本文主要从三个方面做总结:
- 数据的结构化与非结构化
- 数据的定量与定性
- 数据的4个等级
1、结构化与非结构化
我们在拿到一个新的数据集时,首先要做判断,这个数据集是结构化还是非结构化的。
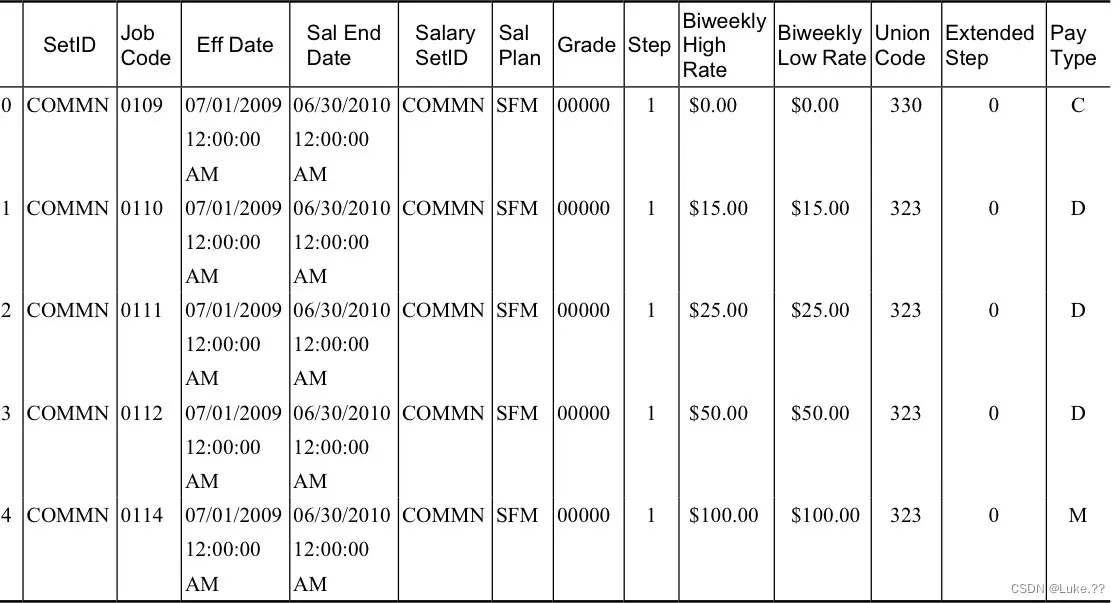
- 结构化(有组织)数据:可以分成观察值和特征的数据,一般以表格的形式组织。
- 非结构化(无组织)数据:作为自由流动的实体,不遵循标准组织结构。按照我的理解,通常就是一团数据,或只有一个特征。
这个部分在我日常的工作中还是比较少碰到的,笔者也没有过多的深究,举两个例子带过吧。
非结构化数据示例:

结构化数据示例:
2、定量与定性
- 定量数据:本质上是数值,衡量某样东西的数量。
- 定性数据:本质上是类别,应该是描述某样东西的性质。
本文选取了2022招行Fintech竞赛部分数据(因为竞赛要求,不能使用原始数据,所以笔者截取了一部分数据当做案例分析)。
#我们先导入一些特征工程常用的包:
import pandas as pd
import numpy as np
import matplotlib as plt
import seaborn as sns导入数据集:
tag = pd.read_csv('F:\\招行fintech\\test_A榜.csv')让我们先来查看一下数据集:
tag.head()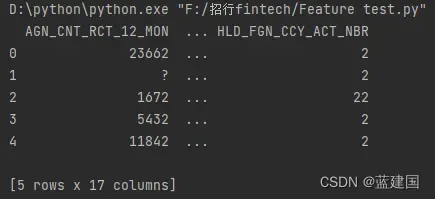
head会省略掉一些行,我们可以利用下面的指令,继续查看:
tag.info()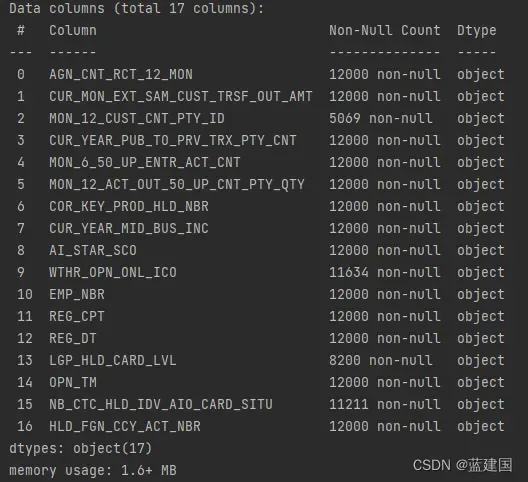
一般情况下,我们通常会首先选用这两个指令来查看数据集,不论是查看缺失数量亦或是判断特征类型都是简单明了。下面我直接给出数据集部分数据来做说明。
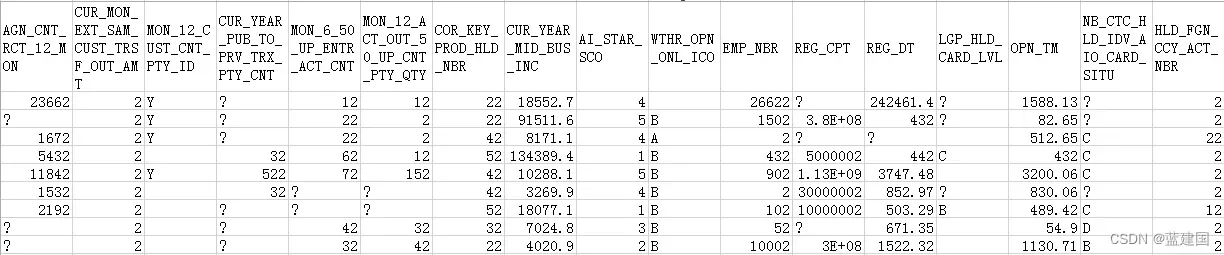
可以明显的看出, MON_12_CUST_CNT_PTY_ID、WTHR_OPN_ONL_ICO、LGP_HLD_CARD_LVL以及NB_CTC_HLD_IDV_AIO_CARD_SITU均为定性数据,AI_STAR_SCO列我们目前还无法做出判断,暂且归为定量数据。通过下一节说明我们再来讨论。
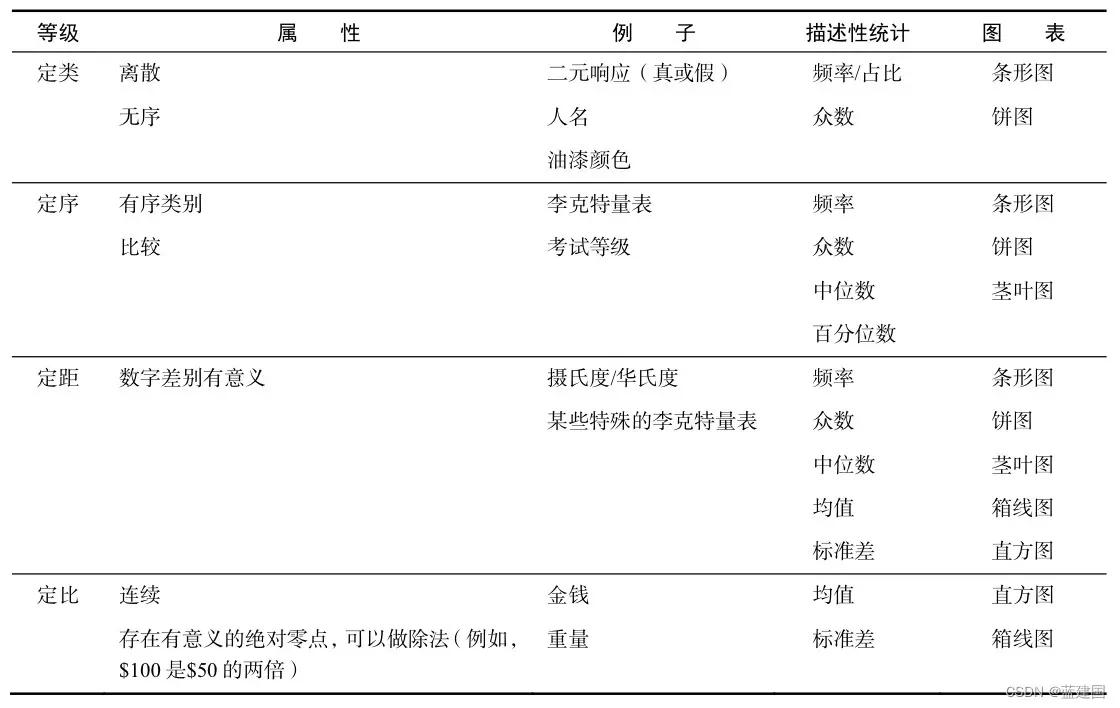
3、数据的4个等级
上文我们已经将数据分为定性和定量,其实如果再细分下去还是可以的。数据的4个等级:
- 定类等级(nominal level)
- 定序等级(ordinal level)
- 定距等级(interval level)
- 定比等级(ratio level)
每个等级都有不同的控制和数学操作等级。了解数据的等级十分重要,因为它决定了可以执行的可视化类型和操作。
3.1、定类等级
对于每个等级,我们都会简要介绍可以执行的数学操作,以及不可执行的数学操作。在这个等级上,不能执行任何定量数学操作,例如加法或除法,这些数学操作没有意义,当然了,也就没有平均值这一说。
就比如上述数据中的NB_CTC_HLD_IDV_AIO_CARD_SITU列数据:
tag['NB_CTC_HLD_IDV_AIO_CARD_SITU'].value_counts().head() 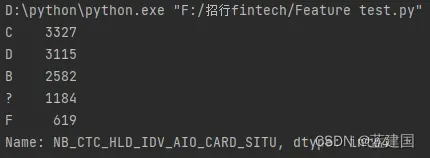
出现最多的等级为C,意味着这个种类是众数,即最多的类别。我们可以将其绘制图表(如条形图):
tag['NB_CTC_HLD_IDV_AIO_CARD_SITU'].value_counts().sort_values(ascending=False).head(20).plot(kind='bar')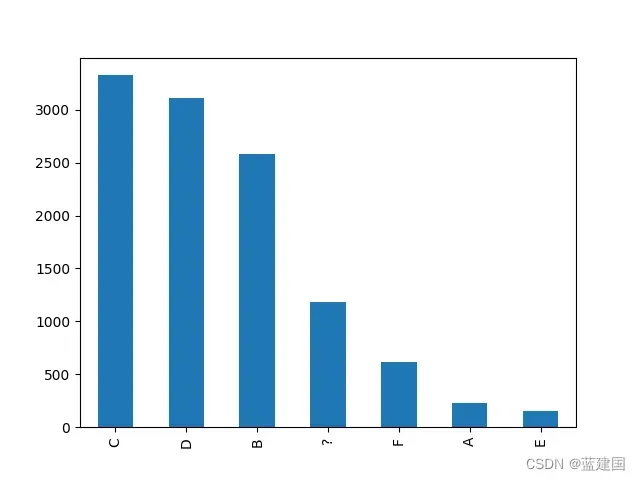
当然,我们也可以绘制饼图:
tag['NB_CTC_HLD_IDV_AIO_CARD_SITU'].value_counts().sort_values(ascending=False).head(5).plot(kind='pie')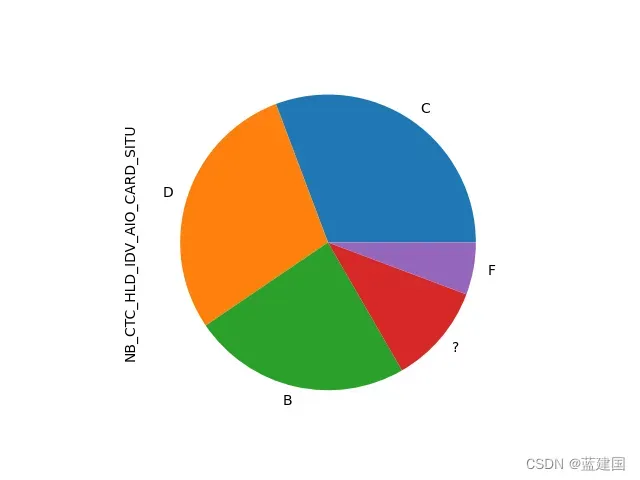
3.2、定序等级
定类等级为我们提供了很多进一步探索的方法。再向上一级就到了定序等级,定序等级继承了定类等级的所有属性,而且有重要的附加属性:
- 定序等级的数据可以自然排序。
- 可以认为列中的某些数据比其他数据更好或更大。
就比如:
- 使用李克特量表(比如1~10的评分)。
- 考试的成绩(F、D、C、B、A)
我们可以将上述数据中的AI_STAR_SCO来做示例:
tag['AI_STAR_SCO'].describe()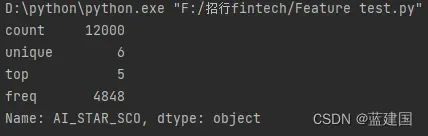
如上所示定序数据的格式是正确的,可以进行可视化:
tag['AI_STAR_SCO'].value_counts().plot(kind='pie') 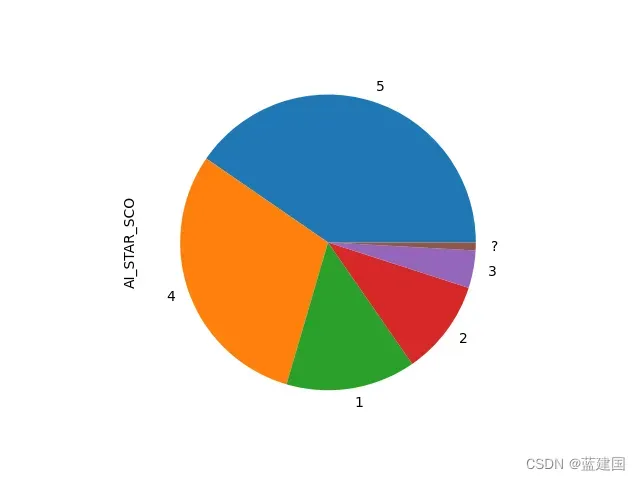
如定类等级一样,我们也可以用条形图:
tag['AI_STAR_SCO'].value_counts().plot(kind='bar') 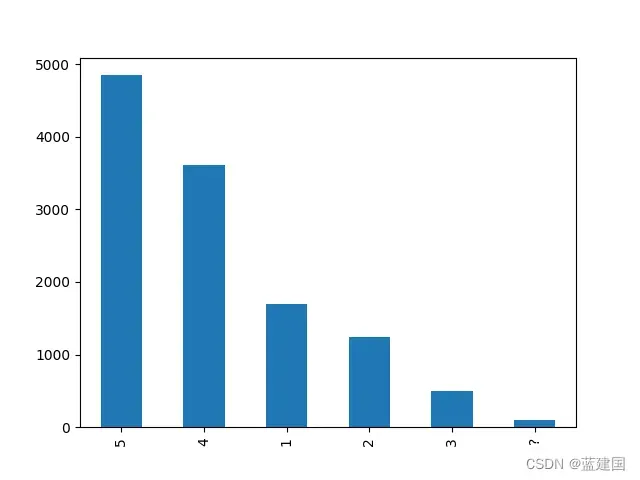
此外,在定序等级中我们还可以引入箱形图:
tag['AI_STAR_SCO'].value_counts().plot(kind='box') 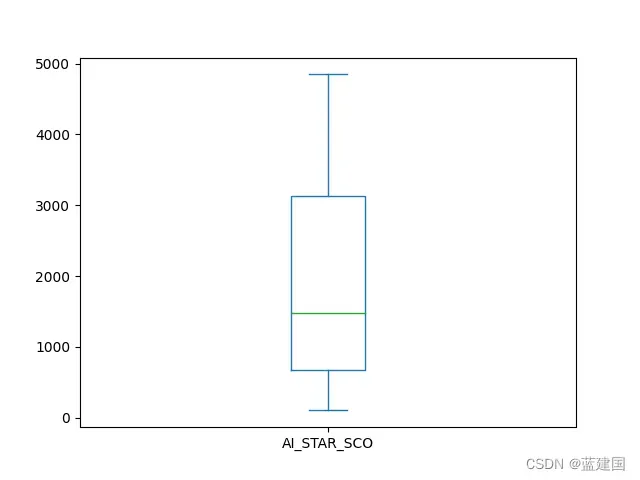
3.3、定距等级
好了,在上述的数据处理中,我们一直针对的是定型数据,接下来我们可以再进一步,在定距等级中,我们开始研究定量数据。在定距等级中,数值数据不仅可以像定序等级的数据一样排序,而且值之间的差异也有意义。这就说明,在定距等级里,我们不仅仅可以对值进行排序和比较,同时还可以对其进行加减操作。
比较经典的例子便是温度。在数据工作里,我们一般喜欢把连续的温度统计成温度区间来比较。下面我引用《特征工程入门与实践》中的图片来做说明:

这个数据集每行代表某个城市某月的平均温度,我们关注的便是AverageTemperature(平均温度)列。温度数据属于定距等级,这里就不能使用条形图或者饼图进行可视化,因为值太多了。
我们将温度数据进行分桶操作:
tag['AverageTemperature'].hist() 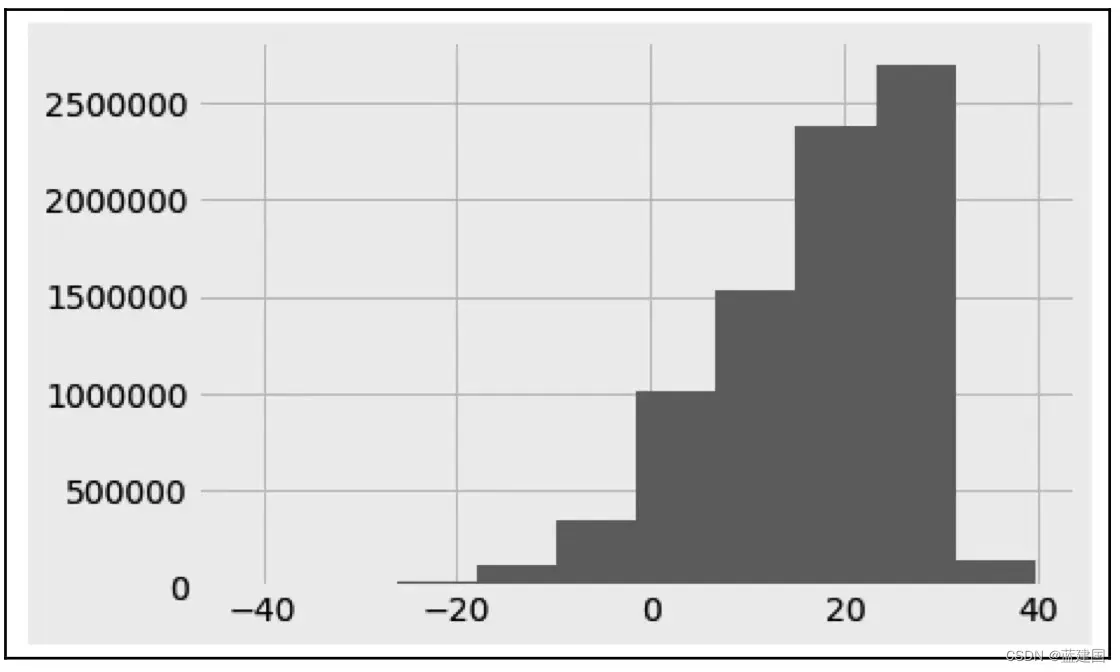
3.4、定比等级
最终我们来到了最高等级:定比等级。和定距等级一样,我们在定比等级上处理的也是定量数据。这里不仅继承了定距等级的加减运算,而且有一个绝对零点的概念,可以做乘除运算。
我们举一个典型的例子:
当我们处理金融数据时候,必须要计算一些货币的值,货币处于定比等级,因为其“零资金”这个概念是存在的。那我们可以这样说:
- ¥100是¥50的两倍
- 10mg青霉素是20mg青霉素的一半
如此说来,我们就可以理解为什么温度不可以作为等比等级数据了,因为100℃比50℃高两倍这种说法没有意义,并不合理,并不客观。
总结:
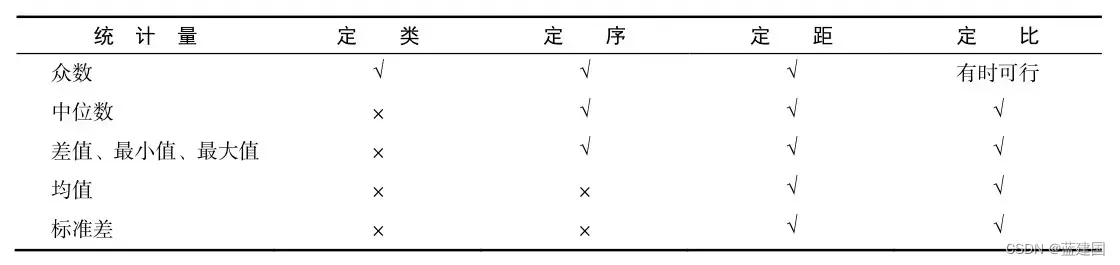
最后,我给出关于四个等级的总结:

文章出处登录后可见!