

Multi-hop Reading Comprehension through Question Decomposition and Rescoring
作者:Sewon Min、Victor Zhong
机构:University of Washington、AI2
期刊:ACL2019
简介
多跳阅读理解需要根据问题聚合多个段落的信息回答问题,因此作者提出了将复杂多跳问题分解为多个简单问题,利用400条语料训练可直接使用单跳阅读理解模型进行答案抽取。同时引入global rescoring approach方法考虑每个子问题的答案从中选择最优答案。该方法在HotpotQA数据集上达到SOTA结果。
例子简介:

将Which team does the player named 2015 Diamond Head Classic’s MVP play for?问题分解成两个子问题:

Which player named 2015 Diamond Head Classic’s MVP?Which team does ANS play for?
其中第二个问题中ANS代替第一个子问题的答案。
方案流程
- DECOMPRC通过基于
type的span抽取,将多跳问题分解为多个子问题。目前类型分为:comparison、intersection、Bridging三种类型 - 每个子问题使用单跳阅读理解模型抽取答案,问题类型不同,答案也不一致。
decomposition scorer进行判断那个问题的答案是最合适的答案。
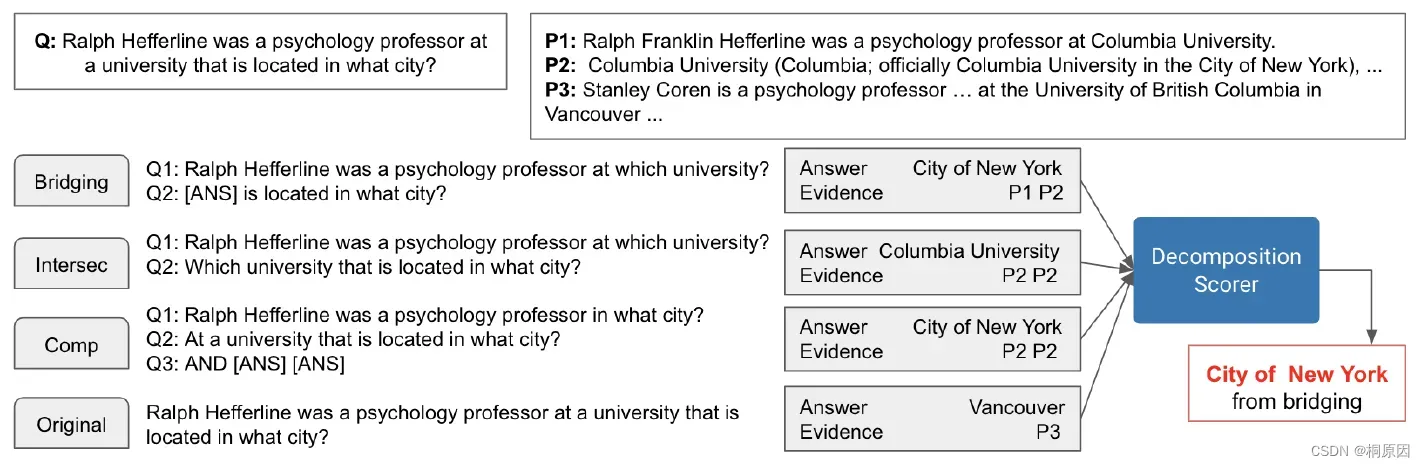

1)Decomposition
类型的来源根据HotPotQA相关论文中进行分类的,作者也从HotPotQA dev数据集中抽样200条数据进行验证,发现82%的问题类型都属于这三种情况。

分解问题关键思想:每个子问题都可以从原始问题中抽取key span复制并进行轻微修改。并根据不同类型问题进行不同的span抽取。
如上图中所示,对于Bridging问题,可直接将问题分解,抽取关键部分分为两个问题。

| 问题类型 | 拆解方法 |
|---|---|
| Bridging | 直接抽取出key span,生成两个问题 |
| intersection | 也可直接抽取出需要的条件,作为子问题 |
| comparison | 直接抽取实体,并分别组成问题 |
span extract
模型框架采用BERT+Softmax进行span抽取
获取到不同类型的start、end位置坐标,根据类型进行子问题生成
这里有一个疑问:对于Bridging类型的问题,只需要两个ind即可拆分问题,疑问词放在ind的start之前就好。但是表格算法中确使用了三个ind,好像把疑问词放在句子中。和上文描述不是很相符。

2)Single-hop Reading Comprehension
获取到每个问题,利用squad的Bert抽取式模型,对每个问题进行答案抽取。采用多任务学习,将答案分类span、yes、no、不存在四种类型。
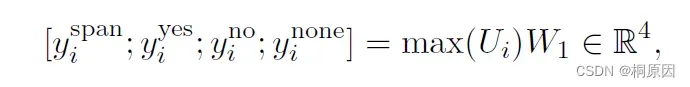
其中,Ui为子问题与第i个段落拼接通过BERT得到的隐层信息,max为max pooling操作。

3)Decomposition Scorer
选择答案最高分作为最终答案。
将问题、问题类型、答案、证据拼接通过BERT获取隐层U_t。
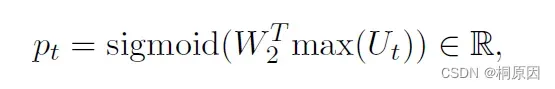
计算出得分矩阵并进行分数比较,获得最终答案。

Experiments
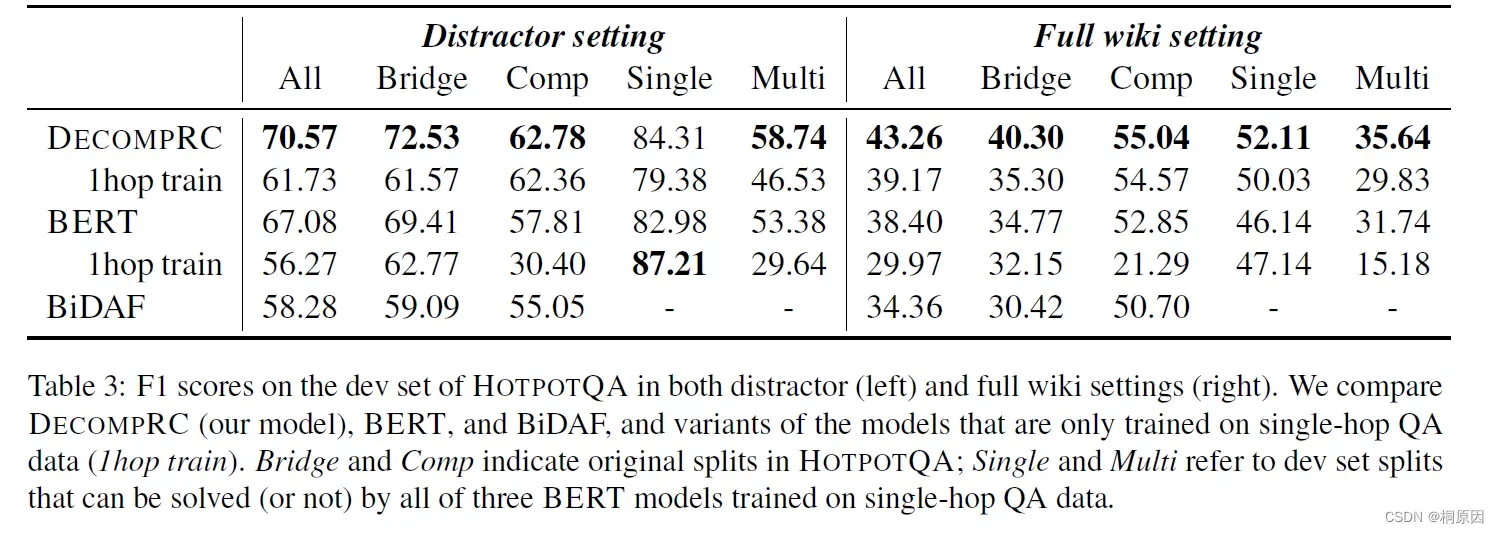
看到作者提出的模型效果达到SOTA

Limitations
但是这个方法还有一定的局限性,1. 有的问题需要具备一定常识知识才能回答,2.有的问题较为implicit多跳,无法进行问题拆分。3.有的问题超出了类型,如加法、计算
思考:
通过问题转化将多跳转为多个一跳问题,相比于目前以建图推理为主,显得简单,但目前榜单前排仍然是以建图的方法为主。
整个流程方法都较为简单,如果能增加更多操作(如:段落选择、答案抽取等模块),是否效果会更好。
文章出处登录后可见!