目录
1、原理
邻近算法,或者说K最近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
接下来对KNN算法的思想:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率;
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
2、数据集
有两个目录,其中目录trainingDigits中包含了1934个例子,命名规则如 9_45.txt,表示该文件的分类是9,是数字9的第45个实例,每个数字大概有200个实例。testDigits目录中包含946个例子。使用trainingDigits中的数据作为训练集,使用testDigits中的数据作为测试集测试分类的效果。两组数据没有重叠。(数据集和代码可在我的上传资源里面下载,免费)

3、代码以及注释
1. 数据准备:
数字图像文本向量化,这里将32×32的二进制图像文本矩阵转换成1×1024的向量。循环读出文件的前32行,存储在向量中。
2. 构建训练数据集:
利用目录trainingDigits中的文本数据构建训练集向量,以及对应的分类向量
3. 测试集数据测试:
通过测试testDigits目录下的样本,来计算算法的准确率。
from numpy import *
import operator
import time
import os
# 调用KNN算法
# 参数:(inputPoint :vectorUnderTest 测试文本向量化 32x32 -> 1x1024)
# 参数:(dataSet :trainingMat 训练集文本向量化 32x32 -> 1x1024)
# 参数:(labels :hwLabels 训练集文本中解析分类数字 )
# 参数:(k :3)
def classify(inputPoint, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # 已知分类的训练集的行数
# 先tile函数将输入点拓展成与训练集相同维数的矩阵,再计算欧氏距离
diffMat = tile(inputPoint,(dataSetSize,1))-dataSet # 样本与训练集的差值矩阵
sqDiffMat = diffMat ** 2 # 差值矩阵平方
sqDistances = sqDiffMat.sum(axis=1) # 计算每一行上元素的和
distances = sqDistances ** 0.5 # 开方得到欧拉距离矩阵
sortedDistIndicies = distances.argsort() # 按distances中元素进行升序排序后得到的对应下标的列表
classCount = {} # 选择距离最小的k个点
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0)+1
# 按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 1. 数据准备:数字图像文本向量化,这里将32x32的二进制图像文本矩阵转换成1x1024的向量。循环读出文件的前32行,存储在向量中。
# 文本向量化 32x32 -> 1x1024
def img2vector(filename):
returnVect = []
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect.append(int(lineStr[j]))
return returnVect
# 2. 构建训练数据集:利用目录trainingDigits中的文本数据构建训练集向量,以及对应的分类向量
# 从文件名中解析分类数字
def classnumCut(fileName):
fileStr = fileName.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
return classNumStr
# 构建训练集数据向量,及对应分类标签向量
def trainingDataSet():
hwLabels = []
trainingFileList = os.listdir("trainingDigits") # 获取目录内容
m = len(trainingFileList)
trainingMat = zeros((m, 1024)) # m维向量的训练集
for i in range(m):
fileNameStr = trainingFileList[i] # 找到一个样本文件
hwLabels.append(classnumCut(fileNameStr)) # 将文件传入classnumCut函数,从文件名中解析分类数字
trainingMat[i, :] = img2vector('trainingDigits/%s' % fileNameStr) # 将文件传入img2vector函数中,这里将32x32的二进制图像文本矩阵转换成1x1024的向量
return hwLabels, trainingMat # 返回两个文件
# 3. 测试集数据测试:通过测试testDigits目录下的样本,来计算算法的准确率。
# 测试函数
def handwritingTest():
hwLabels, trainingMat = trainingDataSet() # 构建训练集
testFileList = os.listdir('testDigits') # 获取测试集
errorCount = 0.0 # 错误数
mTest = len(testFileList) # 测试集总样本数
t1 = time.time()
for i in range(mTest):
fileNameStr = testFileList[i] #找到一个测试文件
classNumStr = classnumCut(fileNameStr) # 将文件传入classnumCut函数,从文件名中解析分类数字
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr) # 将文件传入img2vector函数,将32x32的二进制图像文本矩阵转换成1x1024的向量
classifier_result = classify(vectorUnderTest, trainingMat, hwLabels, 3) # 调用 KNN 算法进行测试
print("classifier_result: %d, the real answer is: %d\n" % (classifier_result, classNumStr))
if classifier_result != classNumStr:
errorCount += 1.0
print("the total number of tests is: %d" % mTest) # 输出测试总样本数
print("the total number of errors is: %d" % errorCount) # 输出测试错误样本数
print("the total error rate is: %f" % (errorCount/float(mTest))) # 输出错误率
t2 = time.time()
print("Cost time: %.2fmin, %.4fs."%((t2-t1)//60, (t2-t1)% 60)) # 测试耗时
if __name__ == "__main__":
handwritingTest()有些库函数需要自己安装一下,很简单,不懂可以问我
4、运行结果
大家可以删一部分测试集,这样更直观
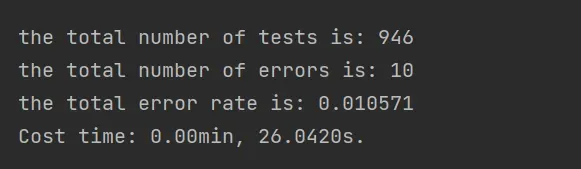
5、总结
KNN,搜寻最近的K个已知类别样本用于未知类别样本的预测。”最近”的度量就是应用点之间的距离或相似性,距离越小或相似度越高,说明他们之间越近“预测”,对于离散型的因变量来说,从k个最近的已知类别样本中挑选出频率最好的类别用于未知样本的判断;对于连续性的因变量来说,则是将K个最近的已知样本均值用作未知样本的预测。
6、致谢

参考一下博主的文章,由衷的感谢!!附上链接
数据包:(135条消息) 数字识别机器学习免费打开就可以跑-机器学习文档类资源-CSDN文库
原文链接:Python 手写数字识别-knn算法应用 – bbking – 博客园 (cnblogs.com)
原文链接:https://blog.csdn.net/springhammer/article/details/8951104
原文链接:https://blog.csdn.net/Mind_programmonkey/article/details/89182485
文章出处登录后可见!