本案例介绍 NLP 最基本的任务类型之一 :文本语义匹配,并且基于 PaddleNLP 使用百度开源的预训练模型 ERNIE-Gram 搭建效果优异的语义匹配模型,来判断 2 段文本语义是否相同。
本章详细分析了数据预处理的整个流程,用以学习阶段的记录。
前言:
文本语义匹配任务,简单来说就是给定两段文本,让模型来判断两段文本是不是语义相似。
在本案例中以权威的语义匹配数据集 LCQMC 为例,LCQMC 数据集是基于百度知道相似问题推荐构造的通问句语义匹配数据集。训练集中的每两段文本都会被标记为 1(语义相似) 或者 0(语义不相似)。
具体流程
导入相关库
# 文本语义近似度计算
import time
import os
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
import paddlenlp
首先,获取Lcqmc的训练集和验证集
train_ds, dev_ds = load_dataset("lcqmc", splits=["train", "dev"])
预训练模型是ERNIE-GRAM,需要加载属于它的tokenizer(ernie-gram-zh按单个单词切分),对于train_ds需要根据相应tokenizer进行切分
tokenizer = paddlenlp.transformers.ErnieGramTokenizer.from_pretrained('ernie-gram-zh')
将train_ds进行一系列操作后,封装到DataLoader中,方便快速读取
train_data_loader = paddle.io.DataLoader(
dataset=train_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
-
dataset:train_ds的二次封装,封装函数为trans_func
# 为了后续方便使用,我们使用python偏函数(partial)给 convert_example 赋予一些默认参数 from functools import partial # 训练集和验证集的样本转换函数 trans_func = partial( convert_example, tokenizer=tokenizer, max_seq_length=512) #对convert_example()进行二次封装,tokenizer和max_seq_length都是固定值了 利用偏函数对convert_example进行封装,convert_example函数里的tokenizer和max_seq_length都是固定值了
而关键的函数转换函数convert_example,将输入文本转换成id值,在训练阶段返回input_ids, token_type_ids, label
def convert_example(example, tokenizer, max_seq_length=512, is_test=False): query, title = example["query"], example["title"] encoded_inputs = tokenizer(text=query, text_pair=title, max_seq_len=max_seq_length) input_ids = encoded_inputs["input_ids"] token_type_ids = encoded_inputs["token_type_ids"] if not is_test: label = np.array([example["label"]], dtype="int64") return input_ids, token_type_ids, label # 在预测或者评估阶段,不返回 label 字段 else: return input_ids, token_type_ids -
batch_sample:自动对训练数据进行切分,支持多卡并行训练
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=32, shuffle=True) -
collate_fn:需要将样本组合成 Batch 数据,对于不等长的数据还需要进行 Padding 操作,便于 GPU 训练。
说人话就是对转换后的Id值进行补0填充,目的是为了保证数据的一致性,然后将这三个组成一个二维矩阵
from paddlenlp.data import Stack, Pad, Tuple batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids Stack(dtype="int64") # label ): [data for data in fn(samples)] -
return_list:返回一个列表
利用迭代器,看看第一批(batchsize=32)的train_data_loader里装了什么
print(next(iter(train_data_loader)))
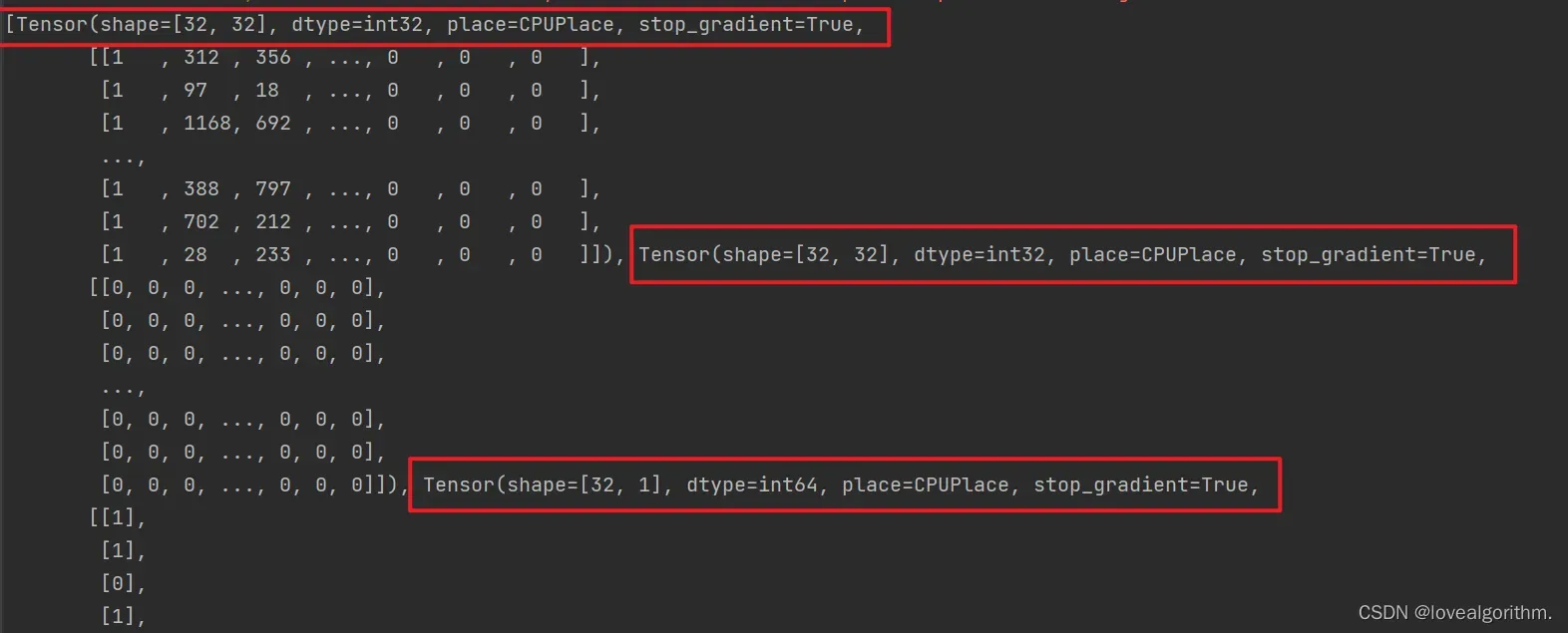
可以看到装了三个tensor,对应的分别是input_ids(输入的文字根据tokenizer转成id), token_type_ids(区别不同的句子), label(1为两句话相似,0为不相似)
由此可以得出第一批train_data_loader里装了32行tarin_ds里的文字
打印第一组的input_ids, token_type_ids, label
input_ids, token_type_ids, label=next(iter(train_data_loader))
print(input_ids[0])
print(token_type_ids[0])
print(label[0])
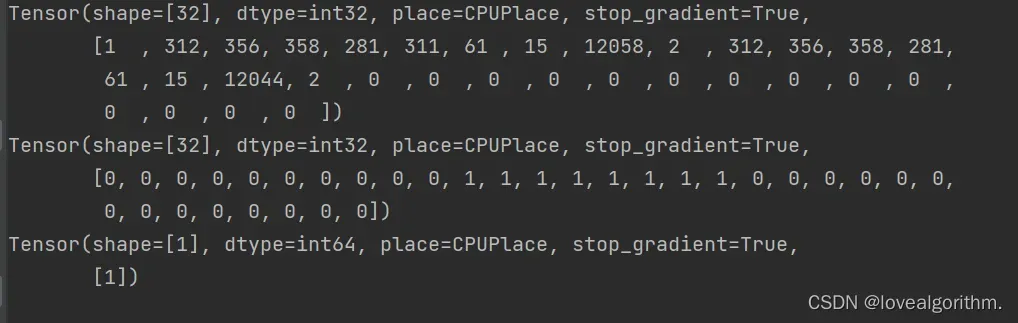
可以看到,数据经过了一系列的处理,填充了很多0保持了数据的一致性。
第一个tensor里表示的是随机抽选的train_ds里一行输入的query和title全部转化成了对应的token,其中的1和2比较特殊
查看ernie_gram_zh的词表可以发现,前四行是
[PAD]
[CLS] 标志放在第一个句子的首位 —-1
[SEP]标志用于分开两个输入句子 —-2
[MASK] 标志用于遮盖句子中的一些单词
第二个tensor里用0和1区分query和title
第三个tensor里表示两句话是否相似,值为1表示相似。
文章出处登录后可见!