一、迁移学习与微调
ImageNet 数据集大约有 120w 个样本,类别数为 1000;MNIST 数据集只有 6w 个样本,类别数为 10。然而,我们平常接触到的数据集的规模通常在这两者之间。
假如我们想识别图片中不同类型的椅子,然后向用户推荐购买链接。 一种可能的方法是首先识别 100 把普通椅子,为每把椅子拍摄 1000 张不同角度的图像,然后在收集的图像数据集上训练一个分类模型。 尽管这个椅子数据集可能大于 Fashion-MNIST 数据集,但实例数量仍然不到 ImageNet 中的十分之一。 适合 ImageNet 的复杂模型可能会在这个椅子数据集上过拟合。 此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。
为了解决上述问题,一个显而易见的解决方案是收集更多的数据。 但是,收集和标记数据可能需要大量的时间和金钱。 例如,为了收集 ImageNet 数据集,研究人员花费了数百万美元的研究资金。 尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
另一种解决方案是应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。 例如,尽管 ImageNet 数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
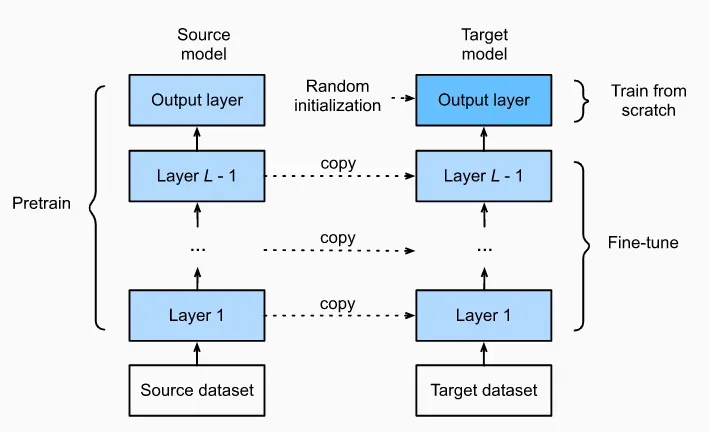
迁移学习中的一个常见的技巧是微调(fine-tuning),它包括以下四个步骤:
- 在源数据集(例如 ImageNet)上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
因为是微调,我们通常选用较小的学习率,例如
,且训练的 epoch 数也要少。
二、如何寻找预训练的模型?
这里提供两种方案。
- 使用 PyTorch 官方的预训练模型(链接),这些模型均在 ImageNet 上完成了预训练。使用时需要设置
pretrained参数为True。 - 使用
timm包(github链接、timm文档)。
本文接下来的部分将使用第一种方案。
三、初始化模型
我们使用在 ImageNet 数据集上预训练的 ResNet-18 作为源模型,重新设置输出层并将其随机初始化:
net = torchvision.models.resnet18(pretrained=True)
net.fc = nn.Linear(512, 10) # 设置为10是因为接下来要面对十分类任务
nn.init.xavier_uniform_(net.fc.weight)
四、将 ResNet 迁移到 CIFAR-10 上
接下来,我们将 ResNet-18 迁移到 CIFAR-10 数据集上并进行微调。
需要注意的是,所有预训练的模型在接收输入时,必须将它们以下面的方式进行归一化:
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
处理 CIFAR-10 数据集:
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize,
])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize,
])
train_data = torchvision.datasets.CIFAR10('/mnt/mydataset', train=True, transform=train_augs, download=True)
test_data = torchvision.datasets.CIFAR10('/mnt/mydataset', train=False, transform=test_augs, download=True)
train_loader = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=6)
test_loader = DataLoader(test_data, batch_size=128, num_workers=6)
设置学习率为 ,只训练 10 个 epoch
e = E(train_loader, test_loader, net, 10, 5e-4)
e.main()
在 NVIDIA GeForce RTX 3090 上的训练/测试结果如下:
Epoch 10
--------------------------------------------------
Train Avg Loss: 0.866763, Train Accuracy: 0.696940
Test Avg Loss: 0.498987, Test Accuracy: 0.828300
--------------------------------------------------
3273.3 samples/sec
--------------------------------------------------
Done!
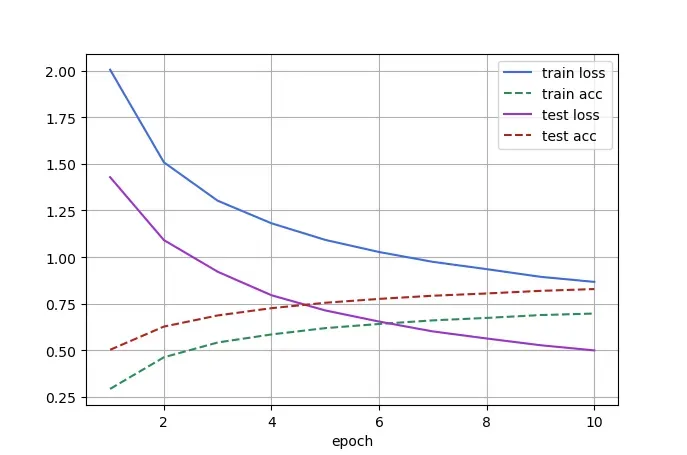
通过与这篇文章进行比较可以看出,使用迁移学习的方法后,ResNet-18 在测试集上的精度更胜一筹(虽然胜的不多)。并且这仅仅是训练了 10 个 epoch,从测试集的损失函数曲线变化来看,继续训练可以进一步提升精度。
文章出处登录后可见!