学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
作为征战多年数据科学领域的小伙伴都很清楚,获取和清理数据的初始步骤会占据工作的 80%,花费大量时间来清理数据集并归结为可以使用的形式。
因此如果是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值、不一致的格式、格式错误的记录还是无意义的异常值。
可以利用 Python 的 Pandas和 NumPy 库来清理数据。

准备工作
数据使用的是《三国志 13》中的武将数据信息,导入模块后就开始正式的数据预处理吧。
import pandas as pd
import numpy as np
DataFrame 列的删除
通常会发现并非数据集中的所有数据类别都有用。
例如我们统计人物基本能力的属性的时候可能生卒年、寿命、死因等等这些数据就没有用了,所以保留这些不需要的数据将占用不必要的空间。
人物详情数据.xlsx 数据操作。
df = pd.read_excel('Romance of the Three Kingdoms 13/人物详情数据.xlsx',sheet_name="包含null")
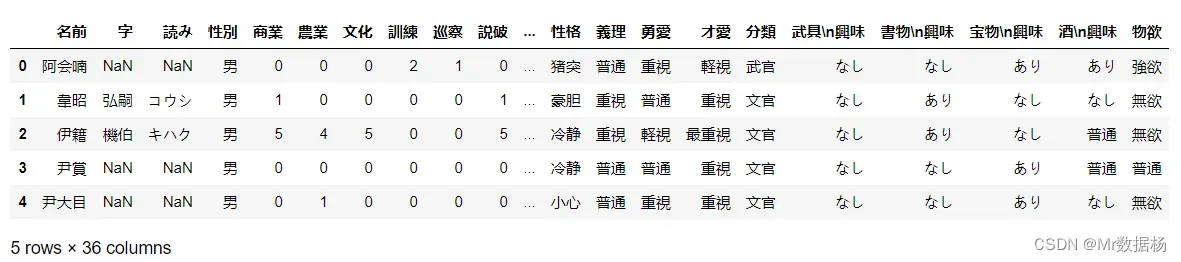
df.head()

可以看到这些列是对 生年、登場、没年、寿命、死因、父親、母親、相性、列伝 没有任何信息帮助的,因此可以进行批量删除处理。
to_drop_column = [ '生年','登場','没年','寿命','死因','父親','母親','相性','列伝']
df.drop(to_drop_column , inplace=True, axis=1)
df.head()
DataFrame 索引更改
Pandas 索引扩展了 NumPy 数组的功能,以允许更通用的切片和标记。 在许多情况下,使用数据的唯一值标识字段作为其索引是有帮助的。
获取唯一标识符。
df['名前'].is_unique
True
名前 列替换索引列。
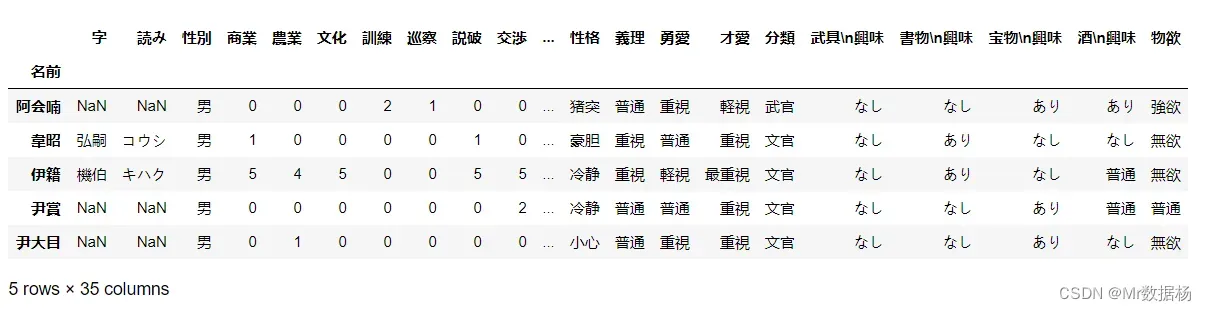
df = df.set_index('名前')
df.head()
DataFrame 数据字段整理
清理特定列并将它们转换为统一格式,以更好地理解数据集并强制保持一致性。
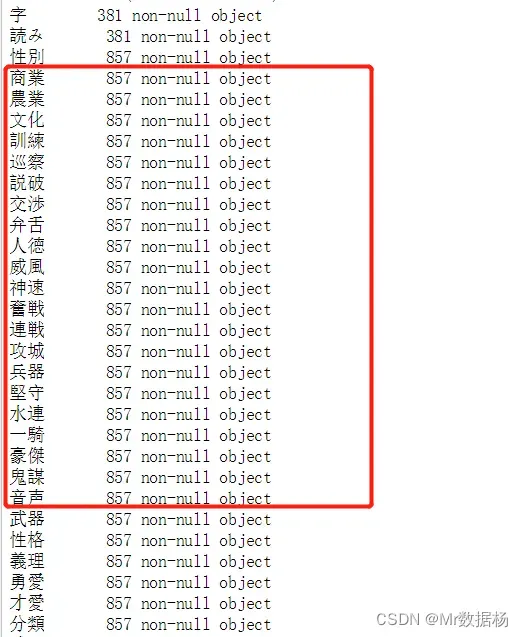
处理 商業,農業,文化,訓練,巡察,説破,交渉,弁舌,人徳,威風,神速,奮戦,連戦,攻城,兵器,堅守,水連,一騎,豪傑,鬼謀 列的时候由于是 int 类型因此,后续处理需要转换成 object 类型。
df.info()

进行数据类型强制转换成object。
process_columns = [
'商業', '農業', '文化', '訓練', '巡察', '説破', '交渉',
'弁舌', '人徳','威風', '神速', '奮戦', '連戦', '攻城',
'兵器', '堅守', '水連', '一騎', '豪傑', '鬼謀'
]
for name in process_columns:
df[name] = df[name].astype(str)
df.info()
str 方法与 NumPy 结合清理列
df[‘xxxx’].str 。 此属性是一种在 Pandas 中访问快速字符串操作的方法,这些操作在很大程度上模仿了对原生 Python 字符串或编译的正则表达式的操作,例如 .split()、.replace() 和 .capitalize()。
要清理某些行、列字段,可以将 Pandas 的 str 方法与 NumPy 的 np.where 函数结合起来,该函数基本上是 Excel 的 IF() 宏的矢量化形式。
"""
condition 要么是一个类似数组的对象,要么是一个布尔掩码
then 是如果条件评估为
True 时使用的值,否则是要使用的值
"""
np.where(condition, then, else)
本质上 .where() 获取用于条件的对象中的每个元素,检查该特定元素在条件上下文中的计算结果是否为 True,并返回一个包含 then 或 else 的 ndarray,具体取决于哪个适用。可以嵌套在复合 if-then 语句中,允许根据多个条件计算值.
处理 武器 列数据。
df['武器'].head(10)
名前
阿会喃 刀
韋昭 弓
伊籍 弓
尹賞 弓
尹大目 弓
尹黙 弓
于禁 戟
于詮 刀
衛瓘 刀
袁遺 弓
Name: 武器, dtype: object
使用包含的方式提取需要的数据信息。
data = df['武器']
data_ = data.str.contains('刀')
data_[:5]
名前
阿会喃 True
韋昭 False
伊籍 False
尹賞 False
尹大目 False
Name: 武器, dtype: bool
也可以使用 np.where 处理。
broadsword
df['武器_en'] = np.where(
data_,
'broadsword',
data.str.replace('刀', 'broadsword')
)
名前
阿会喃 broadsword
韋昭 弓
伊籍 弓
尹賞 弓
尹大目 弓
...
卑弥呼 弓
韓世忠 槍
梁紅玉 槍
范蠡 弓
荀灌 broadsword
Name: 武器_en, Length: 857, dtype: object
apply 函数清理整个数据集
自定义函数应用于 DataFrame 的每个单元格或元素。 Pandas.apply() 方法类似于内置的 map() 函数,只是将函数应用于 DataFrame 中的所有元素。
将数据的发布日期进行处理成 xxxx 年的格式,就可以使用apply。
def clean_date(text):
try:
return str(int(text)) + "年"
except:
return text
df = pd.read_excel('Romance of the Three Kingdoms 13/人物详情数据.xlsx',sheet_name="包含null")
df["new_生年"] = df["生年"].apply(clean_date)
df["new_生年"]
0 190年
1 204年
2 162年
3 194年
4 211年
...
852 169年
853 170年
854 170年
855 170年
856 170年
Name: new_生年, Length: 857, dtype: object
DataFrame 跳过行
df = pd.read_excel('Romance of the Three Kingdoms 13/人物详情数据.xlsx',sheet_name="包含null")
df.head()
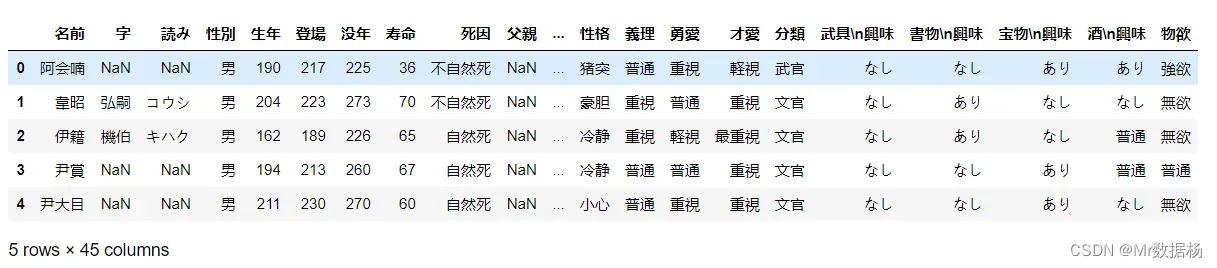
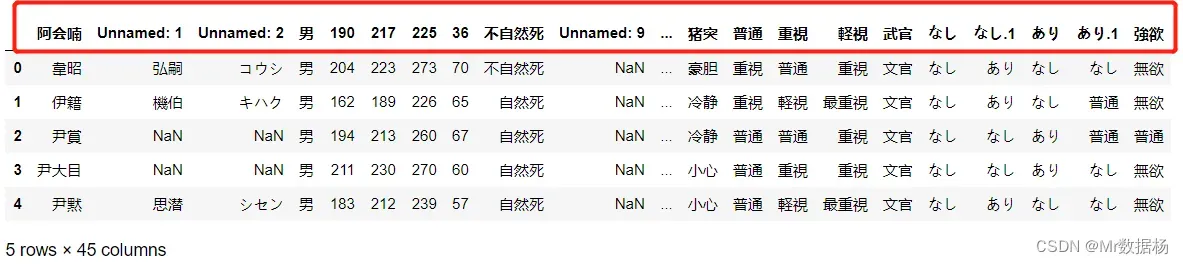
可以在读取数据时候添加参数跳过某些不要的行,比如索引 0 行。
df = pd.read_excel('Romance of the Three Kingdoms 13/人物详情数据.xlsx',sheet_name="包含null",header=1)
df.head()
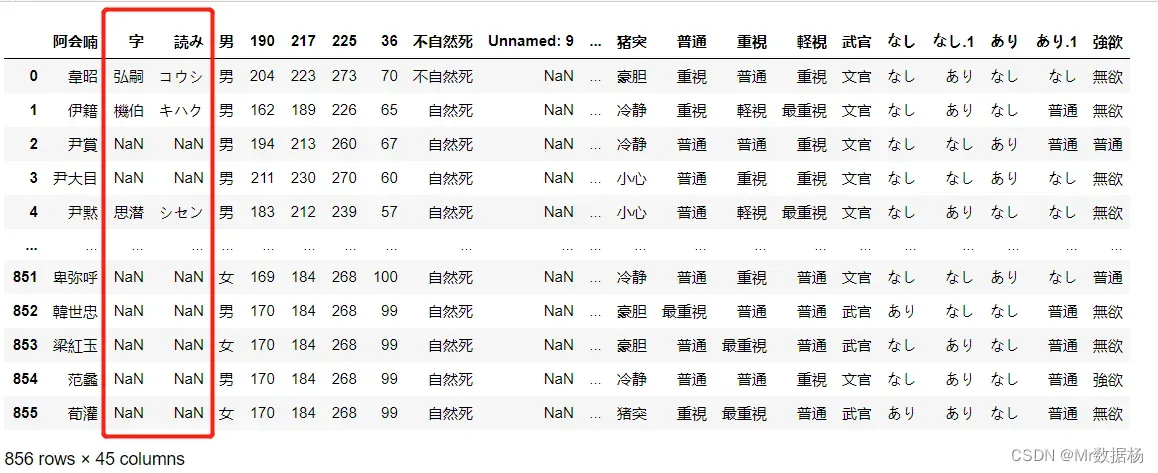
DataFrame 重命名列
df.rename(columns={
'Unnamed: 1':'字',
'Unnamed: 2':'読み'
},inplace = True)
df.head()
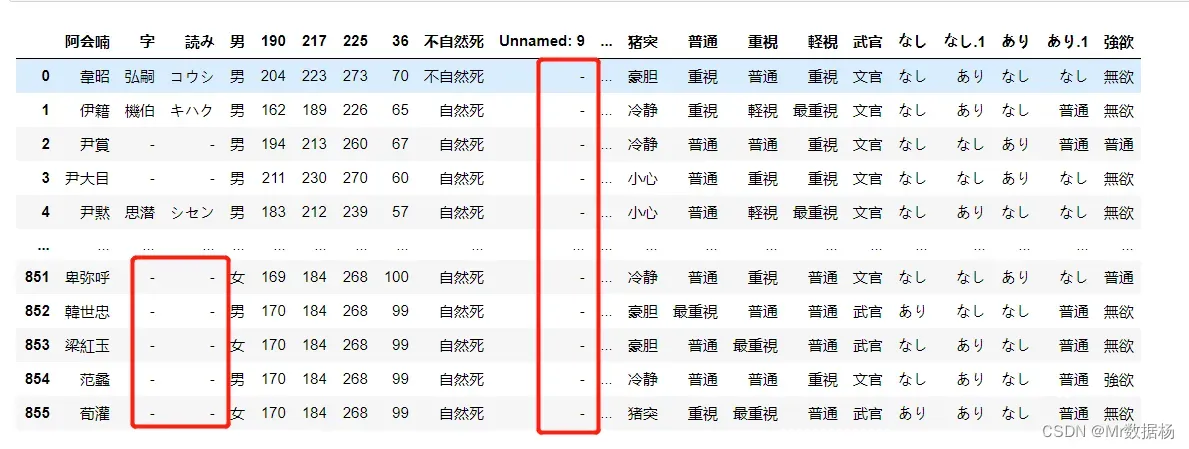
DataFrame 填充缺失值
缺失值一般在数据读取到 Dataframe 中用 NaN 显示。这种数据很讨厌,无法参与各种数据处理,所以需要统一进行处理一下。
基础填充缺失值方法使用的是 .fillna(),需要填写填充缺失值替换的数据。
df.fillna("-")
文章出处登录后可见!