(零)AlexNet前言知识
0.1 常用公式
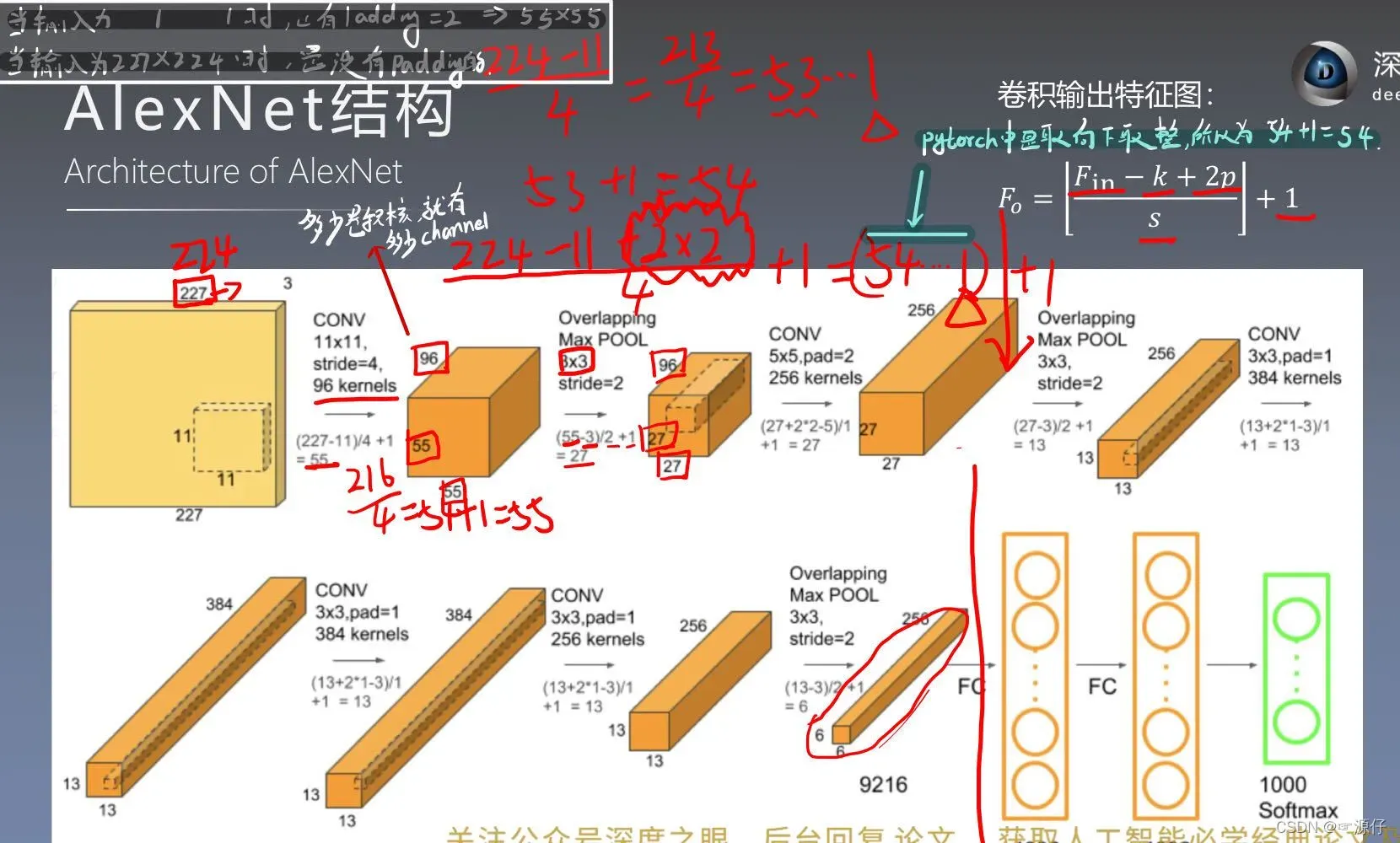
卷积输出特征图维度计算公式:
=
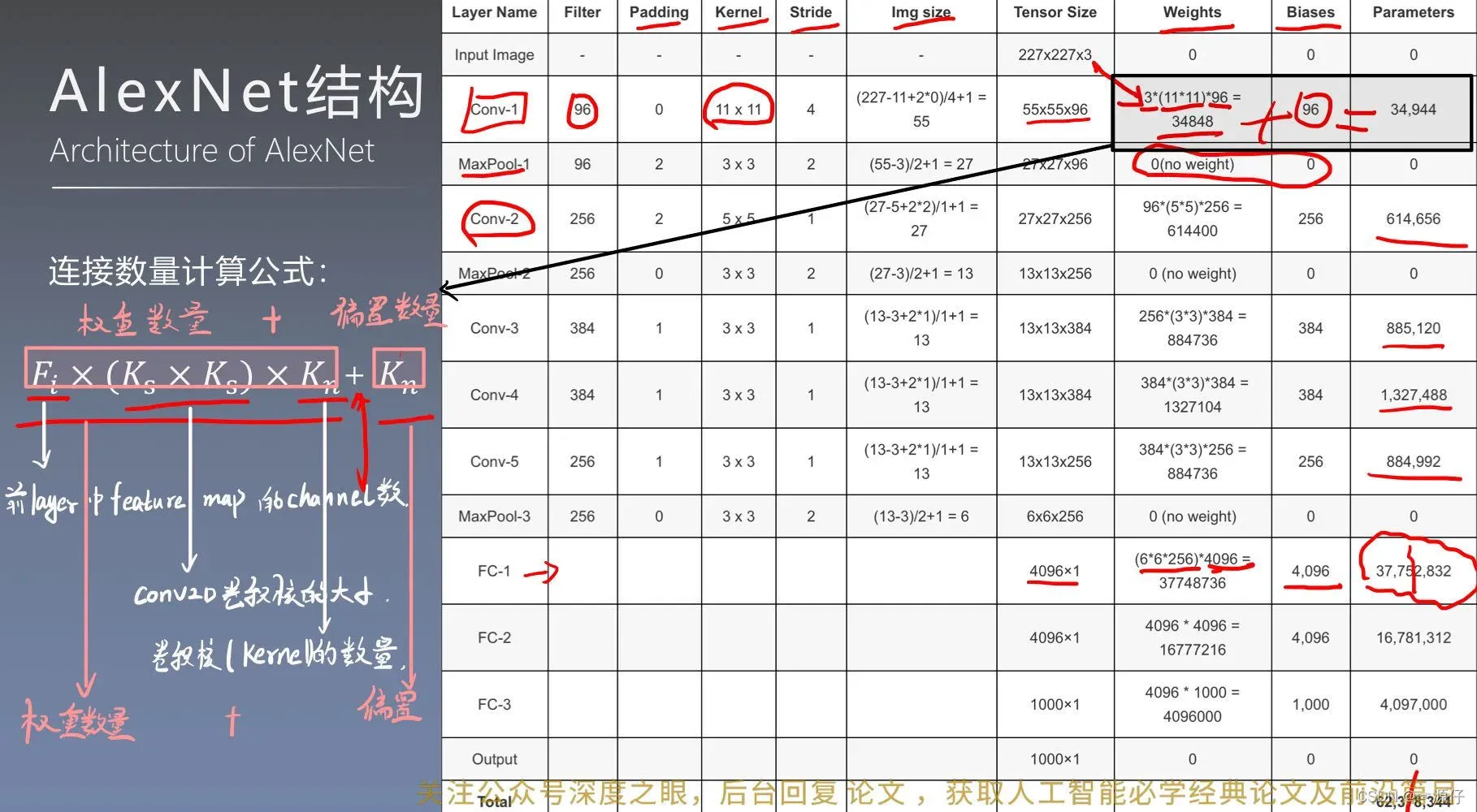
连接数量计算公式:
=
:前一层Feature Map的channel数。
:卷积核的大小
:卷积核的数量
:偏置的数量=卷积核的数量
0.2 深度学习的宏观框架
深度学习的宏观框架——训练(training)和推理(inference)及其应用场景
json.loads()加载json数据的方法:用于将str类型的数据转成dict。
- 训练(Training)
打个比方,你现在想要训练一个能区分苹果还是橘子的模型,你需要搜索一些苹果和橘子的图片,这些图片放在一起称为训练数据集(training dataset),训练数据集是有标签的,苹果图片的标签就是苹果,橘子亦然。一个初始神经网络通过不断的优化自身参数,来让自己变得准确,可能开始10张苹果的照片,只有5张被网络认为是苹果,另外5张认错了,这个时候通过优化参数,让另外5张错的也变成对的。这整个过程就称之为训练(Traning)。
- 推理(Inference)
你训练好了一个模型,在训练数据集中表现良好,但是我们的期望是它可以对以前没看过的图片进行识别。你重新拍一张图片扔进网络让网络做判断,这种图片就叫做现场数据(live data),如果现场数据的区分准确率非常高,那么证明你的网络训练的是非常好的。我们把训练好的模型拿出来遛一遛的过程,称为推理(Inference)。
- 部署(deployment)
想要把一个训练好的神经网络模型应用起来,需要把它放在某个硬件平台上并保证其能运行,这个过程称之为部署(deployment)。
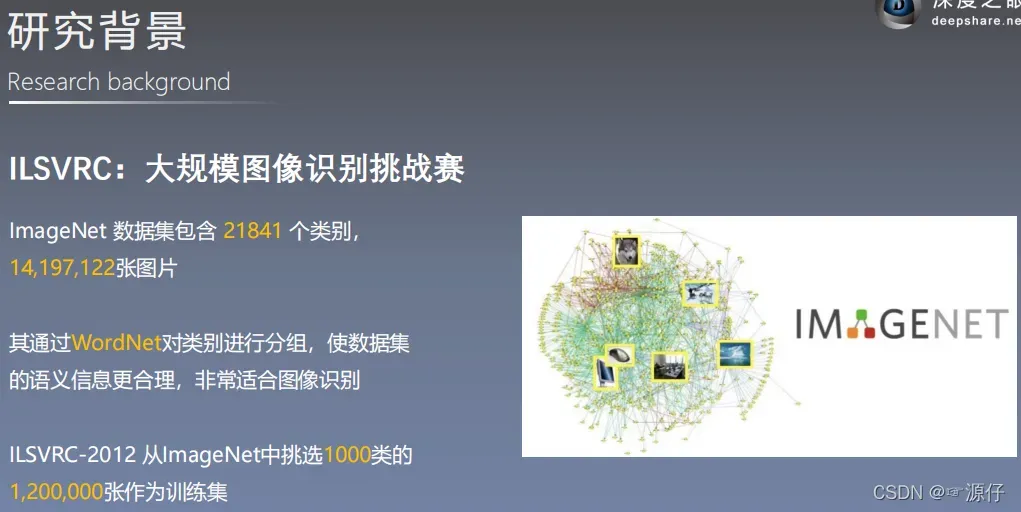
0.3 ImageNet数据集
- ImageNet数据集
LSVRC大规模图像识别挑战赛/2012官网
ImageNet官网
那Top-1 Accuracy和Top-5 Accuracy是指什么呢?区别在哪呢?
- 首先是TOP-5正确率,
举个例子,比如你训练好了一个网络,你要用这个网络去进行图片分类任务,假设要分类的数目有50类,那么当我们进行测试时,输入一张图片,网络会依次输出这50个类别的概率,当所有图片测试完成后,那么:
TOP-5正确率就是说,在测试图片的50个分类概率中,取前面5个最大的分类概率,正确的标签(分类)有没有在里面,就是它是不是这前5个中的一个,如果是,就是分类成功.- TOP-5正确率=(所有测试图片中正确标签包含在前五个分类概率中的个数)除以(总的测试图片数)
- TOP-5错误率=(所有测试图片中正确标签不在前五个概率中的个数)除以(总的测试图片数)
同理,TOP-1错误率就是正确标记的样本数不是最佳概率的样本数除以总的样本数

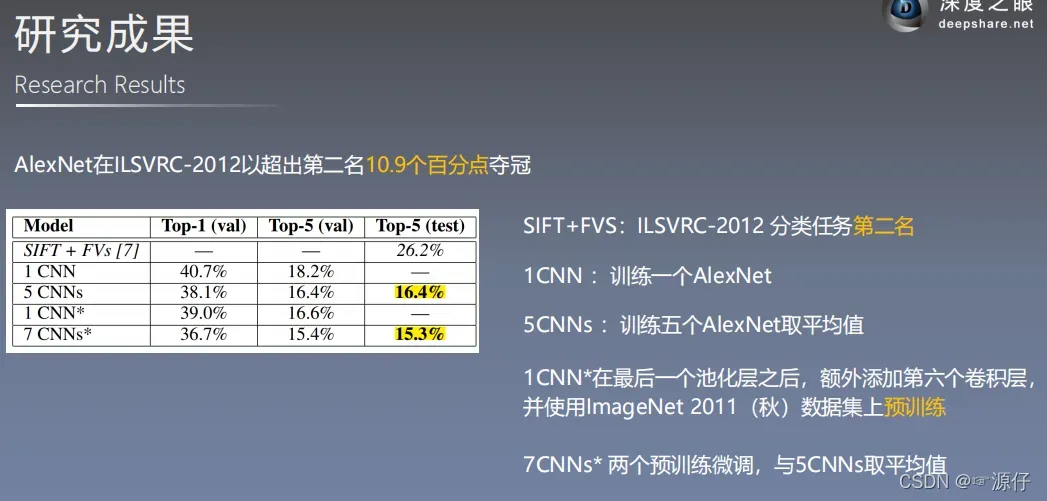
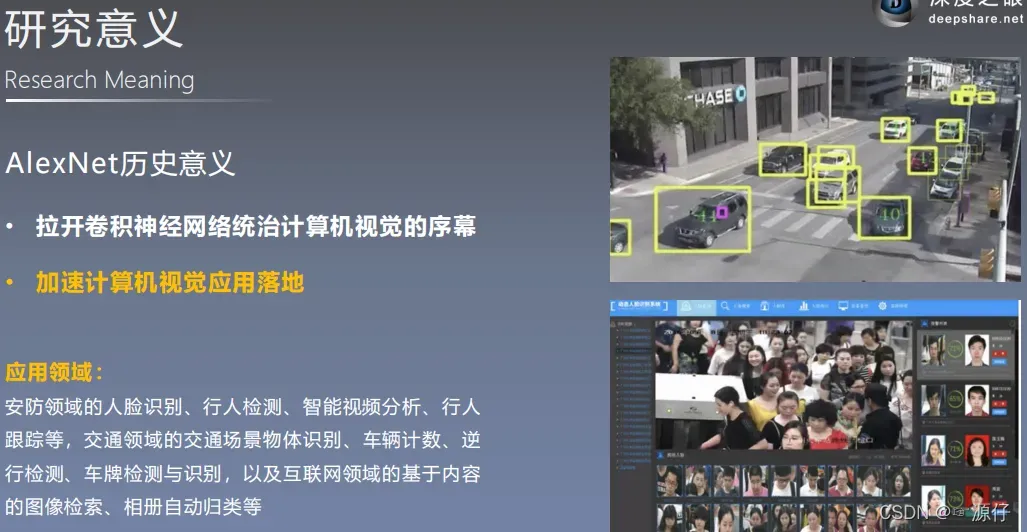
AlexNet的历史意义

其中**SIFT+FVs是2012年的季军,7CNNs*是2012年的AlexNet冠军模型,其中2个AlexNet用于预训练微调和训练5个AlexNet取平均值。5CNNs**是当时的亚军,也是AlexNet。

AlexNet完整结构图
(一)alexnet_inference.py 分析
1.1 transforms.Compose()
# hard code
# 通过ImageNet数据统计得到,RGB三个通道的mean和std
norm_mean = [0.485, 0.456, 0.406] # Through the ImageNet statistics, it is RGB three channels(mean and std).
norm_std = [0.229, 0.224, 0.225]
# transforms.Compose():Pytorch中的图像预处理包,将多个步骤整合到一起
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
transforms.Compose()
下面介绍transforms中的函数:
- Resize:把给定的图片resize到given size
- Normalize:Normalized an tensor image with mean and standard deviation
- ToTensor:将一个取值范围是
[0,225]的PIL图像或形状为[H,W,C]的数组,转换成形状为[C,H,W],取值范围是[0,1.0]的张量(torch.FloadTensor) - ToPILImage: convert a tensor to PIL image
- Scale:目前已经不用了,推荐用Resize
- CenterCrop:在图片的中间区域进行裁剪
- RandomCrop:在一个随机的位置进行裁剪
- RandomHorizontalFlip:以0.5的概率水平翻转给定的PIL图像
- RandomVerticalFlip:以0.5的概率竖直翻转给定的PIL图像
- RandomResizedCrop:将PIL图像裁剪成任意大小和纵横比,再变换为给定大小
- Grayscale:将图像转换为灰度图像
- RandomGrayscale:将图像以一定的概率转换为灰度图像
- FiceCrop:把图像裁剪为四个角和一个中心
- TenCrop
- Pad: 将图像所有边用给定的pad value填充
- ColorJitter:随机改变图像的亮度对比度和饱和度。
1.2 unsqueeze_()
# path --> img
# Loading pictures
#如果不使用.convert('RGB')进行转换的话,读出来的图像是RGBA四通道的,A通道为透明通道
img_rgb = Image.open(path_img).convert('RGB')
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # [c,h,w] 增维成 [b,c,h,w]
# to(device):最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
PIL图像处理标准库——convert(‘RGB’)
pytorch中unsqueeze_(增加维度)的用法
Pytorch 学习笔记–to(device)的用法
1.3 AlexNet(nn.Module)
nn.AdaptiveAvgPool2d()
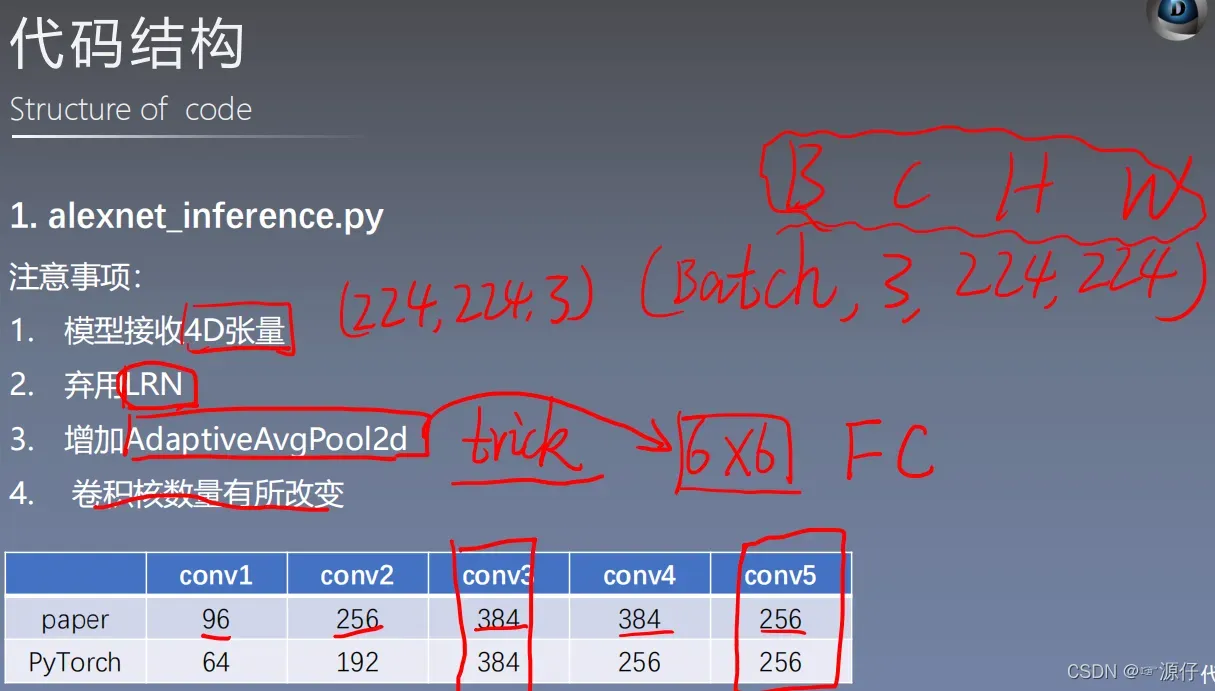
Pytorch中的AlexNet更改了原论文中的一些卷积核的数量
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# conv1
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 96 --> 64
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 3 > 2
# conv2
nn.Conv2d(64, 192, kernel_size=5, padding=2),# 384 --> 256
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# conv3
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# conv4
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# conv5
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 自适应平均池化,指定输出(H,W)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # trick
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
1.4 加载预训练的模型参数pretrained_state_dict
Pytorch中model.eval的作用
在Pytorch上使用torchsummary中的summary
def get_model(path_state_dict, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.alexnet()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict) # 导入语预训练模型的参数
model.eval() # 因为我们不训练,所以用这个,保证模型参数不变。
if vis_model:
from torchsummary import summary
# summary打印显示网络结构和参数
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
1.5 inference
# 3/5 inference tensor --> vector
torch.no_grad():# 在前向传播中加入这个,可以加快运算速度,减少内存消耗,因为前向传播不需要计算梯度
with torch.no_grad():
time_tic = time.time()
outputs = alexnet_model(img_tensor) # 直接把图片传递给模型
time_toc = time.time()
1.6 输出Top1和Top5概率
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1) # pred_int:Top-1对应的索引
_, top5_idx = torch.topk(outputs.data, 5, dim=1) # top5_idx:Top-5对应的索引
pred_idx = int(pred_int.cpu().numpy())
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx] # 找出pred_idx:Top-5索引所对应标签的名字
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming:{:.2f}s".format(time_toc - time_tic))
1.7 图像显示
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()
Output As Following:

版权声明:本文为博主☞源仔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_54546190/article/details/122472264