从图灵开始,让计算机像人一样思考成了人们的共同理想。然而现实是,人脑可以处理无数复杂的问题,不是因为在出生时别人自动在我们脑子里安装了千万个程序告诉我们怎么处理,而是人脑具有学习的能力,人脑可以从经验中学习。想让机器像人脑一样强大,就要让它像人一样学习。因此,机器学习作为一个独立分支从AI中发展出来。
一.监督学习和无监督学习
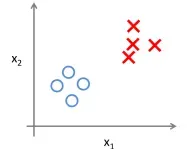
机器学习通常可分为两大类——监督学习与无监督学习。
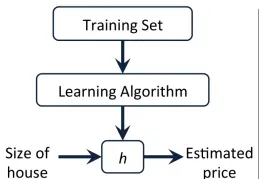
监督学习也就是已经给了正确答案(right answers given),用一个假设(hypothesis)去逼近输入到给定输出的映射。如下,根据房子的大小预测房价,用假设去拟合训练集中的样本点,让假设函数经过尽可能多的样本点,这样就可以根据用户提供的房屋大小的数据预测它的价格。可以看出多项式比直线经过了更多的样本点,因此多项式假设更能体现房屋大小与价格的关系。
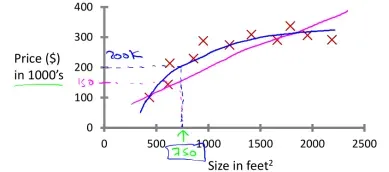
上例中的输出(价格)为连续值,因此为为回归问题(regression)。
我们也可以根据乳腺肿瘤大小预测它是良性还是恶性。如下例所示,画出肿瘤尺寸与恶性程度的关系,用1表示恶性,0表示良性,可以看出肿瘤尺寸越大,越可能是恶性。此时输出要么为良性(0),要么为恶性(1),为两个离散值,因此这是一个分类问题(classification)。

无监督学习就是没有提供正确答案,需要计算机根据输入数据的聚散程度去主动分类数据。典型的就是聚类算法,例如网站根据关键词对新闻自动分类。
二.线性回归
如上所述,回归问题可以简单理解为输出为连续值。具体地,我们如何用机器学习算法模拟回归问题呢?就拿最简单的线性回归为例,线性回归就是可以用线性函数拟合输入输出之间的映射关系,也就是假设为线性函数。
第一步是对实际问题建模。如下图所示:根据训练集中数据的特征选择合适的算法,让输入新数据时,输出为合理的预测值。对于线性回归问题,假设可表示为: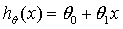 ,其中
,其中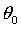 为偏置值。此时只需要调整两个参数让假设函数通过最多的样本点即可。
为偏置值。此时只需要调整两个参数让假设函数通过最多的样本点即可。
第二步,要怎么选择参数可以让假设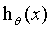 最接近标签值
最接近标签值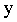 呢?为此学者们定义了代价函数(cost function)
呢?为此学者们定义了代价函数(cost function)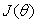 来定量的表示假设
来定量的表示假设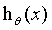 的拟合程度:
的拟合程度:
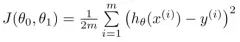
代价函数表示假设与标签值的均方误差,m表示样本数量,除以2是为了之后求导之后没有乘2项。代价函数可以定量地描述我们选择的假设与真实值的偏离程度,方便我们对假设进行优化。
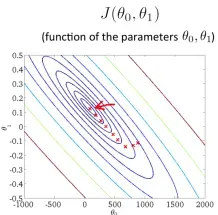
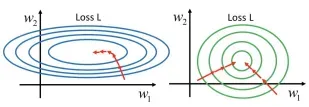
在两个特征的算法中,通常用等高线图将代价函数可视化,如下图所示:一个椭圆线代表一个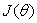 值,也就是说,处在同一条线上的参数对
值,也就是说,处在同一条线上的参数对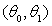 具有相同的代价。越往椭圆中心,代价值越小,椭圆中心就是代价为0的点。
具有相同的代价。越往椭圆中心,代价值越小,椭圆中心就是代价为0的点。
第三步,定义了代价函数以后,接下来就要对假设函数进行优化。优化的目标非常明确: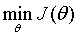
也就是选择参数θ让代价函数最小,也就是让假设与标签值的累计偏离值最小,这样的假设函数是最接近真实情况的。
(1)常用于优化代价函数之一是梯度下降算法:
Repeat until convergence:
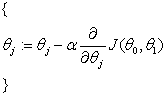
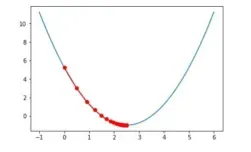
直观的来说,就是通过求导得到最大下降速度的方向(梯度),一步步往局部极小值处移动。可以理解为下山,找最陡的路径下山就最快。α为学习率(learning rate),决定下降速率。如下图分别为有一个参数和有两个参数的梯度下降情况。
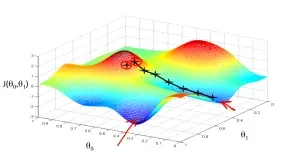
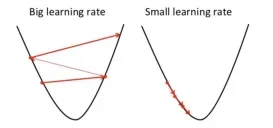
学习率α决定了下降每一步的步长,如果α太小,下降速度很慢,很长时间才能达到最低点;如果α太大,可能直接越过最低点,导致代价函数无法收敛甚至发散,如下图所示。
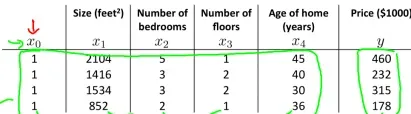
梯度下降算法中非常重要的操作就是特征缩放(feature scaling)。例如预测房价,给定特征的数据量级差异很大,如图:
那么画出来的等高线图就是下图左边所示,是一个很扁的椭圆形,这样梯度方向就很曲折,需要更多次迭代才能到达中心点。若进行特征缩放:
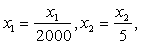
这样两个特征值都在0到1之间,等高线图如下右边所示,这样下山路径就顺畅多了。
怎么判断梯度下降算法是否正确工作呢?可以通过图表直观地表示。只要随着迭代次数(no. of iterations)增加,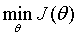 越来越小,如下图所示,那么说明梯度下降方向是正确的。
越来越小,如下图所示,那么说明梯度下降方向是正确的。
我们常常使用自动收敛测试来判断梯度下降算法是否成功完成——当 小于一个阈值,例如
小于一个阈值,例如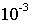 ,这是表示误差已经足够小,可以终止迭代了。
,这是表示误差已经足够小,可以终止迭代了。
(2)梯度下降算法是利用计算机的计算能力,一个一个值试出让代价函数最小的θ值。另外一个优化代价函数的方法是直接计算θ值,称为正规方程(normal equation)。计算方法为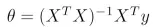
这里的X为特征值矩阵,y为预测矩阵,例如,当预测房价,特征值与预测值如下:
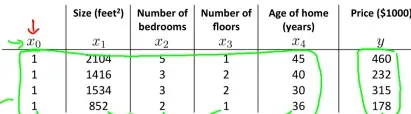
那么 ,
, 。X的每个行向量代表一个样本点,每个列向量代表一个特征的所有输入值。
。X的每个行向量代表一个样本点,每个列向量代表一个特征的所有输入值。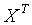 代表X的转置,-1上标代表矩阵的逆。
代表X的转置,-1上标代表矩阵的逆。
正规方程的优势是它不用选择学习率α,不需要多次迭代,劣势是需要对矩阵求逆。正规方程适用于大规模计算,当迭代次数大于10000次时,梯度下降算法就太过复杂了,此时选用正规方程法更合适。
三. 线性回归
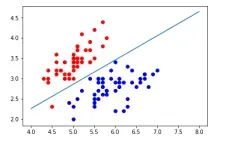
分类问题就是预测值为离散值的情况。拿乳腺肿瘤的例子来说,此时输出要么为良性(0),要么为恶性(1)。因为输出为离散值,如果我们选择线性假设拟合它就比较牵强了,因此要选择其他合适的假设函数。
首先仍然是建模,一般分类问题的假设函数为sigmoid函数,它可以将所有值映射到0到1之间,再采用合适的阈值进行离散化就可以得到离散输出,是比较适合分类问题的假设。
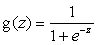
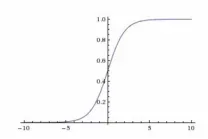
与回归算法相似,我们也可以用画图的方式直观地表示分类算法的假设,也就是决策边界(decision boundary)。选用sigmoid函数作为假设可将输入映射到0到1之间,然后通过选合适的阈值将输出离散化:
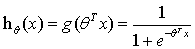
选取阈值0.5,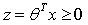 时,
时,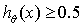 ,输出为1 ;
,输出为1 ;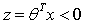 时,
时,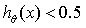 ,输出为0。
,输出为0。
如下图所示:第一张图中两种类别为线性边界,选择假设形式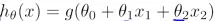 并且取参数
并且取参数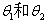 为1,
为1,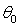 为-3,则对于y=1的区域为:
为-3,则对于y=1的区域为: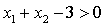 ,因此决策边界为
,因此决策边界为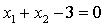 。同理可得第二张图的决策边界为:
。同理可得第二张图的决策边界为: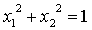 。
。
第二步是确定代价函数,如果我们选择逻辑回归的代价函数作为分类的代价函数,那么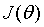 将不是凸函数:
将不是凸函数:
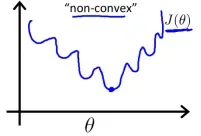
它有许多局部最优点,这样算法容易陷入局部最优点而找不到全局最优点。为了让分类的 仍为凸函数,我们选用代价函数如下:
仍为凸函数,我们选用代价函数如下:
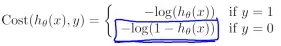
选择这个假设的理由如下:当y=1和y=0时,代价函数随假设值变化的图像分别如下:
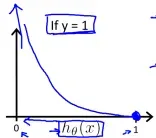
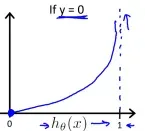
当y=1时,假设值越接近1则代价函数越小,当假设值为1时代价为0,反之当假设值为0时代价趋于无穷;当y=0时,假设值越接近0则代价函数越小,当假设值为0时代价为0,反之当假设值为1时代价趋于无穷。这样符合分类问题的逻辑。
合并为一个公式:
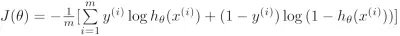
第三步是优化算法,为了得到最佳假设函数,需要优化代价函数。为此我们仍然可以采用梯度下降算法:
Repeat until convergence:
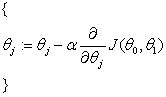
算法是相似的,只是其中的代价函数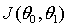 不同。
不同。
除了梯度下降,也有其他优化算法(advanced optimization)——共轭梯度下降,BFGS,L-BFCS等。它们不需要选择学习率α,只需要给定与其偏导数,算法就会返回最优θ值。具体算法就不给了,大家有兴趣可以去查阅相关资料。
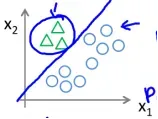
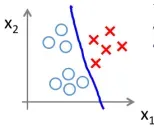
有时我们需要根据特征将输入分为多个类别。例如下图,根据两个特征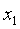 和
和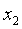 ,将数据分为三个种类。
,将数据分为三个种类。
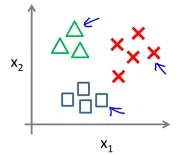
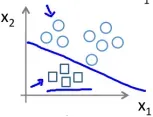
我们可视其为二分类的叠加,如下图所示,分别将每个分类当做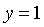 的情况,训练出三个假设函数
的情况,训练出三个假设函数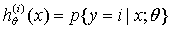 ,对于新的输入x,比较三个假设的值,选择
,对于新的输入x,比较三个假设的值,选择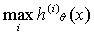 的分类i。
的分类i。
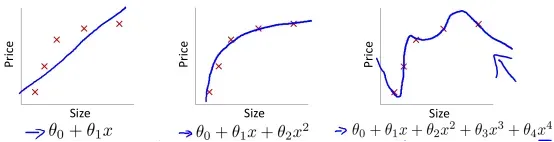
四.过拟合
我们都知道寻找的模型需要拟合数据集中的数据点,但如果拟合程度过于高,就会出现过拟合的问题,如下图第三个假设。这个假设提取了多个特征,完美地拟合了训练集的样本,然而它却很难推广到其他数据集中,毕竟它的适用范围太“专一”了,反而第二个假设在其他训练集中表现更好。
过拟合是由于特征过多导致假设函数过于复杂,因此首先我们可以去除无关或者影响较小的特征。其中,我们可以采用正则化(regularization)的方法减少特征的个数。
如下式,正则化就是在无关紧要的特征值前乘一个很大的值,这样就减小了它对整体代价函数的影响,变相地减少了特征值。
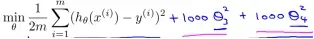
那么怎么知道哪个特征值无关紧要呢?这就得靠试了。在代价函数中加入如下式所示的正则化项,通过改变j的值,遍历所有特征就可以找出影响较小的特征了。
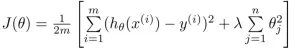
当然λ的取值需要合理,否则当将错误的特征正则化之后,有用的特征几乎置零,这样就得到了一条水平线。

版权声明:本文为博主BetaDu原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_53019232/article/details/122558172