卷积神经网络
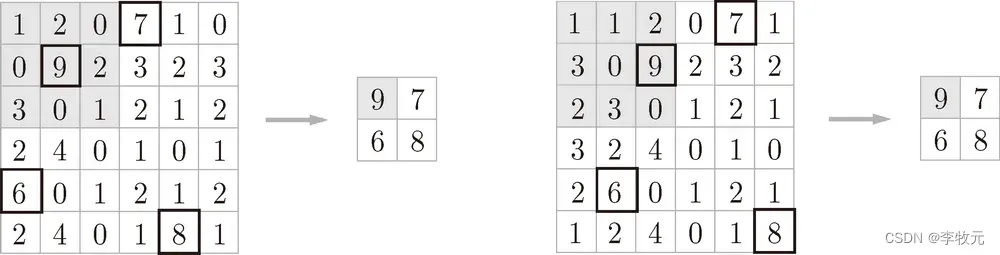
这一章我们将学习卷积神经网络的工作原理,相比较于前面学习过的神经网络,CNN多了卷积计算和池化过程,一图胜千言:
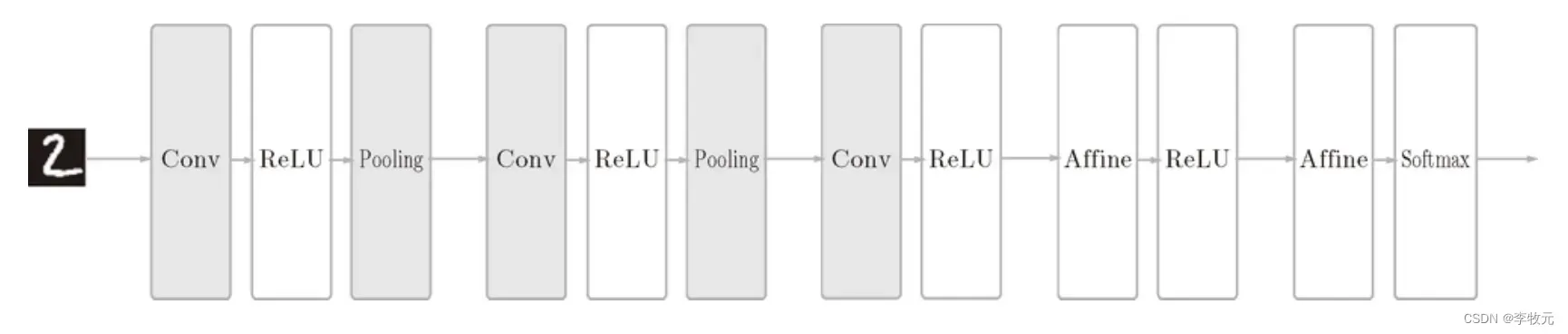
6.1 卷积层
卷积运算和前面介绍的仿射运算很类似,不过前面是将输入数据乘一个权重,这里我们是乘一个叫滤波器的东西,你可能会好奇,为什是同样的计算过程,改个名字就叫卷积神经网络了,不同之处在于,现在输入的数据不再是二维的了,而是是三维的,先在二维上学习卷积神经网络工作原理,这就是卷积运算的大概过程:
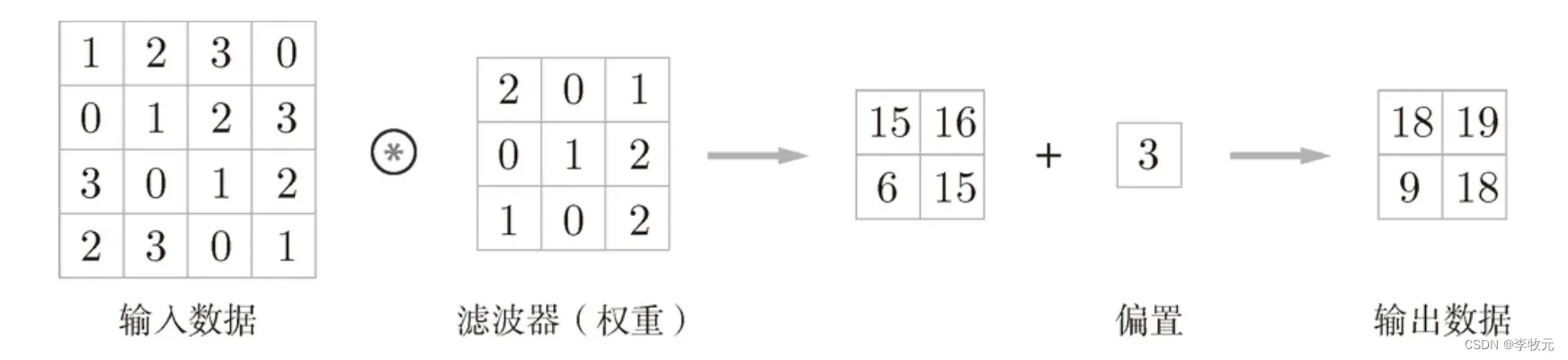
6.1.1 滤波器
滤波器实际上就是我们以前学过的权重矩阵,以下是应用它的计算过程,他的生成有填充和步幅两个概念(随后介绍):
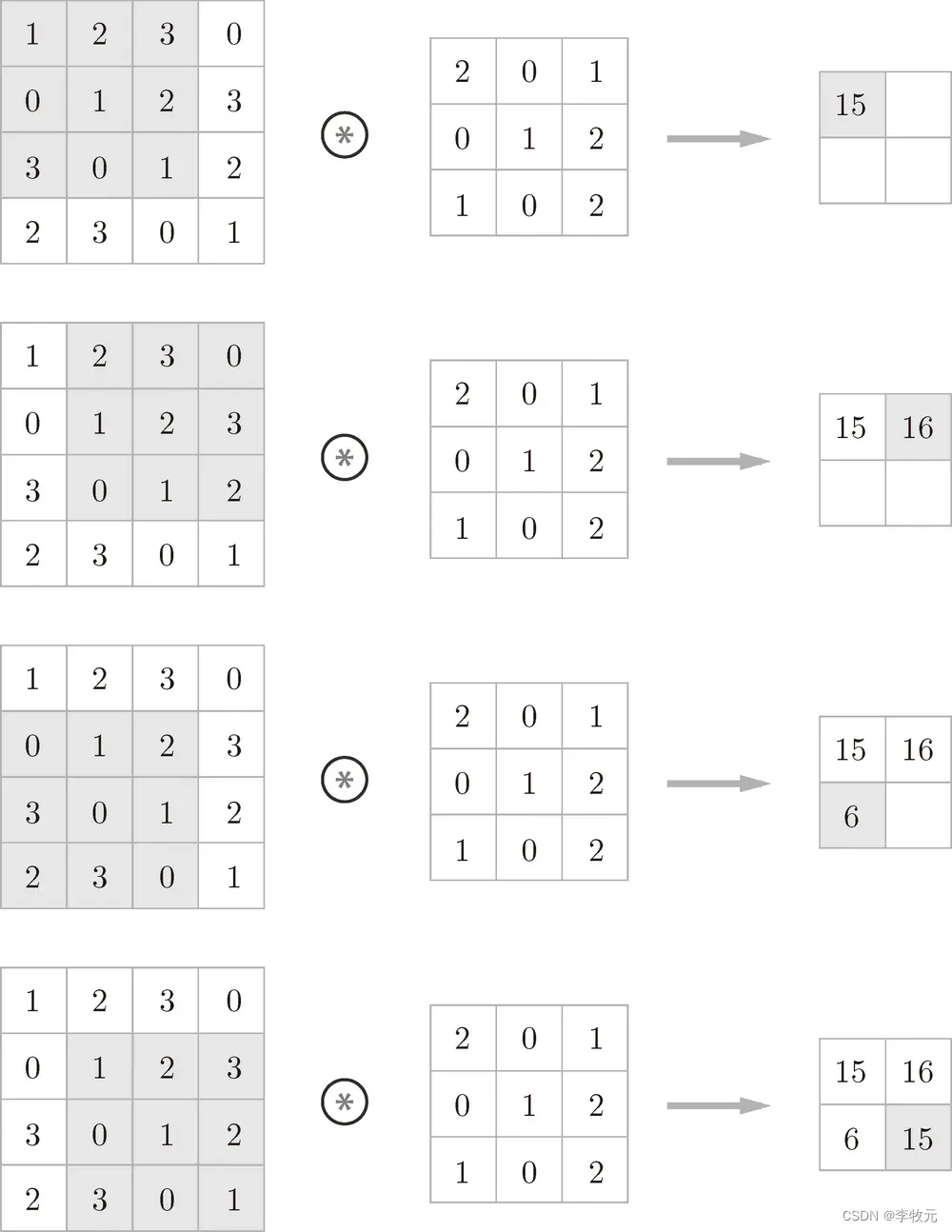
6.1.1.1 填充
填充是在原始数据周围填上一些固定数据,比如零,这样做的目的是扩大输出数据的维度:
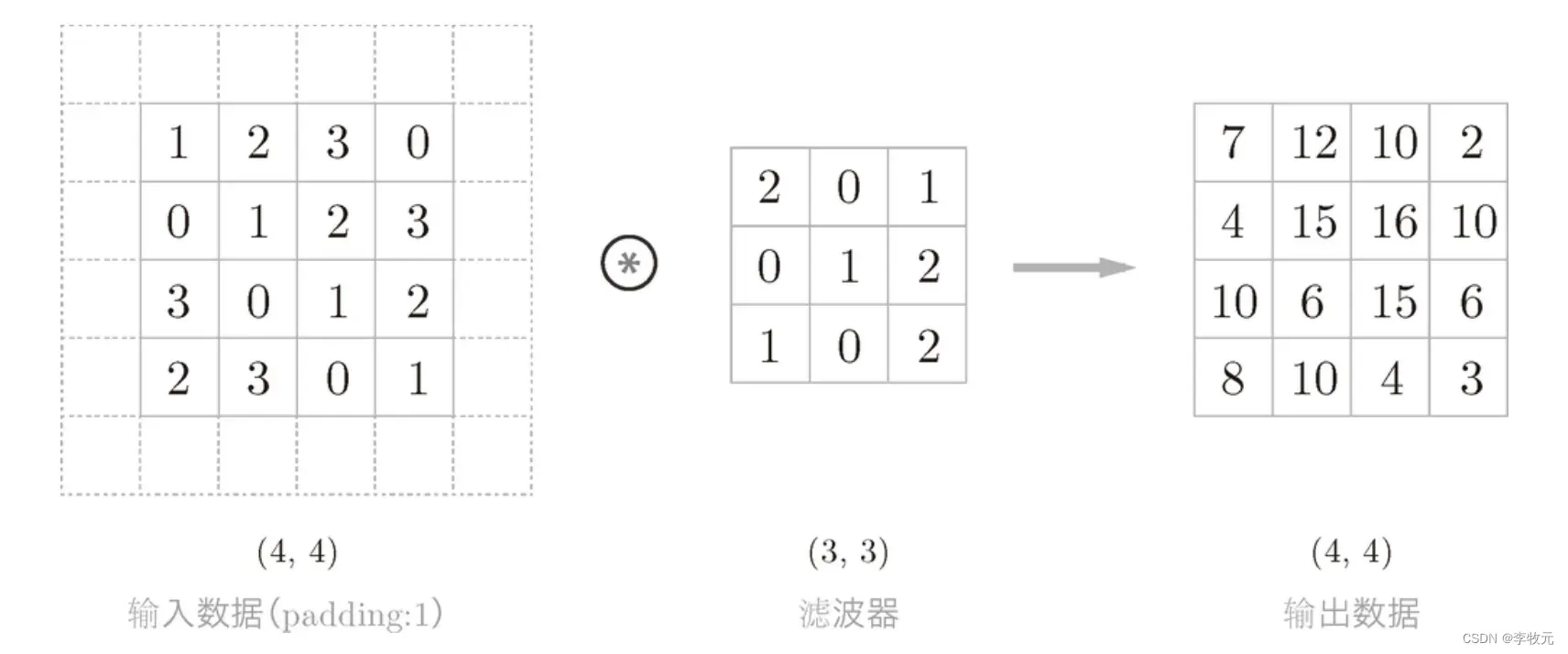
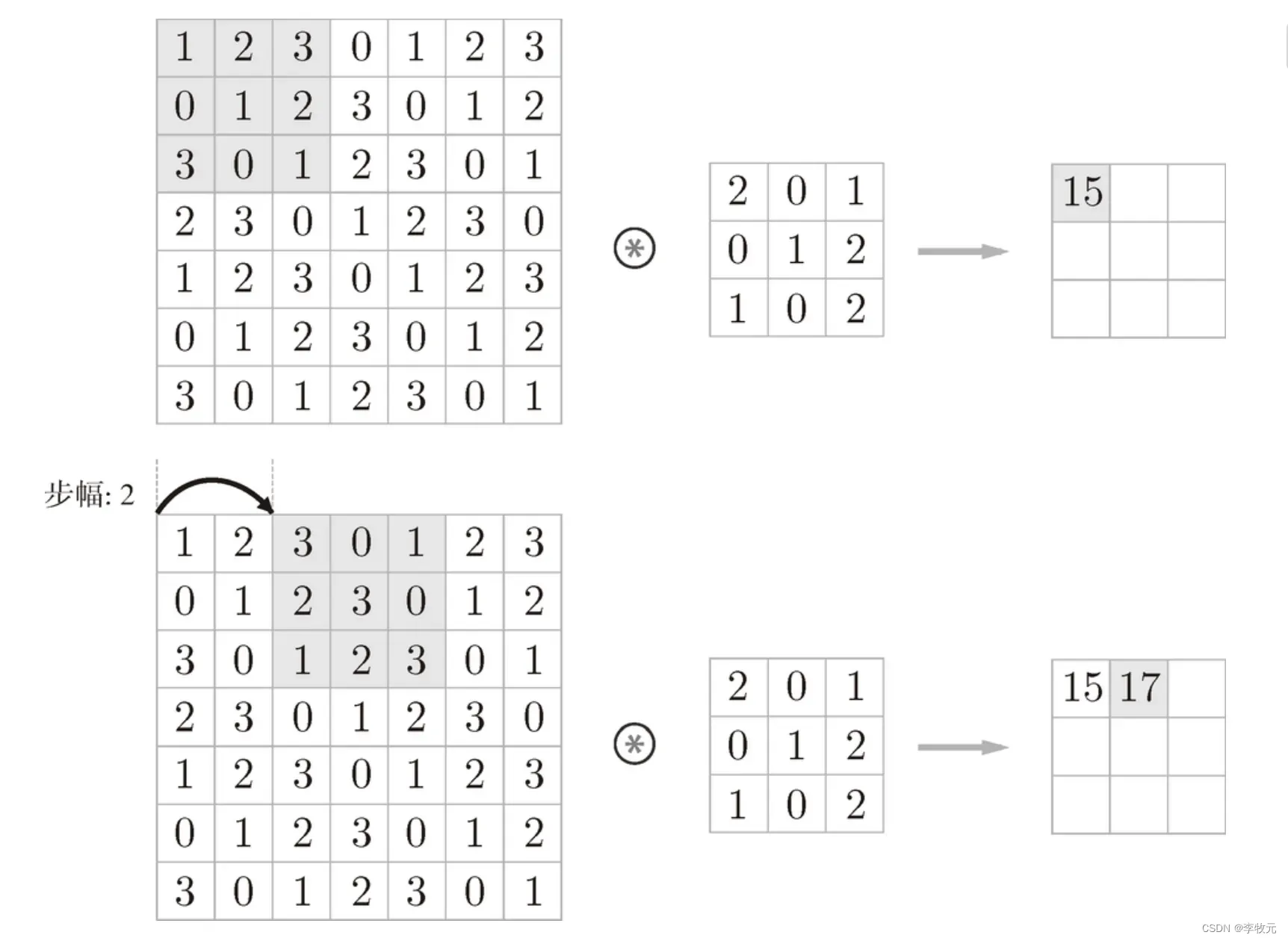
6.1.1.2 步幅
步幅也是调整输出纬度的手段,以前的步幅是1,下面我们来看步幅为2的例子:
6.1.2 输出纬度的计算
有了填充和步幅我们就可以知道输出的维度了,假设输入大小为 (H, W),滤波器大小为 (FH, FW),输出大小为 (OH, OW),填充为 P,步幅为 S。此时,输出大小可通过下式进行计算:
在设计滤波器的时候,填充和步幅要让上式计算结果为整数。
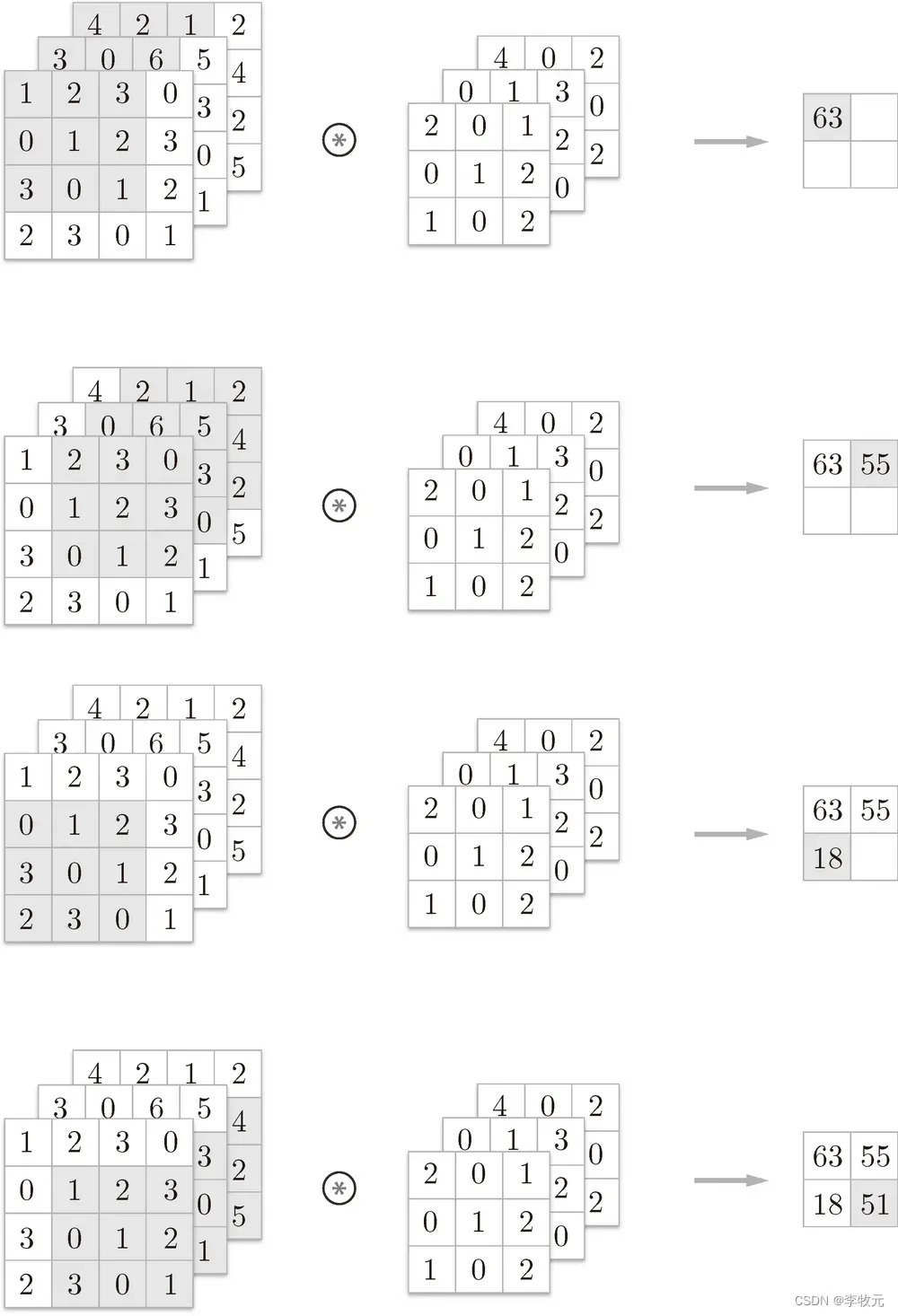
6.1.3 三维数据的卷积运算
有了前面的铺垫,三维卷积运算的过程就好理解了,因为三维除了有高度和宽度,还有一个通道方向(z轴方向),他会将每个通道方向上按照刚刚介绍的二维计算过程计算结果,最后将结果相加,得到一个特征图:
6.2 池化层
池化过程的核心是从输出的数据中去有代表性的数据,来缩小高、长方向上的空间的运算,比如下面是按步幅 2 进行 2 × 2 的 Max 池化时的处理顺序。
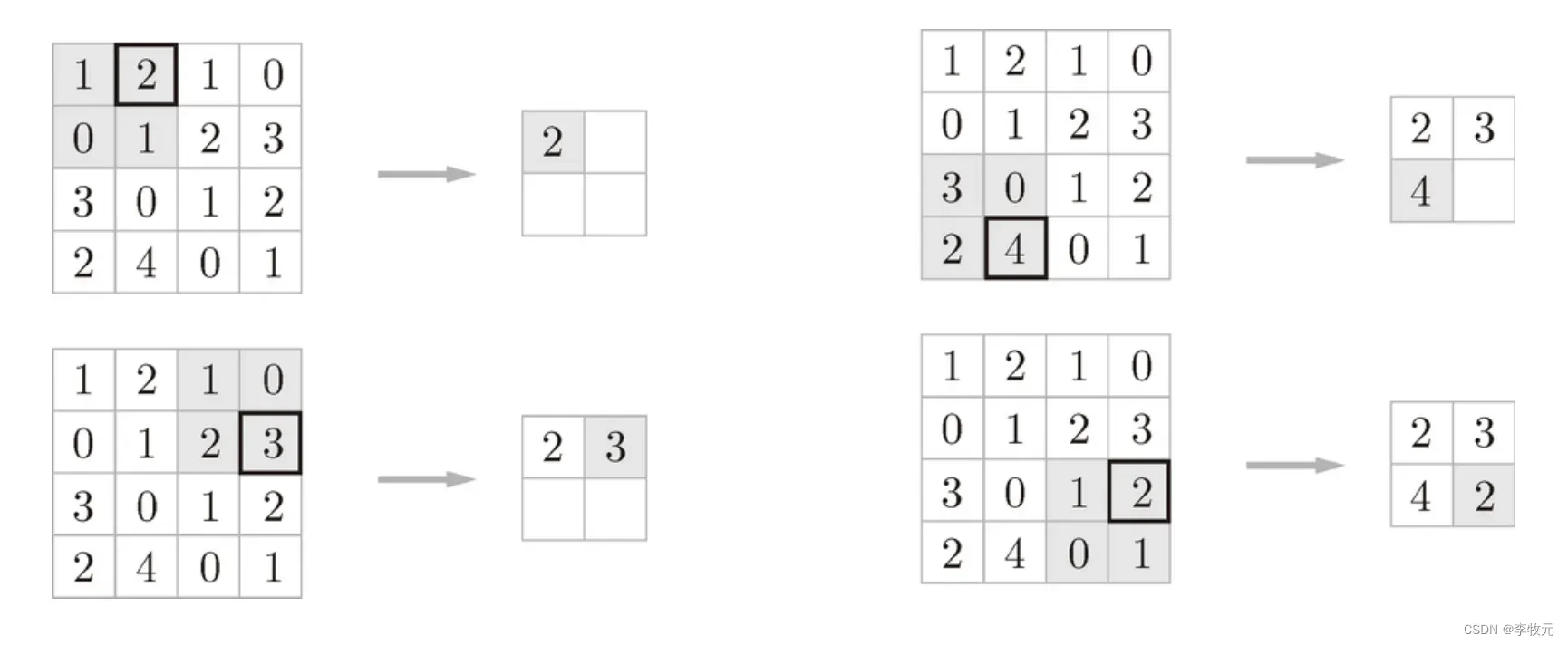
池化具有以下特征:
没有要学习的参数
池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
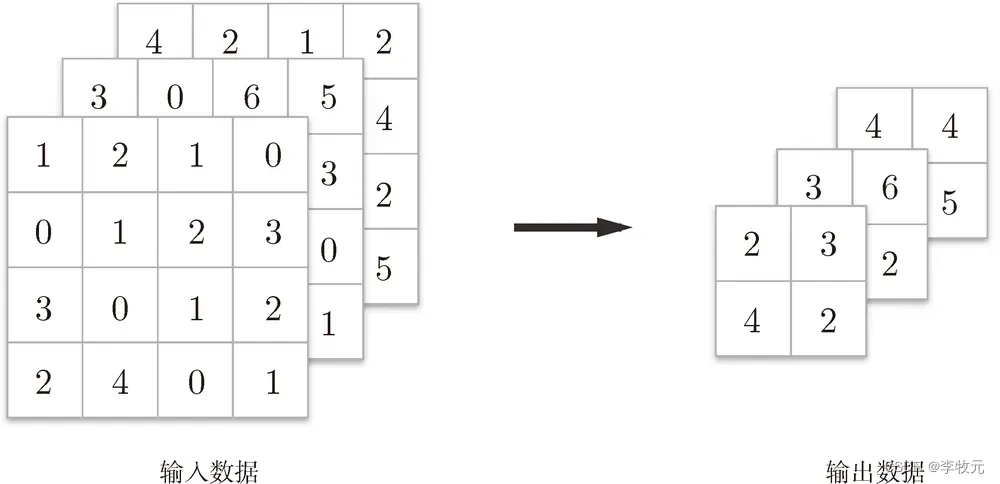
通道数不发生变化
经过池化运算,输入数据和输出数据的通道数不会发生变化。如图所示,计算是按通道独立进行的。
对微小的位置变化具有鲁棒性(健壮)
输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性。比如,3 × 3 的池化的情况下,如图 7-16 所示,池化会吸收输入数据的偏差(根据数据的不同,结果有可能不一致)。
6.3 卷积网络的实现
6.3.1 卷积层的实现
首先,我们来看一下卷积运算的工作流程:
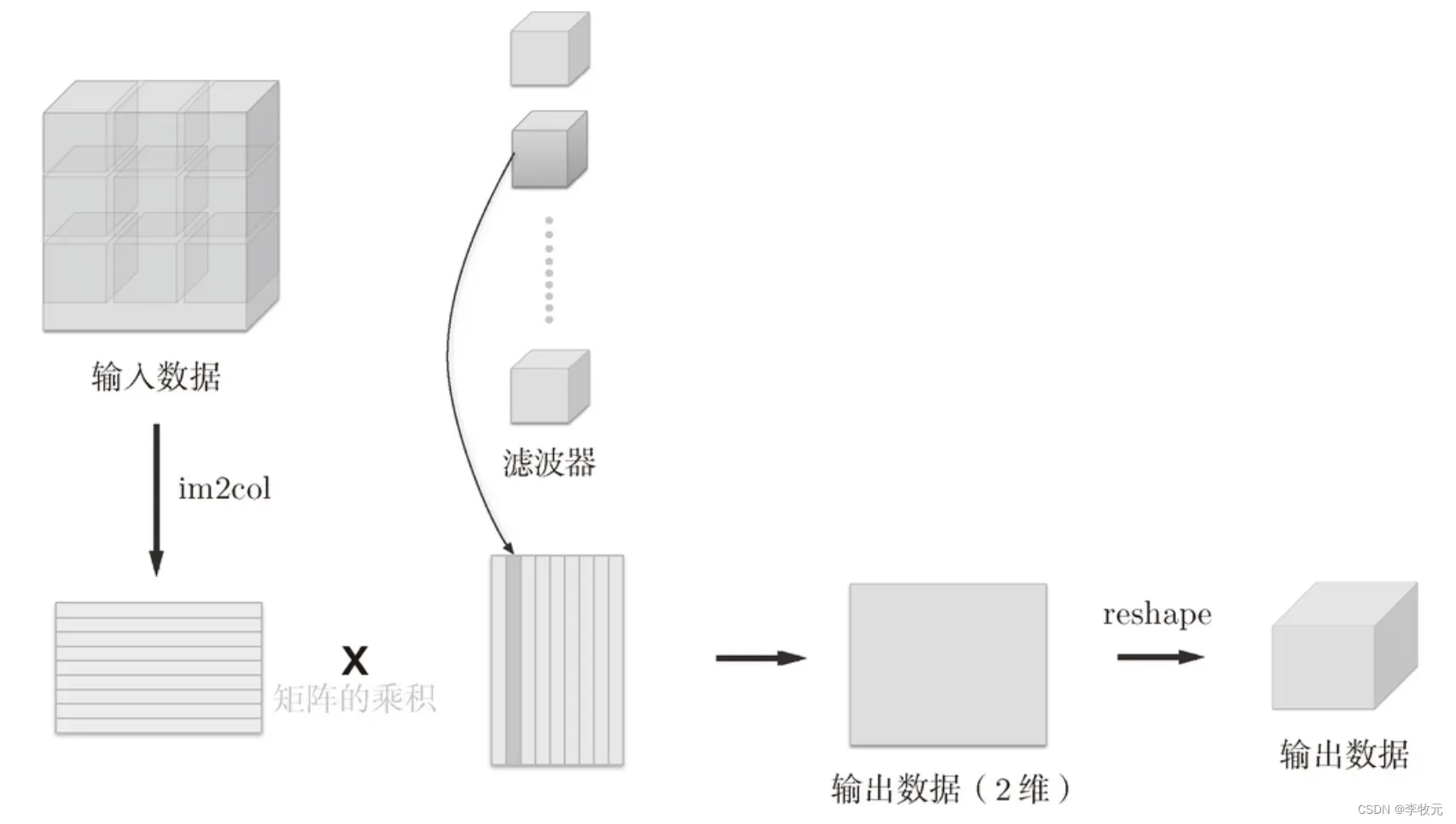 可以看到图中使用了im2col函数,这个函数的功能是将输入数据转化成二维数据,方便与滤波器转化成的二维矩阵相乘。
可以看到图中使用了im2col函数,这个函数的功能是将输入数据转化成二维数据,方便与滤波器转化成的二维矩阵相乘。
这个函数的接口如下:
im2col (input_data, filter_h, filter_w, stride=1, pad=0)
- input_data——由(数据量,通道,高,长)的 4 维数组
- 构成的输入数据
- filter_h——滤波器的高
- filter_w——滤波器的长
- stride——步幅
- pad——填充
下面来看展开结果:
x1 = np.random.rand(1, 3, 7, 7)#一个数据,通道数为3,高度为7,宽度为7
col1 = im2col(x1, 5, 5, stride=1, pad=0)
print(col1.shape) # (9, 75)
x2 = np.random.rand(10, 3, 7, 7) # 10个数据,通道数为3,高度为7,宽度为7
col2 = im2col(x2, 5, 5, stride=1, pad=0)
print(col2.shape) # (90, 75)
有了前面的铺垫以后,那么一个卷积层的实现为:
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
# 中间数据(backward时使用)
self.x = None
self.col = None
self.col_W = None
# 权重和偏置参数的梯度
self.dW = None
self.db = None
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = 1 + int((H + 2*self.pad - FH) / self.stride)
out_w = 1 + int((W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
6.3.2 池化层的实现
池化层的实现和卷积层相同,都使用 im2col 展开输入数据。不过,池化的情况下,在通道方向上是独立的,这一点和卷积层不同。具体地讲,如图下图所示,池化的应用区域按通道单独展开。
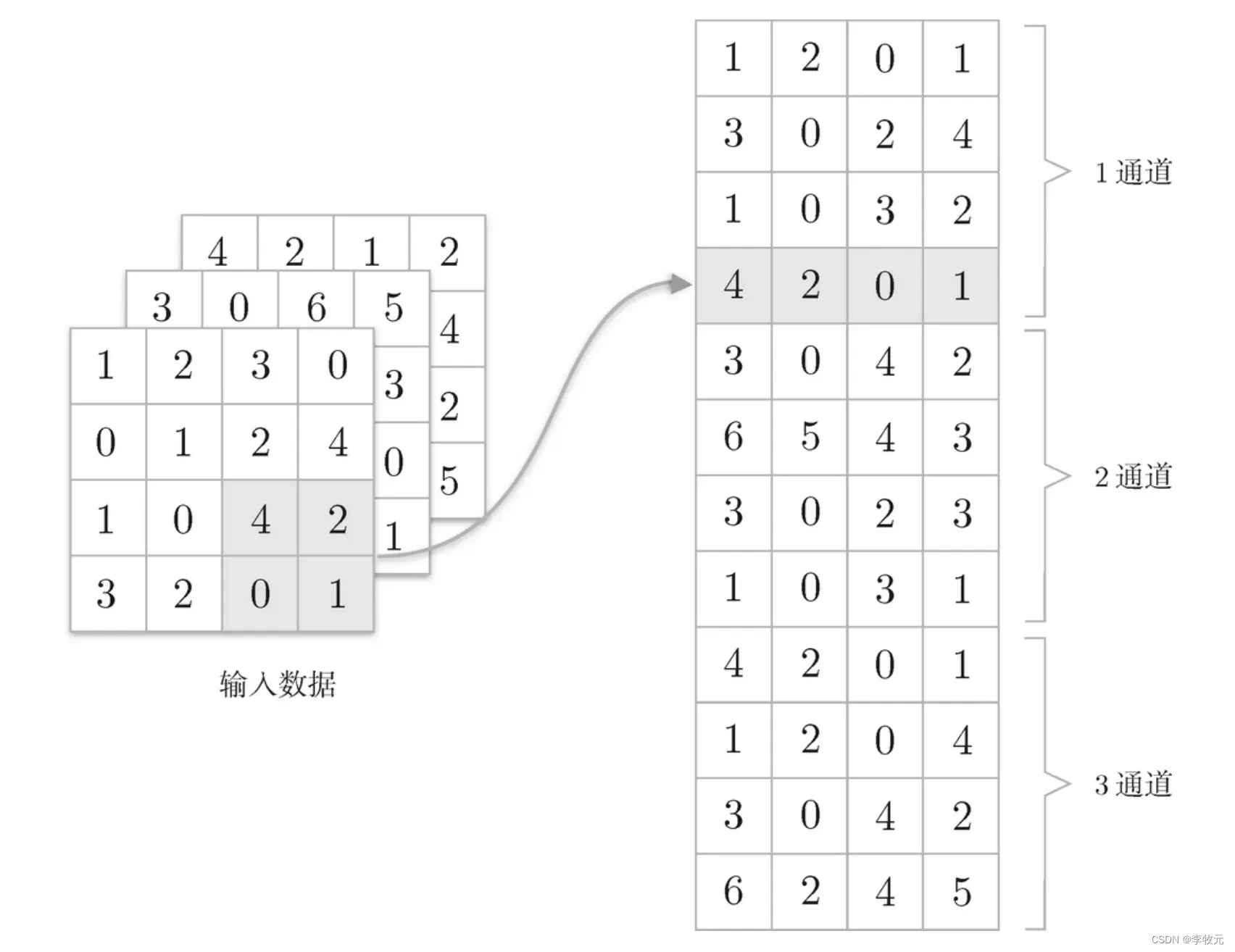
展开后使用Max池化原理:
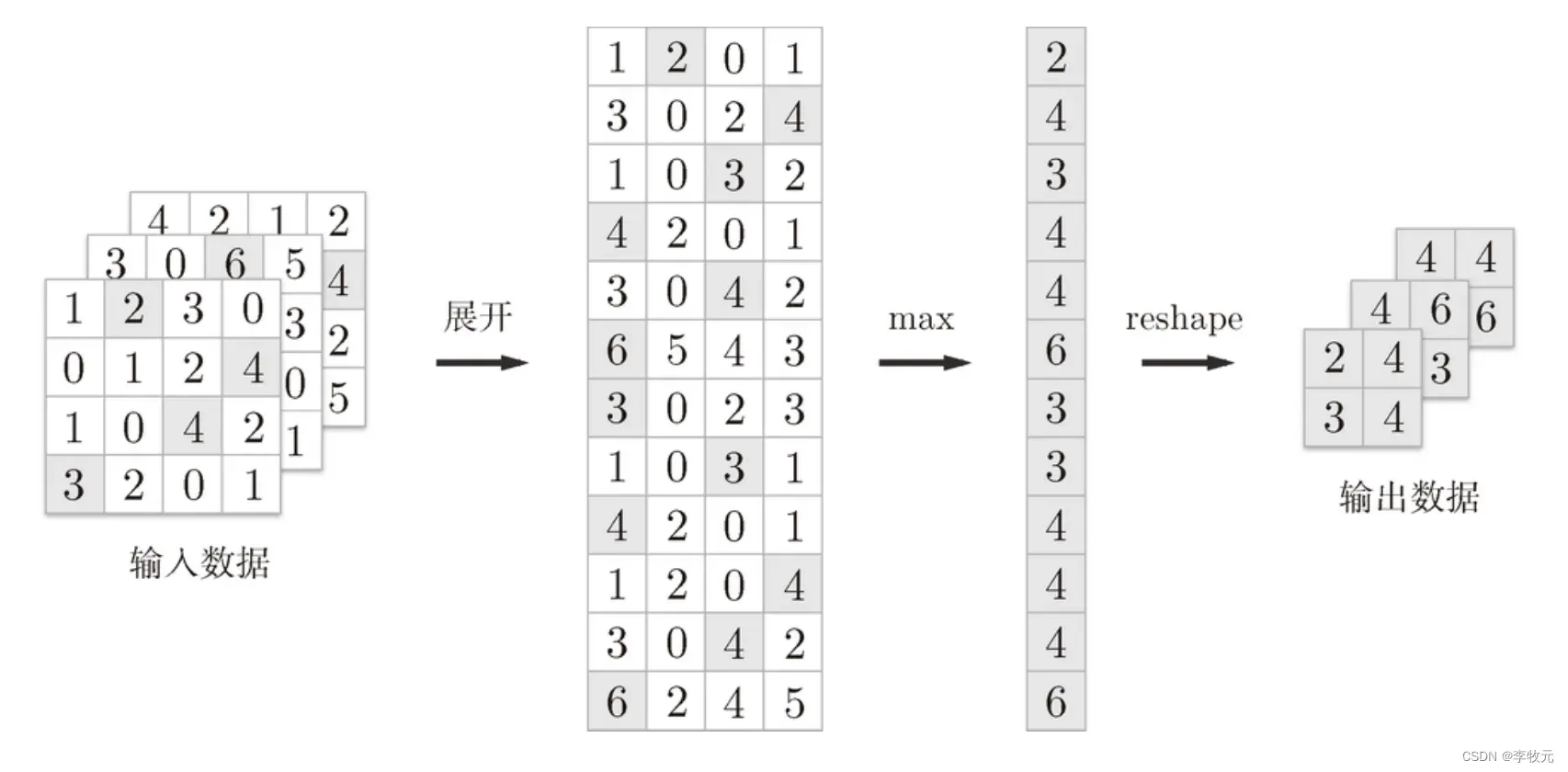
最后进行代码实现:
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
self.x = None
self.arg_max = None
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
arg_max = np.argmax(col, axis=1)
out = np.max(col, axis=1)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
dmax = np.zeros((dout.size, pool_size))
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx
6.3.3 CNN的实现
假设我们要实现这样的一个卷积神经网络:
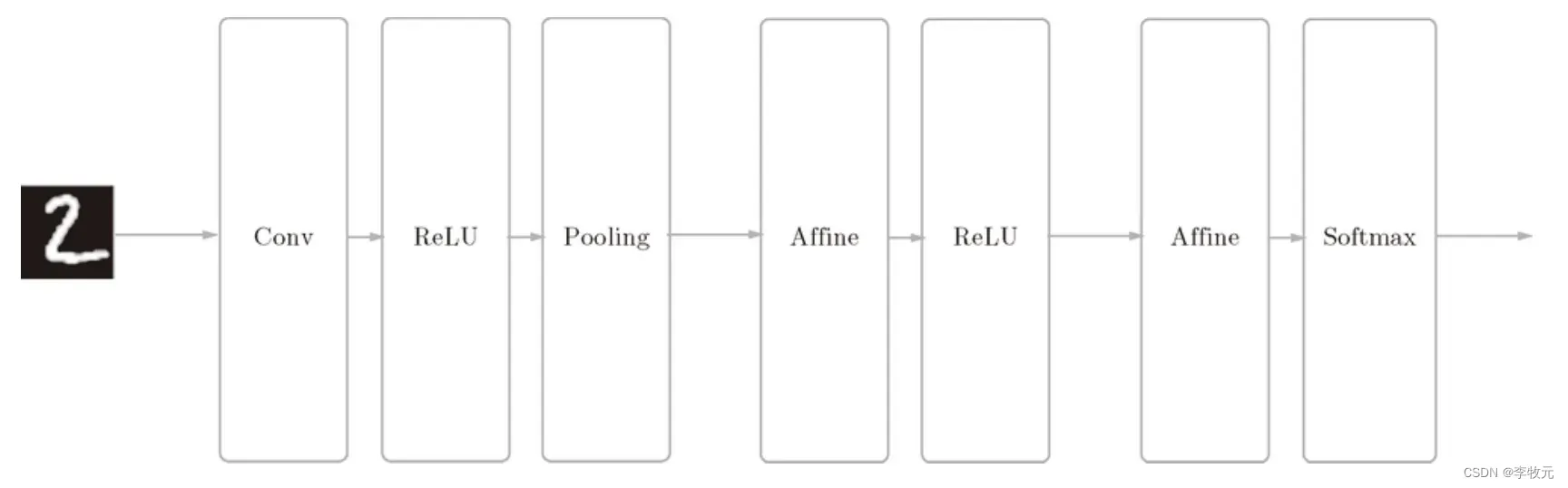
那么最后实现的代码为:
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
总结
本节我们主要学习了卷积神经网络的工作原理,其中相比较于神经网络,他多了卷积计算和池化两个过程需要理解。
文章出处登录后可见!