提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
现如今,互联网上有着大量多模态的信息需要进行情感抽取,为了提高抽取准确率,本文提出了一种基于注意力机制的多模态语境融合策略,该方法首先是在融合之前提去目标三个模态下的上下文信息,然后再讲三个模态下的信息两两融合,最后再把两两融合后的三组信息融合。对于目标重要上下文信息提取采用的是BiLSTM和Attention结合。最终在公开数据集上实验,取得了最佳效果。
一、问题定义
定义目标数据utterence为U={u1,u2,…,uN},其中N表示U中数据量。ui={f1,f2,…,fn},其中n表示一个u中可分割的数据量,如一个句子中的字数,一个视频中的帧图数。
二、Model
1.特征提取
1.Audio feature extraction
音频特征提取,本文采用的是Open SMILE模型,每隔100ms,提取频率在30Hz的信息。数学表示为:
fa=<fa1,fa2,…,faN>
其中fai是ui的音频特征表示。
2.Textual feature extraction
文本特征提取,首先根据音频得到对应的文本,然后采用Word2Vec对文本进行词嵌入,语义和语句信息则通过CNN学习,有三个卷积核,大小为(2,3,4)。数学表示为:
ft=<ft1,ft2,…,ftN>
其中fti是ui的文本特征表示。
3.Visual feature extraction
图像特征提取,本文采用CNN提取图像特征,其中图片是按帧提取视频图像,数学表示为:
fv=<fv1,fv2,…,fvN>
其中fvi是ui的图像特征表示。
2.过往特征融合方法
在过去主要有两种方法融合不同模态的特征表示,方法1是直接将不同模态的特征拼接传入全连接,方法2是直接学习多个单模态特征得到多个对应的分类结果,然后按照某种规则得到最终的分类结果,两种方法如下图所示:
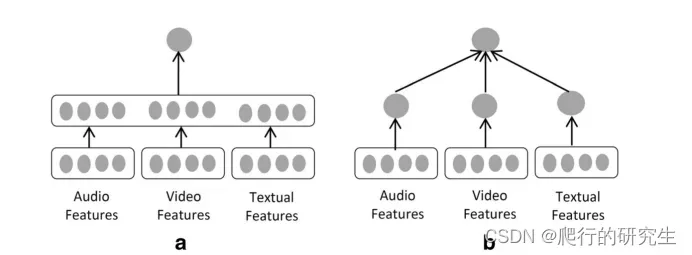 但是以上两种方法都无法避免大量冗余信息,所以本文提出了一种新的特征融合方式。
但是以上两种方法都无法避免大量冗余信息,所以本文提出了一种新的特征融合方式。
3.本文方法
1.单模态特征上下文信息
首先是根据目标最大长度填充,使得所有目标长度一致,然后把三个模态的特征表示传入BiLSTM得到具有上下文感知的三种模态表示,公式如下:
Fa=BiLSTM(fa)
Ft=BiLSTM(ft)
Fv=BiLSTM(fv)
2.双模态特征上下文信息
对于模态融合,本文首先是分别将3个模态下的特征表示直接拼接,公式如下:
Fxy=(Fx,Fy)
按照上述方式,一共可以到得到三种融合2个模态的特征表示Fat,Fav,Ftv。
然后将三种特征表示传入BiLstm-Attention,学习2个模态下的语义信息。
fxy=BiLstm-Attention(Fxy)
3.三模态特征上下文信息
方法类似双模态,首先拼接fxyz=(fxy,fxz,fyz),然后传入BiLstm-Attention学习三模态下的语义信息。
4.模型图
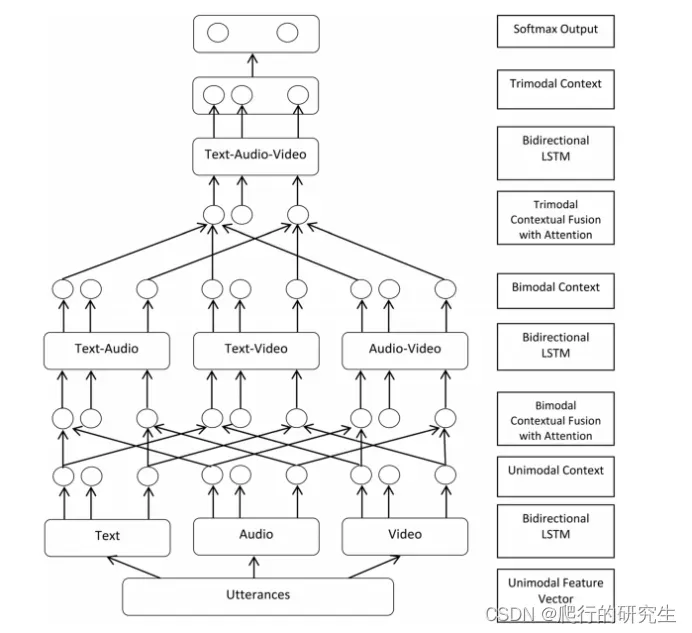
三、实验结果
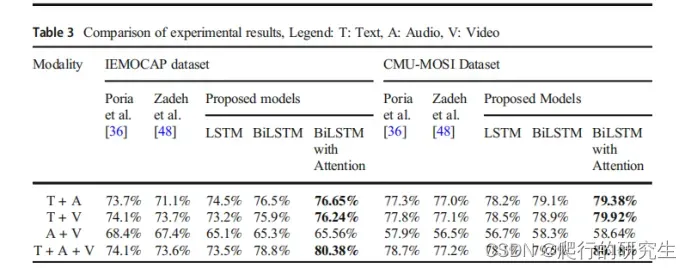 可以发现,在融合文本信息的时候效果总体要优于不融合文本信息,其次再叠加模态信息时,总体效果也随着增加。
可以发现,在融合文本信息的时候效果总体要优于不融合文本信息,其次再叠加模态信息时,总体效果也随着增加。
总结
本文是针对多模态数据集的研究,对过往不同模态信息融合方法的不足的改进,提出了不同模态信息拼接之后传入bilstm-attention模块中学习拼接后的语义信息和上下文特征信息。最终通过实验证明该该种不同模态信息融合方法的有效性。
文章出处登录后可见!