01 分组与聚合的原理
在Pandas中,分组是指使用特定的条件将原数据划分为多个组,聚合在这里指的是,对每个分组中的数据执行某些操作,最后将计算的结果进行整合。
分组与聚合的过程大概分为以下三步:
拆分→应用→合并
分组与聚合的原理:
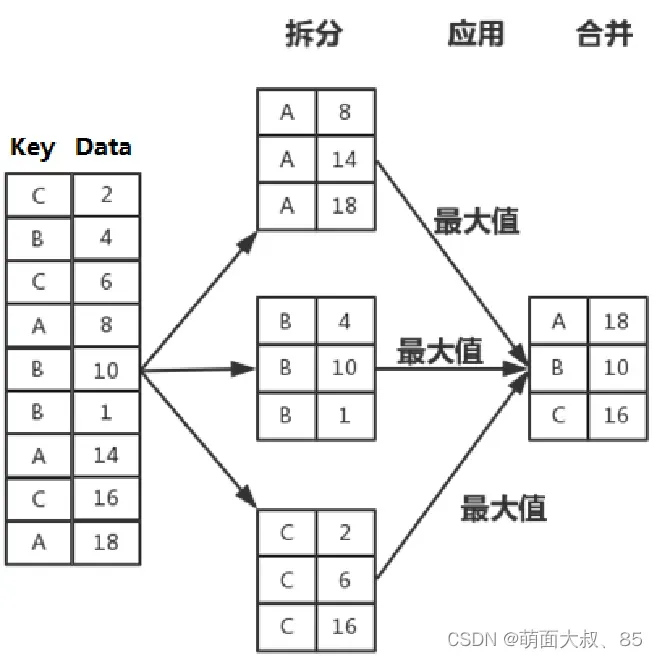
在Pandas中,可以通过groupby()方法将数据集按照某些标准划分成若干个组。
groupby(by=None, axis=0, level=None, as_index=True, sort=True,group_keys=True, squeeze=False, observed=False, **kwargs)
by:用于确定进行分组的依据。
axis:表示分组轴的方向。
sort:表示是否对分组标签进行排序,接收布尔值,默认为True。

03 数据聚合
df=pd.DataFrame({'货号':['a','b','a','b','a'],
'平台':['淘宝','京东','京东','淘宝','淘宝'],
'销量':[1,2,3,4,5]})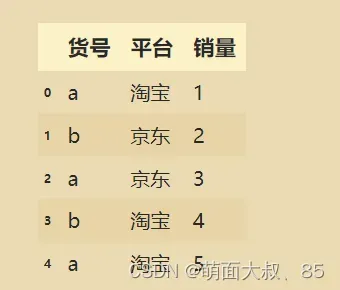
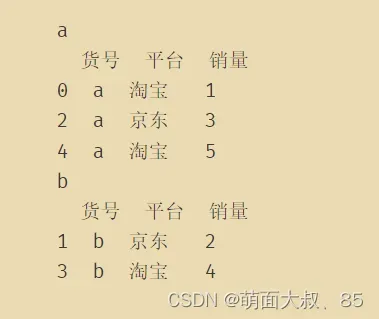
以货号进行分组 得到的gb是一个对象 我们可以便利他
gb=df.groupby('货号') for i,j in gb: print(i) print(j)

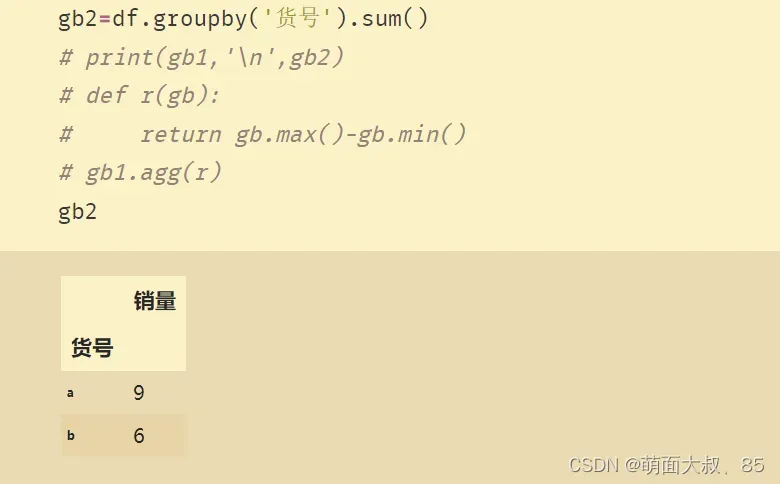
前面介绍过的Pandas统计方法,比如用于获取最大值和最小值的max()和mix(),这些方法常用于简单地聚合分组中的数据。
# 按货号进行分组,求每个分组的平均值
df.groupby(‘key1’).sum()gb2=df.groupby(‘货号’).max()
如果内置方法无法满足聚合要求时,则可以自定义函数,将它作为参数传给agg()方法,实现Pandas对象的聚合运算。
agg(func,axis = 0,* args,** kwargs
func:表示用于汇总数据的函数,可以为单个函数或函数列表。
axis:表示函数作用于轴的方向,0或index表示将函数应用到每一列;1或columns表示将函数应用到每一行,该参数的默认值为0。
def r(gb):
return gb.max()-gb.min()
gb1.agg(r)
货号
a 4
b 2
Name: 销量, dtype: int64对某列数据应用不同的函数
可以将两个函数的名称放在列表中,之后在调用agg()方法进行聚合时作为参数传入即可,
# 对一列数据用两种函数聚合
data_group.agg([range_data_group, sum])
gb=df.groupby('货号')
def r(gb):
return gb.max()-gb.min()
gb.agg([r,sum,min,max])

数据应用 apply
apply()方法的使用是十分灵活的,它可以在许多标准用例中替代聚合和转换,另外还可以处理一些比较特殊的用例。
apply(func, axis=0, broadcast=None, raw=False, reduce=None,result_type=None, args=(), **kwds)
根据身高体重算出bmi值 这里用到了apply函数
def bmi(a):
weigh=a['体重(kg)']
height=a['身高(cm)']/100
bmi=weigh/height**2
return bmi
data['体制指数2']=data.apply(bmi,axis=1)
data
df.apply(lambda x:x.max()-x.min(),axis=1)
本章主要针对Pandas的分组聚合和其它组内运算进行了介绍,包括分组与聚合的原理、分组操作、聚合操作,以及其它分组级的相关操作,最后介绍了一个分析运动员基本信息的案例,真实地演示如何运用这些知识。
大家在学习与理解的同时,要多加练习,可根据具体情况选择合理的技术进行运用即可。
文章出处登录后可见!