SVC vs SVR
sklearn SVM中有:
sklearn.svm.SVC()
sklearn.svm.SVR()
一般来讲
support vector classify(SVC)支持分类机做二分类的,找出分类面,解决分类问题,我所追求的是把样本分成二类或者多类样本点的“最开”, 是要使到超平面最近的样本点的“距离”最大;找区分两类的超平面(hyper plane),使边际(margin)最大。如做cancer分类,做得病于不得病的分类。多说一句因为本人是做医学数据的,经常用到SVC来做分类。
详细可阅读:Search — scikit-learn 1.1.0 documentation
support vector regression(SVR)支持回归机做曲线拟合、函数回归 , 它的目的是使所有的样本点离着超平面的总偏差最小,SVR则是要使到超平面最远的样本点的“距离”最小。。可以做预测,温度,天气,股票
详细可阅读:
Support Vector Regression (SVR) using linear and non-linear kernels — scikit-learn 1.1.0 documentation
原理出发:我们看图直白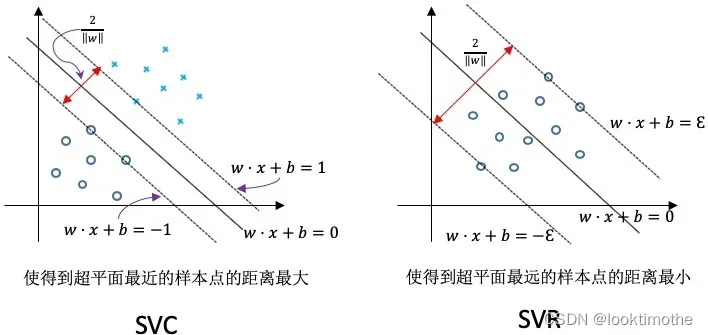
优点:训练好的模型的算法复杂度是有支持向量(Support Vectors)的个数决定的而不是有数据的维度决定的。所有这样一来,SVM不太容易产生overfitting。训练集里面所有的费支持向量的点都被去重,重复训练的过程,结果还是会得到一样的模型。但是如果训练的支持向量的个数比较小,那么训练出的模型比较容易泛化。
Ps:什么是机器学习中的泛化? 其实可以根据泛化能力强弱可以分为四种:
欠拟合:模型过于简单,不能在训练集上获得足够低的误差;
拟合: 测试误差与训练误差差距较小;
过拟合:过分关注训练集细节,在训练集上表现良好,但不能泛化到新数据上;
不收敛:模型不是根据训练集训练得到的。
后来有了核函数,使得
sklearn SVM中有:sklearn.svm.SVC()sklearn.svm.SVR()
应用面就更加神通广大了。通过构造核函数使得运算结果等同于非线性映射,同时运算量要远远小于非线性映射。
文章出处登录后可见!