前一篇《(一)大话深度学习编译器中的自动调优·前言》介绍了深度学习编译器及早期算子自动调优的背景,在接下去更深入地聊自动调优具体方法之前,在这篇中想先聊下两个与之密切相关的重要基础概念:领域专用语言(Domain-specific Language,DSL)与中间表示(Intermediate Representation,IR)。DSL与IR在整个深度学习编译器中的位置大体如下:
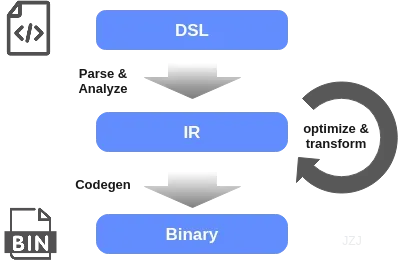
要实现高性能kernel中schedule参数的自动搜索,大致有几个基本要素:一是定义搜索空间,二是指定搜索的目标函数,三是应用搜索方法。另外现代主流方法中还会结合cost model加速搜索。其中第一步就得定义搜索空间,而且搜索空间的定义是否完备与优雅也直接影响着搜索的效果与效率。DSL与IR在搜索空间的定义上起着关键的作用。
前一篇中提到,早期的auto-tuning的工作主要集中于特定的计算,如BLAS, FFT等。如果仅是对于这些特定的计算任务做auto-tuning,最方便的做法就在程序的模板中留下一些可调参数来实现。虽然这类计算的应用确实非常广,但实际中的张量计算远不只它们。对于更为广泛和复杂的计算,如各种图像处理的pipeline,线性代数中的各种矩阵分解,以及机器学习模型中的各种算子,如果都用这种模板加可调参数的方式的话不够灵活,也不够优雅。因此,这就对于编程语言及中间表示提出了更高的要求。另外,考虑到自定义算子的需要,还需要考虑到易用性和开发效率。
张量计算编程方式
首先,开发者需要描述算法,自然就要通过某种语言。而对于机器学习的workloads,其特点是很多都是张量计算,而张量计算天然具有并行优化的机会。总得来说,开发者的核心需求是能用尽可能简单的方式进行表达,同时能够产生目标平台上的高性能实现。这本质上是要兼顾开发效率、性能与平台移植性。遗憾的是,这之间是有一些矛盾的。考虑两种常见的方式:一是通过low-level的语言获得最大的性能但牺牲开发效率;二是通过high-level的库达到好的移植性但可能会牺牲一些性能。它们各有局限,那我们如何既得到极致的性能,又有好的平台移植性,还可以兼顾开发效率呢?
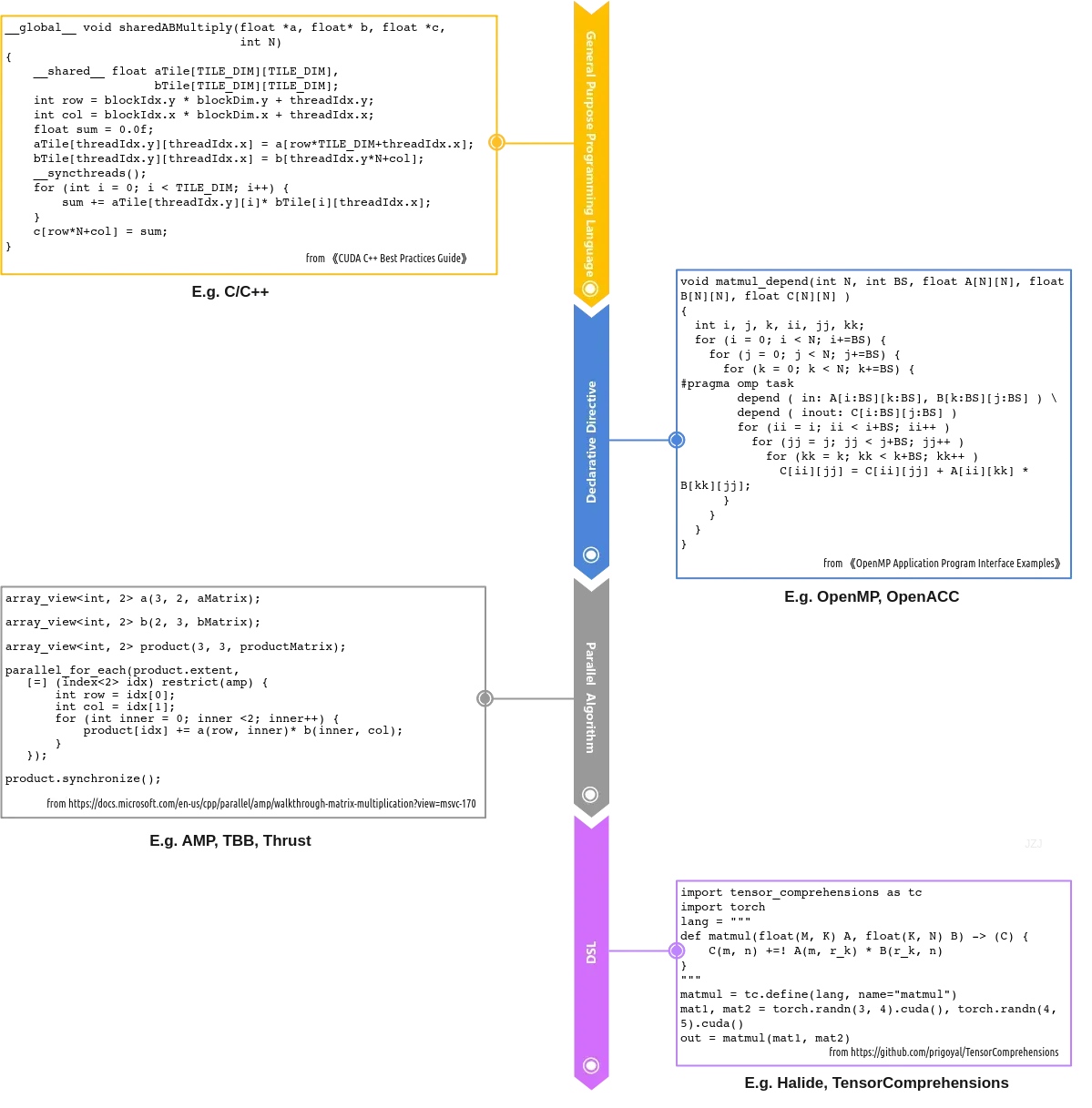
我们先简单回顾一下,对于张量并行计算,有哪些主要的表达方式。下面列了几种常见的类型,它们的抽象层次有所不同。
General-Purpose Programming Model
首先是通用编程语言(General-Purpose programming language),如C/C++。这也是最常见的。像CUDA,OpenCL之类是对C/C++的扩展,因此也算在此类。由于通用编程语言自由度非常大,编译器做程序分析的难度也很大,如灵活的指针使alias analysis变得很困难。编译器为了保证合法性与正确性,很多时候只能保守地认为存在依赖,从而失去了很多优化机会。毕竟编译器的原则是先求正确,再求快。要是一顿操作猛如虎,编译出来的东西跑得飞快,但结果不对,那就非常尴尬了。。。这样,程序的性能优化很大程度上就需要靠开发者来完成了。不同实现的性能差异与复杂度差异很大,要达到高性能通常需要大量专家经验的精力。同时由于很多优化依赖平台特性,所以代码可移植性通常比较差,而且一般是性能越好的移植性越差。我们来看最基础的矩阵乘法,要是按照数学公式来实现:
for (i = 0; i < M; i++) {
for (j = 0; j < N; j++) {
C[i,j] = 0.0;
for (k = 0; k < K; k++) {
C[i,j] = C[i,j] + A[i,k] * B[k,j];
}
}
}
这貌似也能说平台无关,但这样咱就没法聊了。。。正经的产品中,除非为了debug验证结果不会这么实现。毕竟咱们是目标是生成高性能的kernel,抛开性能聊就没意义了。而不同平台上经过深度优化的代码可以说是大相径庭的。比如ARM CPU上基于neon的实现(可参见链接:https://developer.arm.com/documentation/102467/0100/Matrix-multiplication-example,与NVIDIA GPU上基于Tensor Cores的实现(可参见官方sample:cudaTensorCoreGemm.cu),基本就是完全不同的两种风格。因此,换个平台差不多就等于重新开发,而且还需要特定硬件平台的领域知识。
Declarative Directive
第二种是基于通用编程语言的扩展。像比较典型的OpenMP, OpenACC属于此类。这种模式下,一般通过declarative directive对基于通用编程语言的代码进行annotation。再配合编程器生成高性能的实现。它本质上是通过这些语言扩展让程序员可以更好地表达意图,比如标注并行区域,数据间的依赖关系等。这些信息可以指导或者说帮助编译器的分析,便于实现更加aggressive的优化。
Parallel Algorithms
经过总结归纳,平时遇到的并行算法可以归纳成一些常见的范式,如for each,reduce,scan等。于是可以将这些通用算法实现为函数以库的形式提供,并通过仿函数、函数指针、函数对象,lambda表达式等手段允许开发者定义内层计算。通过这层抽象,并行计算的逻辑可以封装在库中,让开发者无需关心。一些芯片厂商可以结合自身的并行编程模型进行实现。举例来说,NVIDIA的Thrust是CUDA上基于STL的模板库。其好处是很多时候可以替换现有代码中的STL函数调用,从而达到在NVIDIA GPU上加速的目的。除了一些基础数据结构与函数,它提供了transform,for_each,reduce,inclusive_scan,exclusive_scan, sort等常见并行算法。 其中的计算通过仿函数或者函数对象来传入。类似地,Intel的TBB(Thread Building Blocks)中提供了parallel_for,parallel_do,parallel_reduce, parallel_pipeline, parallel_sort, parallel_invoke等算法。再如Microsoft的AMP(Accelerated Massive Parallelism)提供了parallel_for_each函数。
总得来说,这种方式可以有效降低并行加速程序的开发成本,同时降低了门槛。但它也把支持的计算受限于所提供的几种模式。同时自定义计算的部分对低层来说相当于黑盒,无法通盘考虑,可能会损失一些优化机会。
DSL(Domain-specific Language)
深度学习编译器主要面向特定领域的计算,它本质上是domain-specific compiler。那既然是面对特定领域,是不是可以用领域专用语言作为输入呢?这样,牺牲一些对于特定领域并不必需的语言灵活性,从而达到前面所说的目标。DSL指用于特定问题的具有高层抽象的编程语言。它的语法是对表达某个特定领域的语义所设计。DSL使用领域相关的概念与规则,可以让领域专家使用相关概念与符号进行建模的语言。比如用于科学计算的Matlab,数据库操作的SQL,统计分析中的R语言都可以算是DSL。DSL在形式上又可分别两种:一种是Embedded DSL。它通常会嵌入在某种宿主语言中。对应地,另一种是external DSL,它没有宿主语言。
前面提到,通用编程语言用于张量计算,难以做程序分析还原开发者意图,导致丢失很多优化机会。而这些信息开发者自然是知道的,DSL可以让开发者有效地传达这些信息。相对而言,DSL保留了高层的语义与约束,从而使DSL compiler可以执行高层的优化与转换。 DSL有利于开发效率与移植性,因为开发者无需考虑实现细节,并且代码可以做到与目标平台无关。它的主要作用之一是将平台相关的细节与计算的描述分离,从而避免切换硬件平台就要重新实现应用,从而提升平台移植性。要达到高性能,DSL还需要配合相应的compiler,通过auto-tuning这样的机制来获得针对特定目标平台的高性能实现。这样的组合我们简称为DSL compiler。DSL compiler的方式结合了开发效率、高性能与平台移植性,但同时也带来了巨大的挑战。理想情况下DSL基本只描述算法,而不会涉及如何算(即如何优化计算)的细节。因此,要达到高性能,编译器所承担的责任非常大。
我们知道,一个程序如果执行慢且是compute-intensive的(即不是阻塞在访存,IO上),那多半主要是花在循环上。而机器学习神经网络模型中的数据一般是张量(Tensor),这样很多计算就自然变成了多重嵌套循环(Nested loop)。这些嵌套循环是主要的优化对象之一。这种张量代数在数学上多用tensor index notation表示,如。它通过index variable来将结果中的每个元素与操作数中的元素相关联。那在程序中如何高效简洁地表示这种张量代数计算呢?一种比较流行的是爱因斯坦在1916年提出的爱因斯坦求和约定(Einstein summation convention)或称爱因斯坦标记法(Einstein notation)。在这种表示中,出现在等号右边,但不出现的左右的下标就是被约减的。比如matmul,可以表示为
ij, jk -> ik。除此之外,像转置、点积、外积、Hadamard积等都可以用它表示。这种表达方式因为很灵活、能打,因此在很多流行的计算框架或库中有它的身影,如Numpy,TensorFlow,PyTorch。前段时间ICLR上的论文《Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation》中的einops就是对爱因斯坦求和约定的改进,提高了代码的可读性和可维护性。
对于图像处理与机器学习领域,Halide可以说是影响最深远的DSL之一了。虽然Halide最开始主要用于图像处理,后面也逐渐用于机器学习,它对后面的DL compiler的发展也产生了很大的影响。2012年论文《Decoupling algorithms from schedules fro easy optimization of image processing pipeline》和2013年论文《Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines》比较详细地介绍了Halide。它提出的一个主要思想是将算法(Algorithm)与调度(Schedule)解耦分离。这种抽象可以使开发者快速探索代码优化的空间,方便进一步引入auto-tuning机制。其中algorithm指要算什么,一般可通过张量计算的数学表达式来表示。它通过函数式编程将图像处理的pipeline描述成整数域上的一系列的函数。而调度指的是针对特定平台如何进行计算,具体来说就是一系列原语控制计算在何地与何时进行。
这个思想催生了TVM等深度学习编译器。TVM中的TE(Tensor expression)使用lambda expression,采用类似Einstein’s notation的声明式的方式表示张量计算。同时,它抽象了一些主要针对循环的变换(如loop ordering, blocking, vectorization, unrolling, parallelization)形成一些调度原语,从而可以把它们交给编译器来解决。编译器的主要任务之一就是找到充分利用硬件资源的schedule。
另一个DSL的例子是2018年Facebook在论文《Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions》中介绍的Tensor Comprehensions项目。它提供了借鉴了Einstein notation思想的语言来表达张量计算。如matmul表示成。
针对并行计算或张量计算编程语言的相关工作在业界还有很多,这里简单列举一些:
-
2009年Indian Institute of Science的论文《Software Pipelined Execution of Stream Programs on GPUs》提出的StreamIt编程模型挖掘通用多核架构(CPU,GPU)上的并行性。它将流式计算描述成一系列由通信管道连接的filter,称为stream graph。这种方式可以描述任务、数据与流水线并行。然后它将filter的调度与处理器分配问题建模成ILP,并通过相应的求解器求解。
-
2010年Stanford等机构的论文《Language virtualization for heterogeneous parallel computing》,2011年论文《A Heterogeneous Parallel Framework for Domain-Specific Languages》和2014年的论文《Delite: A Compiler Architecture for Performance-Oriented Embedded Domain-Specific Languages》中的Delite Compiler Framework and Runtime是一个用于在并行异构硬件(CPU,GPU)上编译与执行DSL应用的端到端系统,可用于机器学习,数据查询,图分析与科学计算领域。它使用的是一种基于Scala语言的embedded DSL,该DSL会被转为IR,在这之上会进行优化最后生成设备上执行的execution graph。2011年论文《OptiML: An Implicitly Parallel Domain-Specific Language for Machine Learning》中的用于机器学习领域的DSL OptiML,即是基于Delite构建的。2012年论文《Diderot: a parallel DSL for image analysis and visualization》中Diderot也是受Delite启发。它可用于图像分析与可视化领域。与Delite不同,其DSL不用Scala作为宿主语言,而是为了该领域设计的。
-
2012年University of Edinburgh和IBM的论文《Compiling a High-Level Language for GPUs: (Via Language Support for Architectures and Compilers)》的Lime是一种面向异构系统的与Java兼容的语言,允许optimizing compiler产生高质量的GPU实现,从而降低使用OpenCL或CUDA开发高性能GPU代码开发的门槛。
-
2013年North Carolina State University的论文《Hidp: A hierarchical data parallel language》中的HiDP是一种机器无关的层次化数据并行语言,其目标是在提升开发效率的同时兼顾性能。相应的HiDP Compiler是一个source-to-source的编译器,它将HiDP编译成CUDA
C++源码。该编译器基于symbolic shape analysis进行kernel fusion,并集成handwritten data-parallel primitives,另外还根据应用的结构探索execution mapping,和通过auto-tuning找合适的dynamic switching points。 -
2013年University of Edinburgh的论文《PARTANS: An Autotuning Framework for Stencil Computation on Multi-GPU Systems》中的PARTANS是用于多GPU的stencil计算auto-tuning框架。它的编程API抽象了多GPU编程的复杂性。
-
2013年NVIDIA的论文《NOVA: A Functional Language for Data Parallelism》是用于多核CPU与GPU的函数语言及编译器。NOVA语言是一种多态的静态类型函数语言。它包含了map, reduce, scan等高阶函数。NOVA compiler对目标平台产生代码,对于CPU产生多线程C代码,针对NVIDIA GPU产生CUDA C代码。与Thrust库及手写CUDA C比较,它在一系列的benchmark上达到相似的性能和相对于处理器核数线性的加速。
-
2015年NVIDIA的论文《Forma: A DSL for Image Processing Applications to Target GPUs and Multi-Core CPUs》中的Forma是一种面向CPU与GPU的DSL,用于图像处理领域。Forma compiler负责内存管理,数据传输,处理边界条件等,将pipeline中的stage进行融合,结合auto-scheduling,最终生成带OpenMP pragmas的C代码。此外,它还可以集成到NumPy/SciPy和OpenCV中。
-
2015年Indian Institute of Science的论文《PolyMage: Automatic Optimization for Image Processing Pipelines》中的PolyMage依赖polyhedral框架,主要面向图像处理流水线应用。它的DSL受Halide启发。这种DSL让开发者以直观的方式表达图像处理中常见的pattern,像point-wise操作,stencil,sampling, histogram和time-iterated methods。DSL会被转成polyhedral表示,并利用polyhedral模型进行优化。基于polyhedral编译技术,其优点可以使能复杂的变换、精确的依赖分析和代码生成。
-
2016年German Research Center for Artificial Intelligence等机构的论文《HIPA cc: A domain-specific language and compiler for image processing》提出用于图像处理的HIPAcc框架。它包含DSL与相应的source-to-source compiler。HIPACC提供了一种嵌入在
C++中的DSL。DSL包含了编译器用于生成高性能并行实现所需的信息。其后端包括CUDA, OpenCL,RenderScript。 -
2018年University of Wisconsin等机构的论文《Design and implementation of DeepDSL: A DSL for deep learning》中的DeepDSL是一种嵌入在Scala语言中的DSL。神经网络用该DSL描述,然后转换成IR,并在IR上做静态分析与一系列优化,最后将之通过codegen生成Java代码。它使用JCuda调用CUDA和cuDNN。
-
2018年NVIDIA的论文《Diesel: DSL for Linear Algebra and Neural Net Computations on GPUs》介绍了用于线性代数与神经网络计算的DSL编译器Diesel。它基于polyhedral编译技术进行跨算子的优化,并生成CUDA kernel。整个过程全自动化。Diesel由三部分组成:1) Frontend解析输入程序,由之生成DAG再转为polyhedral IR。2) Scheduler使用Pluto的调度算法针对目标GPU计算schedule。3) Code generator根据前面产生的schedule生成设备上的函数。
-
2019年Google的论文《TensorFlow Eager: A Multi-Stage, Python-Embedded DSL for Machine Learning》中介绍了TensorFlow Eager。可微分编程的DSL可分为imperative和declarative两类。Declarative DSL将模型的定义与执行分开,即”define-before-run”的模式。它将模型生成dataflow graph,从而让编译器利用并行性做优化,但无法使用任意的host language,因此学习曲线比较陡。早期的TensorFlow即采用这种形式。而PyTorch使用的是imperative的方式。TensorFlow Eager,作为TensorFlow的扩展,是一种可微分编程的Python-embedded DSL,它使开发者可以同时使用imperative与declarative方式,默认为imperative方式。TensorFlow Eager可被看作TensorFlow的multi-stage front-end。它提供了机制来trace Python函数,然后将之变为graph function,最后通过XLA生成目标代码。
-
2019年Technische Universität Dresden的论文《TeIL: A Type-Safe Imperative Tensor Intermediate Language》提出一种称为TeIL的DSL。目的在于解决目前框架中tensor language缺少准确spec的问题。TeIL是一种type-safe的命令式(imperative)的tensor IL。流行的tensor language可以转成它。基于TeIL的precise formal semantics,利用Coq proof assistant可以形式化地证明TeIL核心部分的type-safety。
-
Intel的PlaidML是nGraph软件栈的一部分,用于深度学习中张量计算的编译。它使用Tile DSL来表示张量计算。它让开发者可以快速简单地表示诸如sum over axis,average,matmul,convolution等张量计算。详细可以参考官方文档C++ Tile eDSL。
中间表达(Intermediate Representation)
接下来聊下中间表达(Intermediate representation,IR)。前面提到的计算描述给到编译器后会被转成IR,并在其上进行变换优化。我们知道,表达在许多领域都有着非常重要的,甚至可以说是举足轻重的作用,正如同合适的数据结构之于算法,合适的特征之于机器学习模型。对于编译器来说也是一样。如LLVM具有灵活清晰的架构某种程度上也归功于有一个well-defined的IR设计。LLVM IR既不与高层程序语言强绑定,也不与特定硬件平台相绑定。这样它才能将前后端解耦,使整个系统更好地模块化。IR自然是需要与在它上面做的事相结合来考虑。对于auto-tuning来说,其效果很大程度上取决于tuning的搜索空间。IR就需要能够定义丰富的调度空间,以及容易在这之上做tuning。
深度学习的计算任务的特点是比较结构化,即控制依赖相对较少。数据以张量为主,访问比较有规律。为了优化性能,编译器需要先对数据的使用进行分析,而在传统的编译器中要做这些分析很困难。对于张量计算,已有的IR不太适合或者无法很好地满足需求,因此新的IR被引入进来。可以看到domain-specific的IR的其中一种变化趋势是变得越来越“厚”,即层数越来越多。这些不同层次间的IR之间一般通过progressive lowering可以从高层到低层进行转化。就像接力一样,每一层抽象上处理本层适合干的事,然后将变换后的IR往下层丢。另一方面,它也变得越来越灵活和开放。下面是示意图:
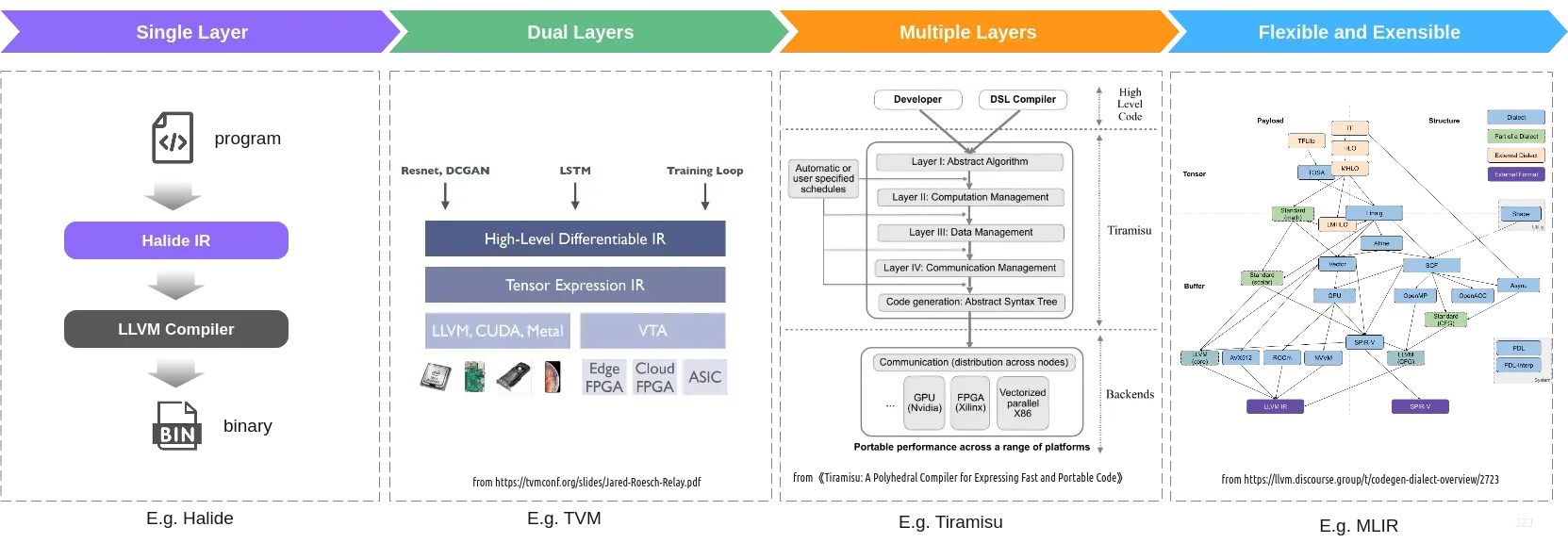
注意这里为了简单,忽略了LLVM IR这种共同的基本的IR。
单层
Halide会将输入的程序先转成Halide IR。由于它最初主要用于图像处理领域,问题的模式相对比较简单,因此核心IR一层也够用了。先来看看Halide对问题的抽象。Halide DSL使用函数式的风格来表示图像处理的流水线。它将图像表示成定义在无限的整数域上的函数(对应Halide::Func)。函数变量(对应Halide::Var)上的函数值即为图像对应坐标上的值(可以是tuple)。图像缓存(Halide::Buffer)对应输入与输出数据的内存。表达式(对应Halide::Expr)用于定义函数,包含算术与逻辑操作,加载数据和调用外部函数等。一个函数可以通过特化产生不同的定义(Definition)。函数定义可以表示初始化或者更新的定义(例子https://halide-lang.org/tutorials/tutorial_lesson_09_update_definitions.html)。一个函数定义对应一个Stage。流水线(Halide::Pipeline)是这些Stage组成的链或有向无环图。StageSchedule与FuncSchedule分别对应Stage与Func的schedule。其IR的具体定义可参见源码Halide/src/IR.h。其中IRNode是最基础的基类,它有BaseExprNode与BaseStmtNode两个继承类,继而分别对应ExprNode与StmtNode两个类。它们分别对应表达式(Expression)和语句(Statement),对应编译原理中的相应概念。表达式表示有类型的值,而语句不表示值。基于IR可以对嵌套循环做变换。IR打印出来大概长这个样子(来自官方例子):
// HL_DEBUG_CODEGEN=1 ./bin/tutorial_lesson_01_basics
let gradient = (void *)_halide_buffer_get_host((halide_buffer_t *)gradient.buffer)
let gradient.type = (uint32)_halide_buffer_get_type((halide_buffer_t *)gradient.buffer)
let gradient.device_dirty = (uint1)_halide_buffer_get_device_dirty((halide_buffer_t *)gradient.buffer)
let gradient.dimensions = _halide_buffer_get_dimensions((halide_buffer_t *)gradient.buffer)
...
produce gradient {
let t2 = 0 - (gradient.min.1*gradient.stride.1)
let t1 = gradient.min.0 + gradient.min.1
for (gradient.s0.y.rebased, 0, gradient.extent.1) {
let t4 = ((gradient.min.1 + gradient.s0.y.rebased)*gradient.stride.1) + t2
let t3 = gradient.s0.y.rebased + t1
for (gradient.s0.x.rebased, 0, gradient.extent.0) {
gradient[gradient.s0.x.rebased + t4] = gradient.s0.x.rebased + t3
}
}
}
}
它相比传统的IR更适合于张量计算,对loop nest的优化更友好。对于IR的优化变换由schedule指定。Schedule决定了计算的执行顺序和在数据如何存放,因此它决定了算法的具体实现。Halide提供了一些调度原语(Scheduling primitive),如split, compute_at, compute_with, fuse, parallel, vectorize, unroll, tile, rfactor, reorder等。它们会影响loop ordering, loop unrolling, blocking / tiling, vectorization, parallelization等。这些影响会作用于IR上,最终影响编译器生成的目标代码。这种模式在后面的很多地方可以看到,比如TVM,TensorComprehensions,Tiramisu, Fireiron等项目。还有类似的做法如2015年的论文《Generating Performance Portable Code Using Rewrite Rules: From High-Level Functional Expressions to High-Performance OpenCL Code》将high-level的函数表达式(由Algorithmic primitives组成)通过一组rewrite rule变换成low-level的函数表达(由OpneCL primitives组成),最终将该low-level表达送到code generator生成OpenCL程序(这部分主要在2017年的论文《LIFT: A functional data-parallel IR for high-performance GPU code generation》中有介绍)。 这些rewrite rule就构成了kernel实现的搜索空间。
这样,对于给定算子写高性能kernel实现其实就转变为构建最优的schedule。问题一定程度上被简化了,但其实最难的那部分问题只是变了种形式存在,即变成如何找最优的schedule。这也是auto-tuning要解决的问题。
双层
神经网络由算子组成。对它的描述自然地可以分为两个层级,上层是计算图的描述,计算图中的节点代表算子。下层是对算子的描述。算子对应tensor program。对应地,IR也可以大体分为两个层次。上层IR一般是图级别的,可以表达整个网络模型的拓扑结构,在其上适合进行图优化等跨算子的优化。下层IR一般是算子级别的,比如描述张量上的计算(matmul, conv等),在其上适合做算子的auto-tuning。
一个例子是Intel的nGraph深度学习编译器。它是由nGraph graph compiler与PlaidML tensor compiler组成的。首先,深度学习模型会转为图级别的IR,即nGraph IR。然后进入PlaidML,其中经由Tile(是一种张量计算DSL,也可以看作PlaidML的高层IR)转为低层次的IR,即Stripe。最后Stripe经过优化编译成目标代码。2019年Intel的论文《Stripe: Tensor Compilation via the Nested Polyhedral Model》对Stripe做了详细的介绍。它是一种polyhedral IR,使用Nested Polyhedral Model来表示张量操作。在Nested Polyhedral Model中,父多面体中的每个点,都定义一个子polyhedron。它可以自然表达tiling, partitioning, tensorization等操作。
另一个例子是TVM。TVM中主要包含两层IR,即高层的图级别IR,与低层算子级别的IR。这些年,这两层IR经历了一些演变。
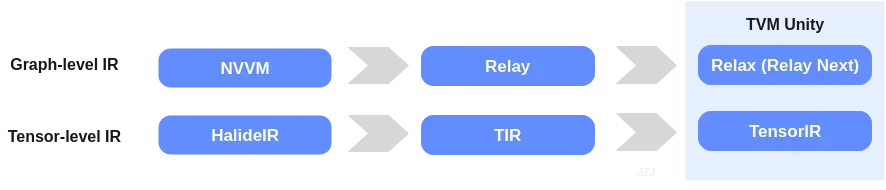
TVM早期受Halide启发较大,早期的低层IR就是用的Halide IR。而与Halide主要处理图像处理不同,TVM主要面向深度学习。对于深度学习来说,它的输入是由算子组成的计算图。因此引入了高层的基于计算图的IR,即NNVM。然后在v0.6上去除了Halide的依赖,低层IR使用TIR。高层IR演进到Relay(详见论文《Relay: A High-Level Compiler for Deep Learning》以及知乎讨论“如何评价TVM的新IR(Relay)?”)。Relay是一种静态类型、函数式IR,对control flow有更好的支持。这种TIR+Relay的组合也是当前的主要方式。当前,社区正在演进的TVM Unity。TVM作者陈天奇在文章新一代深度学习编译技术变革和展望提到目前DL compiler中经典的multi-stage lowering方式的局限性,隔阂往往出现在抽象层的边界上。为了克服该困难,文中提出了TVM Unity。在TVM Unity中IR演进到Relax与TensorIR。与Relay和TIR之间相对独立的风格不同,Relax与TensorIR更加有机地融合在一些,试图解决多层IR带来的隔阂。
Relax(Relay Next),即Relay的下一代,其目的是对于dynamic shape,control flow, in-place update等提供更好的支持,以及统一高层与低层间的抽象,从而使跨层的优化更容易。具体可参见Relax Architecture Overview,Relax – Co-designing High Level Abstraction Towards TVM Unity – TVMCon 2021与如何评价 TVM 在 Relay 之后的新 IR Relax?。当前TVM的做法是Relay这层IR会lower到TE,然后lower到TIR。在TensorIR的RFC [RFC] TensorIR: A schedulable IR for TVM 中介绍了现有做法的局限性,如IR与schedule分离(需要额外的数据结构)。还有一个重要的原因是对于tensorization支持困难。
对于深度学习的计算任务,DSA相比CPU,GPU等其它类型芯片能够提供更好的能效,因此业界这方面的尝试也日益增多。它们普遍提供很多张量计算指令,比如NVIDIA的Tensor Cores的WMMA API或者WMMA PTX指令。带这种张量计算指令的程序为张量化程序。写这种张量化程序一种方法是手写。这种方式虽然容易定制,但不易优化。另一种就是通过DSL+Schedule的方式自动生成,这种方式容易优化,但定制就麻烦一些。TVM对DSA相对于CPU与GPU而言不是非常友好。这么情况下要么采用BYOC(Bring Your Own Codegen)的方式把子图切下来交给厂商的解决方案去处理,要么魔改。TensorIR的主要作用就是对这类张量指令提供更友好的支持。TensorIR是一种Tensorized Program Optimization的抽象,采用了手写算子+Schedule的编程范式。它以TVM IRModule为载体,支持通过TVMScript(基于Python的脚本语言)来编程,也支持从TE导入。TE的表达能力有限,只能表示为Stage = te.compute(lambda expr)这种形式。而相比而言,TensorIR更加灵活。另外,它不再依赖额外的schedule tree等数据结构,使schedule操作直接使用于IR,从而支持交互式的调度。具体可以参考Understanding TensorIR: An Abstraction for Tensorized Program Optimization。
为了对这种张量计算提供更好的支持,业界在IR层面上还有其它的一些尝试。如:
- 2019年Harvard University的《Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations》中的Triton是以tile(静态多维子数组)为核心的语言和相应的编译器,用于构建矩阵相乘等算子的实现。像矩阵相乘这样的计算一种做法是利用micro-kernels(手工实现的tile-level的intrinsic)的做法,但现有编译器缺乏相关的支持。该语言分两部分:Triton-C是一种类似C的表达张量程序的语言。Triton-IR是一种基于LLVM IR,适合tile-level程序分析、变换和优化的表示。Triton-IR可由Triton-C解析而来。然后Triton-IR给到Triton-JIT结合auto-tuning进行优化并编译产生机器码。该编译器中提供了一系列tile-level的优化用于编译GPU平台的代码。
- 2020年University of Münster等机构的《Fireiron: A Scheduling Language for High-Performance Linear Algebra on GPUs》中的Fireiron是一种data-movement-aware的调度语言,它将计算与数据搬运都作为一等公民(即可以使用同样的调度原语)。而其它的一些基于schedule的编译器大多没有将数据搬运作为一等公民,导致数据搬运的schedule需要修改算法定义才能完成。Firerion的调度语言提供了高层次抽象,将计算逐步分解至汇编指令,加速单元原语,或者预定义的micro-kernel。通过添加相关的spec(一种描述计算的数据结构),Fireiron可以支持通过WMMA-API和HMMA使用Tensor Cores。
多层
2018年论文《Tiramisu: A Polyhedral Compiler for Expressing Fast and Portable Code》提出的Tiramisu是一个用于图像处理,线性代数和深度学习领域的,基于多面体编译技术的DSL compiler。它用于产生多平台(多核 ,GPU,分布式机器)的高性能代码。正像它的名字一样,其特点之一是IR分成了四层,这四层抽象将algorithm,loop transformation,data layout与communication间分离。第一层描述算法,也可以视作DSL;第二层管计算(计算顺序与处理器分配);第三层管数据存放;第四层管通信与同步。这样的分离使得用同样的算法面向多个硬件架构时更简单。这已经有将IR多层抽象,各司其职的意思了。
还有一种添加IR层的情况其目的是为了能够利用一些现有技术。典型的比如多面体编译(Polyhedral compilation)技术。多面体编译是个理论性非常强的方向,这里不展开。大体来说, 它将循环嵌套中的迭代空间通过多面体进行建模,然后通过整数规划等数学方法,以最优化并行度和局部性为目标,在满足数据依赖的前提下对循环嵌套进行变换。从表达能力上来说,像Halide与TVM中对迭代空间主要使用区间(Interval)建模,并使用区间分析技术。而多面体模型中采用多面体进行建模,可以考虑仿射变换。这意味着前者只能表达axis-aligned bounding regions的迭代区域空间(而非general polytope)。可以考虑的范围更大,但其代价是分析更为复杂。
谈到多面体编译绕不开一个开源库 – isl(Integer Set Library)。多面体编译器很多都基于或用到它,如Tiramisu,TensorComprehensions,AKG,Polly,Diesel等等。它主要包含一些集合与关系上的操作,以及ILP(Integer Linear Programming) solver。但是,它里边自成一体,有自己的一套IR(暂称为Polyhedral IR)。考虑到schedule在逻辑上是树的结构,因此它干脆使用一种显式的树型结构表示schedule,称为schedule tree。它表示语句实例的取值范围和执行顺序等信息。树中的节点对应partial schedule,子节点的顺序确定执行顺序。2014年的论文《Schedule Trees》比较详细地介绍了schedule的这种树型表示方式。这也意味着要利用该库中多面体编译优化的能力,需要转换成这种polyhedral IR。相关的例子比如有TensorComprehensions和AKG,它们都是基于多面体技术的编译器。TensorComprehensions采用了Halide IR以避免一些重复工作。输入的DSL会转成Halide IR。然后在做多面体编译优化时,Halide IR会转成Polyhedral表示(构建schedule tree)。这样便可以在这之上利用多面体编译技术优化循环结构。AKG (Auto Kernel Generator)是一个基于多面体编译技术的深度学习算子的编译器。详细可参见2021年的论文《AKG: Automatic Kernel Generation for Neural Processing Units Using Polyhedral Transformations》以及官方文档。项目基于TVM,编译过程中会转成polyhedral表达,然后利用多面体编译技术进行自动调度。
可扩展
MLIR系统化了这种多层IR的思想。其创建者是编译器大神,也是LLVM的作者Chris Lattner。以往不同的前端语言会在LLVM IR之上再构建自己的IR,而MLIR试图将它们纳入到统一的框架中。codegen dialect overview 它使得IR层次更加灵活,并且更开放和易于扩展。论文《MLIR: A Compiler Infrastructure for the End of Moore’s Law》和《Composable and Modular Code Generation in MLIR: A Structured and Retargetable Approach to Tensor Compiler Construction》对它有比较详细的介绍。在深度学习编译器领域,MLIR可能是一个比较特殊的存在。它刚出来时,大家容易将它与现有的一些深度学习编译器对比,或者抱着使用一个机器学习编译器的心态去了解和使用它,却发现好像和期望的有些不一样。tvm or mlir ?中有对两者作过讨论。与像TVM这样的项目不同,MLIR本身不是一个端到端的解决方案,而是作为编译器的软件底座帮助构建解决方案。也就是说,它本身不解决具体的特定业务问题,而是提供了软件底座、组件和工具等。
那MLIR解决什么问题,或者说有什么作用呢?不同的问题适合在不同的抽象层次进行建模,编译器中的不同优化也适合在不同层次的抽象上进行。这种情况下,在单一的IR表示的抽象层上做全部的变换与优化就不太合适。MLIR全称Multi-Level Intermediate Representation,听名字就知道它的特点是IR是多层的。MLIR使得引入新的抽象层次变得更加方便。这种抽象具化成操作、属性和类型等。这些构件中相关的部分组成方言(Dialect)。方言是MLIR中很重要的概念。这名字起得很贴切,现实当中不同的方言是能够混在一起交流的,同时某种意义上也是能相互转换的。类似地,MLIR允许创建新的dialect,并转换到已有dialect,多种dialect也可以放在一起使用。MLIR试图解决软件的碎片化问题,使各编译器间的软件尽可能重用,从而减少构建领域专用编译器的成本。以往大多数编译器的做法是自成一体。要重用得整个拿来魔改。如果想用其中的一些组件很困难,基本就得重写。MLIR提供了标准化的基于SSA的IR数据结构,用于定义dialect, operation, pattern rewrite等IR元素的声明式系统,以及调试打印、pass管理、文档等通用的一系列基础设施。当大家使用相同的软件基础设施,那自然就有利于软件重用,避免重复造轮子。另一个好处是它已是LLVM项目的一部分,因此与LLVM的兼容性非常好。
结语
这一篇主要讨论了与深度学习编译器密切相关的概念,如DLS,IR,为下一篇更进一步讨论auto-tuning技术做一些准备。
文章出处登录后可见!