

1.什么是MTCNN网络?
MTCNN(多任务卷积神经网络)将人脸区域检测与人脸关键点检测放在了一起,总体可分为P-Net、R-Net、和O-Net三层网络结构。
MTCNN是由中国科学院深圳研究院在2016年提出的专门用于人脸检测的多任务神经网络模型。该模型主要由3个级联网络组成,分别为可以快速生成候选框的P-Net网络、进行候选框过滤的R-Net网络和生成最终边界框并且标出人脸特征点的O-Net网络。该模型主要运用了图像金字塔、非极大抑制(NMS)和边框回归技术(Bounding-Box Regression)。
MTCNN实现人脸检测与对齐在一个网络里实现了人脸检测与五点标定的模型,主要是通过CNN模型级联实现了多任务学习网络。整个模型分为三个阶段,第一阶段通过一个浅层的CNN网络快速产生一系列的候选窗口(P-Net网络);第二阶段通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口(R-Net网络);第三阶段通过一个能力更加强的网络找到人脸上面的五个标记点(O-Net网络)。
2.内部实现原理?
首先输入原始图片集,图片在进入3个级联网络前会通过图像金字塔技术对图片进行尺寸重新划分,将原图缩放为不同的尺度,从而构成图像金字塔;然后将这些不同尺寸的图片送入3个级联网络进行训练,这是为了让网络可以检测到不同大小的人脸而进行的多尺度检测。
在完成图像金字塔后,生成的图像会进入MTCNN的第一个网络层,即P-Net网络层。P-Net全称为Proposal Network,该网络也是一个全连接网络,对于上一步输入的图像,通过全卷积网络(FCN)初步提取图像特征并且给出初步的标定边框,这时会出现许多标定边框,因为P-Net会通过一个人脸分类器将可能为人脸的部分都打上边框。在该网络的最后会通过Bounding-Box Regression与NMS对刚才生成的边框进行初步筛查,丢弃不符合标准的标定边框。P-Net网络结构如图所示。
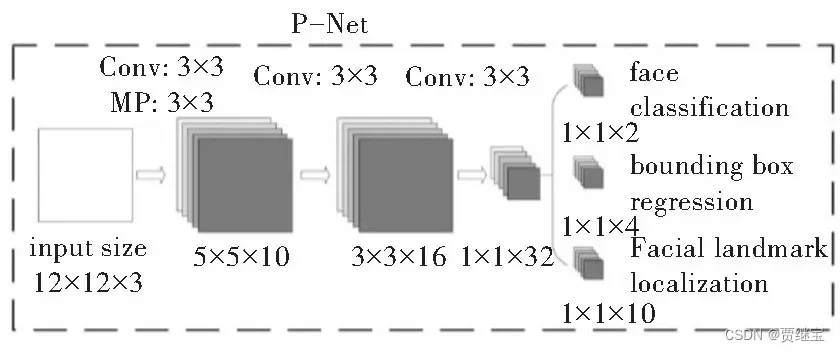

从P-Net网络输出的标定边框的人脸区域会进入下一个网络,即R-Net网络进行处理。
R-Net全称Refine Network,该层网络从结构上讲就是一个基本的卷积神经网络,比P-Net多了一层全连接层,这使得对脸部特征点和边框的筛选将更为严格。
对网络中输入的值进行更加细化的选择,并且舍去大部分错误,该层也会利用人脸关键点定位器对人脸关键点进行定位以及边框回归,最后利用Bounding-Box Regression与NMS对结果作进一步优化,将可信度较高的人脸区域输出给下一层网络,即O-Net网络。R-Net网络的网络结构如图所示。
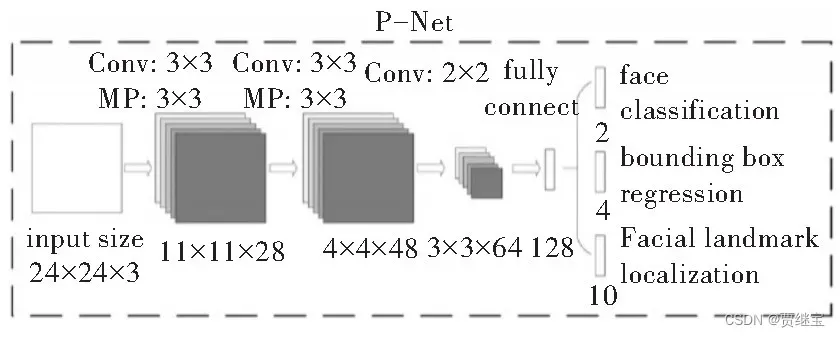

O-Net网络的全称为Output Network,该层网络基本结构与R-Net网络结构相似,多了一层卷积层,网络结构更加复杂,拥有更好的性能,模型优化也更好。在该层对输入图像进行人脸判别、人脸边框回归以及特征点定位,最后在图片中输出人脸区域的5个特征点。O-Net网络结构如图所示。


3.MTCNN网络实施流程?
将原始图片输入MTCNN网络,让MTCNN网络可以准确地识别出人脸和关键点。然后通过检测到的5个关键点,再根据“三庭五眼”理论将人脸的眼睛、嘴巴和耳朵分为了3个区域,定义了左、右眼中心点连线与水平方向的夹角为q,眼部区域宽度为W,高度为H=w/2。从鼻尖点位C向左右嘴角连线作垂线,记垂距为D。嘴部区域上、下沿分别取该垂线及其延长线上D/2和3D/2处。这样在检测时可将这3个部分分开检测,不同的区域、不同的动作会产生不同的结果。
文章出处登录后可见!