate((a, b), axis=0) | 纵向连接 # 将两个或多个数组合并成一个新的数组 |
注:shape是形状即假设shape是(2,3)他所生成的矩阵就是2行3列的形状,后面shape都是一样的意思。
(2)常用的转换函数
①数组维度转换
| 函数 | 作用 |
| np.reshape(shape) | 不改变数组元素,返回一个shape形状的数组,原数组a不变9 |
| np.resize(shape) | 改变数组的shape,且修改原数组 |
| np.swapaxes(ax1, ax2) | 将两个维度调换 |
| np.flatten() | 把数组的维度降低,返回折叠后的一维数组,原数组不变 |
②数组类型转换
| 函数 | 作用 |
| b.astype(np.int16) | astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致 |
| b.tolist() | 转换成list类型 |
注:b是变量名,不是定义的numpy名称,为了方便大家都会对numpy as为np
(3)数组的运算
| 函数 | 作用 |
| np.abs(a) | 取各元素的绝对值 |
| np.sqrt(a) | 计算各元素的平方根 |
| np.square(a) | 计算各元素的平方 |
| np.log(a) np.log10(a) np.log2(a) | 计算各元素的自然对数、10、2为底的对数 |
| np.ceil(a) np.floor(a) | 计算各元素的ceiling 值, floor值(ceiling向上取整,floor向下取整) |
| np.rint(a) | 各元素 四舍五入 |
| np.modf(a) | 将数组各元素的小数和整数部分以两个独立数组形式返回 |
| np.exp(a) | 计算各元素的指数值 |
| np.sign(a) | 计算各元素的符号值 1(+),0,-1(-) |
| np.maximum(a, b) np.fmax() | 比较(或者计算)元素级的最大值 |
| np.minimum(a, b) np.fmin() | 取最小值 |
| np.mod(a, b) | 元素级的模运算 |
| np.copysign(a, b) | 将b中各元素的符号赋值给数组a的对应元素 |
(4)CSV文件存取
np.savetxt(frame, array, fmt=’% .18e’, delimiter = None): frame是文件、字符串等,可以是.gz .bz2的压缩文件; array 表示存入的数组; fmt 表示元素的格式
np.loadtxt(frame, dtype=np.float, delimiter = None, unpack = False) : frame是文件、字符串等,可以是.gz .bz2的压缩文件;dtype:数据类型,读取的数据以此类型存储;delimiter: 分割字符串,默认是空格; unpack: 如果为True,读入属性将分别写入不同变量。
(5)多维数据存取
| 函数 | |
| a.tofile(frame, sep=’’, format=’%s’ ) | frame: 文件、字符串; sep: 数据分割字符串,如果是空串,写入文件为二进制 ; format:: 写入数据的格式 |
| np.fromfile(frame, dtype = float, count=-1, sep=’’) | frame: 文件、字符串 ; dtype: 读取的数据以此类型存储; count:读入元素个数, -1表示读入整个文件; sep: 数据分割字符串,如果是空串,写入文件为二进制 |
| np.save(frame, array) | frame: 文件名,以.npy为扩展名,压缩扩展名为.npz ; array为数组变量 |
| np.load(fname) | frame: 文件名,以.npy为扩展名,压缩扩展名 |
注:
a.tofile() 和np.fromfile()要配合使用,要知道数据的类型和维度
np.save() 和np.load() 使用时,不用自己考虑数据类型和维度
(6)随机数函数
| 函数 | 作用 |
| np.random.rand(d0, d1, …,dn) | 各元素是[0, 1)的浮点数,服从均匀分布 |
| np.random.randn(d0, d1, …,dn) | 标准正态分布 |
| np.random.randint(low,high,(shape)) | 依shape创建随机整数或整数数组,范围是[ low, high) |
| np.random.seed(s) | 随机数种子 |
| np.random.shuffle(a) | 根据数组a的第一轴进行随机排列,改变数组a |
| np.random.permutation(a) | 根据数组a的第一轴进行随机排列, 但是不改变原数组,将生成新数组 |
| np.random.choice(a[, size, replace, p]) | 从一维数组a中以概率p抽取元素, 形成size形状新数组,replace表示是否可以重用元素,默认为False。 |
(7)梯度函数
np.gradient(a) : 计算数组a中元素的梯度,f为多维时,返回每个维度的梯度
离散梯度: xy坐标轴连续三个x轴坐标对应的y轴值:a, b, c 其中b的梯度是(c-a)/2
而c的梯度是: (c-b)/1
当为二维数组时,np.gradient(a) 得出两个数组,第一个数组对应最外层维度的梯度,第二个数组对应第二层维度的梯度。
(8)统计函数
| 函数 | 作用 |
| sum(a, axis = None) | 依给定轴axis计算数组a相关元素之和,axis为整数或者元组 |
| mean(a, axis = None) | 同理,计算平均值 |
| average(a, axis =None, weights=None) | 依给定轴axis计算数组a相关元素的加权平均值 |
| std(a, axis = None) | 同理,计算标准差 |
| var(a, axis = None) | 计算方差 |
| min(a) max(a) | 计算数组a的最小值和最大值 |
| argmin(a) argmax(a) | 计算数组a的最小、最大值的下标(注:是一维的下标) |
| unravel_index(index, shape) | 根据shape将一维下标index转成多维下标 |
| ptp(a) | 计算数组a最大值和最小值的差 |
| median(a) | 计算数组a中元素的中位数(中值) |
二、pandas基本介绍
1、什么是pandas
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。我们在使用的过程中发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、pandas的数据结构
pandas 中主要有两种数据结构:Series 和 DataFrame。
①Series:一种一维的数组型对象,它包含了一个值序列(与 NumPy 中的类型相似),并且包含了数据标签,称为索引(index)。最简单的序列可以仅仅由一个数组组成。注意:Series 中的索引值是可以重复的。
②DataFrame:表示矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,它可以被视为一个共享相同索引的 Series 的字典。在 DataFrame 中,数据被存储为一个以上的二维块,而不是列表、字典或其他 一维数组的集合。
③Time- Series:以时间为索引的Series
④Panel:三维的数组,可以理解为DataFrame的容器
⑤Panel4D:是像Panel一样的4维数据容器
⑥PanelND:拥有factory集合,可以创建像Panel4D一样N维命名容器的模块
3、pandas常用操作
(1)数据读取与写入

(2)Dataframe的增删改查
| 方法 | 作用 |
| df.values | 查看所有元素 |
| df.index | 查看索引 |
| df.columns | 查看所有列名 |
| df.dtype | 查看字段类型 |
| df.size | 元素总数 |
| df.ndim | 表的维度数 |
| df.shape | 返回表的行数与列数 |
| df.info | DataFrame的详细内容 |
| df.T | 表转置 |
(3)查看Dataframe
①基本查看方式
| 方式 | 作用 |
| df[‘col1’] | 单列数据 |
| df[‘col1’][2:7] | 单列多行 |
| df[[‘col1′,’col2’]][2:7] | 多列多行 |
| df[:][2:7] | 多行数据 |
| df.head() | 前几行 |
| df.tail() | 后几行 |
②loc,iloc的查看方式(大多数时候建议用loc)
# loc[行索引名称或条件,列索引名称]
# iloc[行索引位置,列索引位置]
| 类型 | 方法 |
| 单列切片 | df.loc[:,’col1′] |
| df.iloc[:,3] | |
| 多列切片 | df.loc[:,[‘col1′,’col2’]] |
| df.iloc[:,[1,3]] | |
| 花式切片 | df.loc[2:5,[‘col1′,’col2’]] |
| df.iloc[2:5,[1,3]] | |
| 条件切片 | df.loc[df[‘col1′]==’245’,[‘col1′,’col2’]] |
| df.iloc[(df[‘col1′]==’245’).values,[1,5]] |
③数据更改
| 方式 | 作用 |
| df.loc[df[‘col1′]==’258′,’col1’]=214 | 更改某个字段的数据,不可逆 |
| df[‘col2’] = 计算公式/常量 | 增加一列数据 |
| df.drop(labels=rang(1,11),axis=0,inplace=True) | 删除某几行数据,inplace为True时在源数据上删除,False时需要新增数据集 |
| df.drop(labels[‘col1′,’col2’],axis=1,inplace=True) | 删除某几列数据 |
④处理时间序列
| 方法 | 作用 |
| df[‘time’] = pd.to_datetime(df[‘time’]) | 转换字符串时间为标准时间 |
| year = df[‘time’].year() | 提取时间序列信息 |
| df[‘time’] = df[‘time’] + pd.Timedelta(days=1) | 时间加减法,使用Timedelta,支持weeks,days,hours,minutes,seconds,但不支持月和年 |
| df[‘time’] = df[‘time’] – pd.to_datetime(‘2016-1-1’) | |
| df[‘time’].max() – df[‘time’].min() | 时间跨度计算 |
三、numpy、pandas的使用演示
本次演示主要针对索引切片的演示,计算函数在上文中都有含有解释,我们在实际的数据预处理中就是从脏数据筛选出自己想要的数据,在生成清洗过后的数据文件,
1、数据介绍
import pandas as pd
import numpy as np
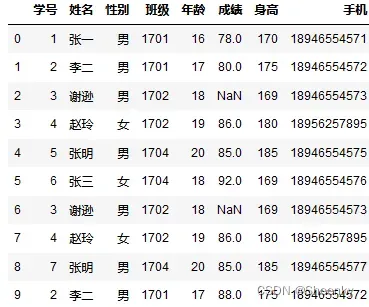
df = pd.read_csv("student.csv")数据文件名:student.csv
数据样式,通过pandas的pd.read_csv()方法数据读入(图中电话随意生成有,如有影响联系删除):
2、数据提取
(1)列的提取
单列提取
单列索引根据columns列名进行索引,索引所得是index+被索引列所有值。

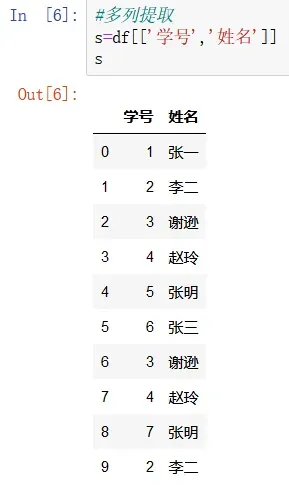
多列提取
值得注意的是多列索引时需要加入两个中括号,而不是[‘学号’,’姓名’],同时索引的列名不用按照顺序填写,可以根据自己的需求和顺序填写,索引所得结果是根据填写的索引列顺序一样。

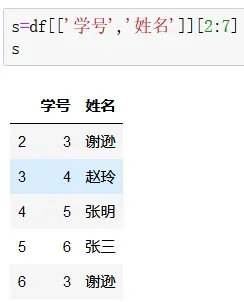
(2)列多行索引
前面未指定列名时将显示全部信息,数据行数根据后面的索引所定,后面索引方式遵循的是Python的索引规则,左包括而右不包括。
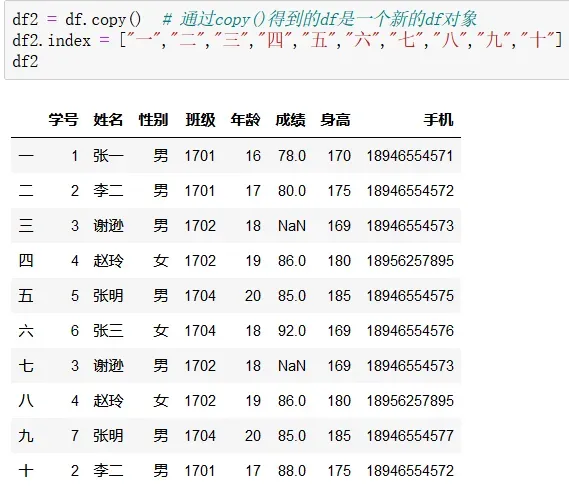
(3)更改index,使用loc,iloc索引
index的更改使永久性的更改,所以在做之前可以通过复制生成新的数据对象,以免“污染”原数据,同时对于里面的数据更改也是一样,是永久性的更改,所以当我们需要按照不同的要求增删改查的时候,进行文本复制之后再做更改使最佳的选择。
dataframe的切片(先行后列)
df.loc
df.loc[首行index值:末行index值, 首列列名:末列列名]
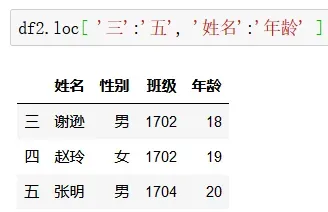
df.iloc
df.iloc[起始行位置:结束行位置, 起始列位置:结束列位置]

(4)特定值提取
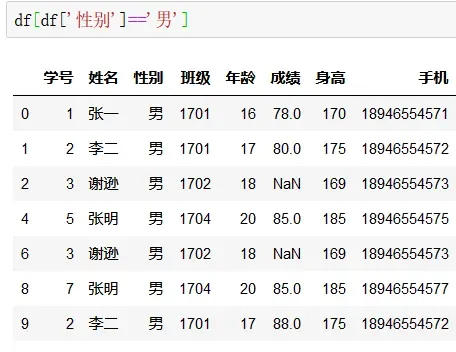
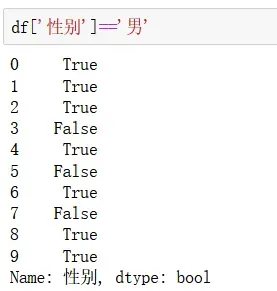
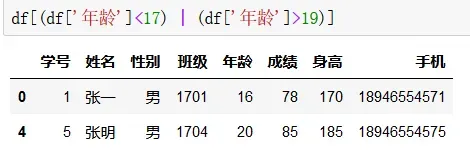
特定值提取通过语法如自变量名[自变量名[‘列名’]==‘筛选条件’],切记若写成自变量名[‘列名’]==‘筛选条件’形式就会生成如下图二的形式,相当于系统通过查找比对返回的是判断结果值。
文章出处登录后可见!