LightGCN
最近在学一些关于推荐的算法,以此系列博客作为学习过程中的简单记录。
同时希望找到有相同兴趣的小伙伴一起交流交流学习资源~
1 Background
在节点分类任务中,每个节点通常有多个属性信息。此时,非线性激活函数在理论上来说能够基于输入的属性捕捉到高维的特征信息。但在协同过滤中,由于节点的输入只有一个ID信息,使用非线性激活函数是否能够带来增益是有待观察的。此外,基于节点ID信息做线性特征转换是否work,也是一个值得探讨的问题。
LightGCN的作者以nueral grpah collaborate filtering(NGCF)算法为研究对象,就上述两个问题做了探讨。
首先在控制其他参数不变的情况下,设计了下列三种NGCF:
- NGCF-n:移除了非线性激活函数;
- NGCF-f:移除了线性特征值转换
;
- NGCF-fn:同时移除了非线性激活函数和线性特征转换
下图为对比各个版本的NGCF训练损失及Recall变化情况
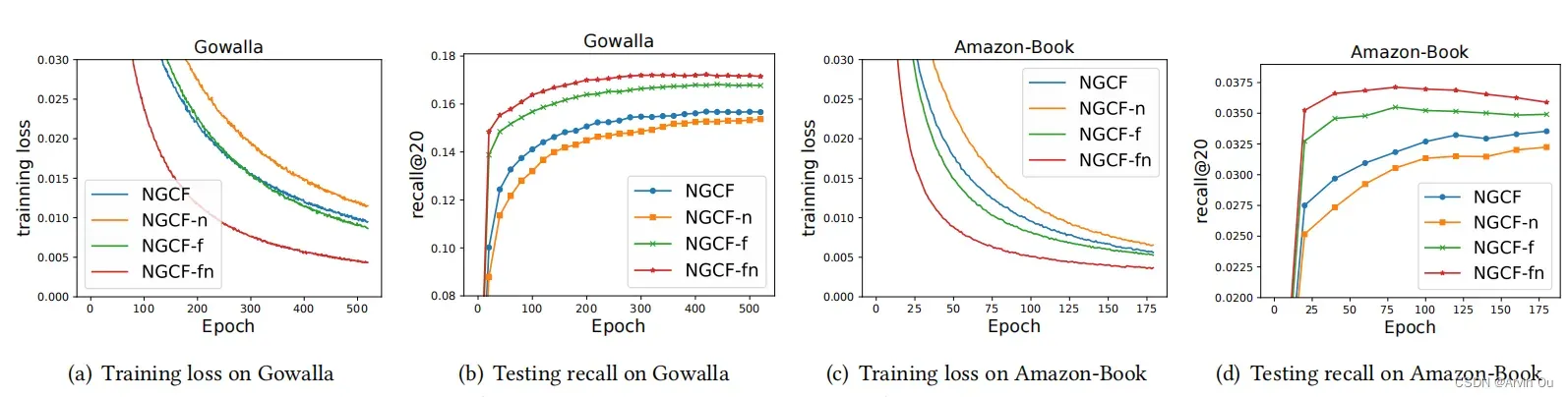
a. 去除非线性激活函数对于的NGCF性能增益是负的;
b. 去除线性特征转换对于NGCF的性能增益是正的;
c. 同时去除非线性激活函数和线性特征转换能够带来最大的性能增益。
2 Method
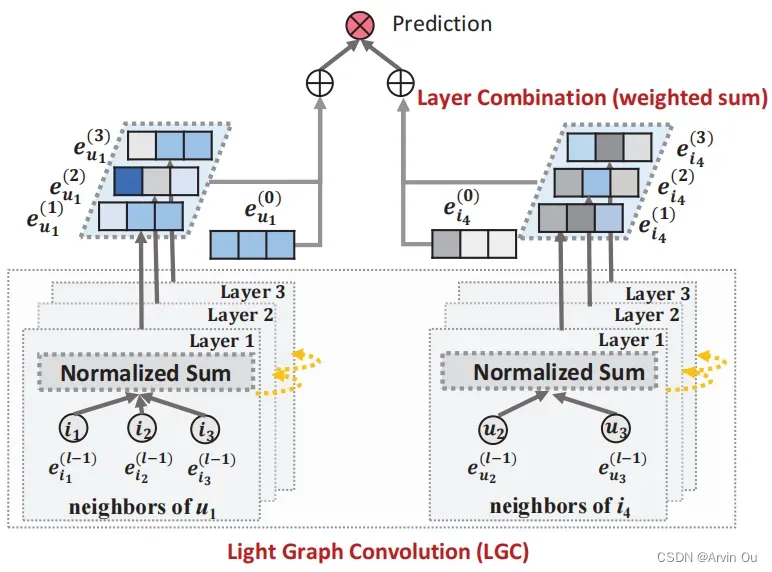
受实验结果的启发,LightGCN在设计时没有考虑非线性激活和特征线性转换,整体框如下:
计算过程为:
首先定义网络的邻接矩阵:
其中,,
和
分别为user和item的数量。
在取消非线性激活和特征转换的情况下,信息传播机制定义如下:
最终,将每一层的Embedding加权求和得到最终的Embedding来做预测
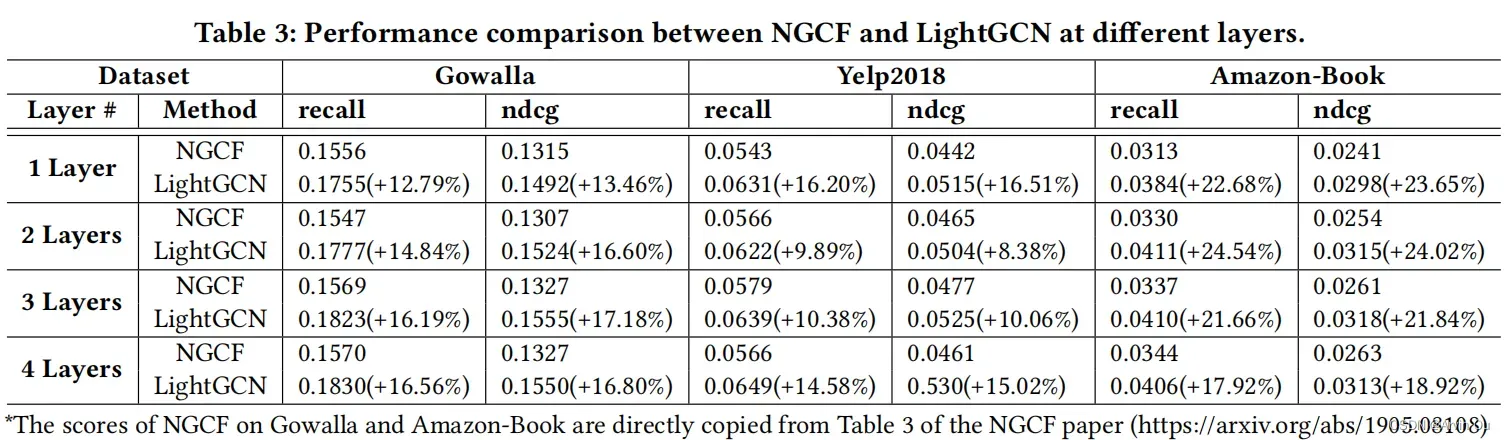
3 效果如何
首先来看看层数不同情况下LightGCN和NGCF算法的性能对比:
4 Codes
4.1 LightGCN模型的代码
在前文我们已经讲到,LightGCN不考虑非线性激活和线性特征转换,那么LightGCN要优化的是什么呢?
看完下面这个代码块,我们就能得到答案~
class LightGCN(BasicModel):
def __init__(self,
config:dict,
dataset:BasicDataset):
super(LightGCN, self).__init__()
self.config = config
self.dataset : dataloader.BasicDataset = dataset
self.__init_weight()
def __init_weight(self):
# 获取定义好的参数
self.num_users = self.dataset.n_users
self.num_items = self.dataset.m_items
self.latent_dim = self.config['latent_dim_rec']
self.n_layers = self.config['lightGCN_n_layers']
self.keep_prob = self.config['keep_prob']
self.A_split = self.config['A_split']
# 初始化每个user和item的Embedding,也是训练过程中调整的对象
self.embedding_user = torch.nn.Embedding(
num_embeddings=self.num_users, embedding_dim=self.latent_dim)
self.embedding_item = torch.nn.Embedding(
num_embeddings=self.num_items, embedding_dim=self.latent_dim)
# pretrain
if self.config['pretrain'] == 0:
# 如果不是pretrain,那就用标准正太分布进行初始化
nn.init.normal_(self.embedding_user.weight, std=0.1)
nn.init.normal_(self.embedding_item.weight, std=0.1)
world.cprint('use NORMAL distribution initilizer')
else:
self.embedding_user.weight.data.copy_(torch.from_numpy(self.config['user_emb']))
self.embedding_item.weight.data.copy_(torch.from_numpy(self.config['item_emb']))
print('use pretarined data')
self.f = nn.Sigmoid()
# 加载邻接矩阵
self.Graph = self.dataset.getSparseGraph()
print(f"lgn is already to go(dropout:{self.config['dropout']})")
从上面一块代码可以看出,LightGCN训练的是初始化的Embedding。
现在了解了训练的对象,我们再来看看LightGCN的前向传播过程
def computer(self):
"""
LightGCN的前向传播过程
"""
users_emb = self.embedding_user.weight
items_emb = self.embedding_item.weight
# 将user和item的embedding拼接在一起
all_emb = torch.cat([users_emb, items_emb])
embs = [all_emb]
if self.config['dropout']:
if self.training:
print("droping")
g_droped = self.__dropout(self.keep_prob)
else:
g_droped = self.Graph
else:
g_droped = self.Graph
for layer in range(self.n_layers): # 计算每一层的embedding
if self.A_split:
temp_emb = []
for f in range(len(g_droped)):
temp_emb.append(torch.sparse.mm(g_droped[f], all_emb))
side_emb = torch.cat(temp_emb, dim=0)
all_emb = side_emb
else:
all_emb = torch.sparse.mm(g_droped, all_emb) # A * E
embs.append(all_emb)
embs = torch.stack(embs, dim=1)
#print(embs.size())
light_out = torch.mean(embs, dim=1) # 取多层embedding的均值作为输出
users, items = torch.split(light_out, [self.num_users, self.num_items])
return users, items
def forward(self, users, items):
# compute embedding
all_users, all_items = self.computer()
# print('forward')
#all_users, all_items = self.computer()
users_emb = all_users[users]
items_emb = all_items[items]
inner_pro = torch.mul(users_emb, items_emb)
gamma = torch.sum(inner_pro, dim=1)
return gamma
上面的代码中,我们可以知道,最后LightGCN得到的每个用户对每个Item的打分其实就是user embedding和item embedding的内积,那如何保证这个是合理的呢?那损失函数就要登场了…
LightGCN用到的Loss函数为贝叶斯个性排序BPRLoss,公式如下:
基本思想是最大化正样本和负样本之间的差距,即用户会购买的商品与用户不会购买的商品之间的概率差距越大越好,代码如下:
def bpr_loss(self, users, pos, neg):
(users_emb, pos_emb, neg_emb,
userEmb0, posEmb0, negEmb0) = self.getEmbedding(users.long(), pos.long(), neg.long())
reg_loss = (1/2)*(userEmb0.norm(2).pow(2) +
posEmb0.norm(2).pow(2) +
negEmb0.norm(2).pow(2))/float(len(users))
pos_scores = torch.mul(users_emb, pos_emb)
pos_scores = torch.sum(pos_scores, dim=1)
neg_scores = torch.mul(users_emb, neg_emb)
neg_scores = torch.sum(neg_scores, dim=1)
loss = torch.mean(torch.nn.functional.softplus(neg_scores - pos_scores))
return loss, reg_loss
class BPRLoss:
def __init__(self,
recmodel : PairWiseModel,
config : dict):
self.model = recmodel
self.weight_decay = config['decay']
self.lr = config['lr']
self.opt = optim.Adam(recmodel.parameters(), lr=self.lr)
def stageOne(self, users, pos, neg):
loss, reg_loss = self.model.bpr_loss(users, pos, neg)
reg_loss = reg_loss*self.weight_decay
loss = loss + reg_loss
self.opt.zero_grad()
loss.backward()
self.opt.step()
return loss.cpu().item()
下面再看看LightGCN整体的代码:
class LightGCN(BasicModel):
def __init__(self,
config:dict,
dataset:BasicDataset):
super(LightGCN, self).__init__()
self.config = config
self.dataset : dataloader.BasicDataset = dataset
self.__init_weight()
def __init_weight(self):
self.num_users = self.dataset.n_users
self.num_items = self.dataset.m_items
self.latent_dim = self.config['latent_dim_rec']
self.n_layers = self.config['lightGCN_n_layers']
self.keep_prob = self.config['keep_prob']
self.A_split = self.config['A_split']
self.embedding_user = torch.nn.Embedding(
num_embeddings=self.num_users, embedding_dim=self.latent_dim)
self.embedding_item = torch.nn.Embedding(
num_embeddings=self.num_items, embedding_dim=self.latent_dim)
if self.config['pretrain'] == 0:
nn.init.normal_(self.embedding_user.weight, std=0.1)
nn.init.normal_(self.embedding_item.weight, std=0.1)
world.cprint('use NORMAL distribution initilizer')
else:
self.embedding_user.weight.data.copy_(torch.from_numpy(self.config['user_emb']))
self.embedding_item.weight.data.copy_(torch.from_numpy(self.config['item_emb']))
print('use pretarined data')
self.f = nn.Sigmoid()
self.Graph = self.dataset.getSparseGraph()
print(f"lgn is already to go(dropout:{self.config['dropout']})")
# print("save_txt")
def __dropout_x(self, x, keep_prob):
size = x.size()
index = x.indices().t()
values = x.values()
random_index = torch.rand(len(values)) + keep_prob
random_index = random_index.int().bool()
index = index[random_index]
values = values[random_index]/keep_prob
g = torch.sparse.FloatTensor(index.t(), values, size)
return g
def __dropout(self, keep_prob):
if self.A_split:
graph = []
for g in self.Graph:
graph.append(self.__dropout_x(g, keep_prob))
else:
graph = self.__dropout_x(self.Graph, keep_prob)
return graph
def computer(self):
"""
propagate methods for lightGCN
"""
users_emb = self.embedding_user.weight
items_emb = self.embedding_item.weight
all_emb = torch.cat([users_emb, items_emb])
# torch.split(all_emb , [self.num_users, self.num_items])
embs = [all_emb]
if self.config['dropout']:
if self.training:
print("droping")
g_droped = self.__dropout(self.keep_prob)
else:
g_droped = self.Graph
else:
g_droped = self.Graph
for layer in range(self.n_layers):
if self.A_split:
temp_emb = []
for f in range(len(g_droped)):
temp_emb.append(torch.sparse.mm(g_droped[f], all_emb))
side_emb = torch.cat(temp_emb, dim=0)
all_emb = side_emb
else:
all_emb = torch.sparse.mm(g_droped, all_emb)
embs.append(all_emb)
embs = torch.stack(embs, dim=1)
#print(embs.size())
light_out = torch.mean(embs, dim=1)
users, items = torch.split(light_out, [self.num_users, self.num_items])
return users, items
def getUsersRating(self, users):
all_users, all_items = self.computer()
users_emb = all_users[users.long()]
items_emb = all_items
rating = self.f(torch.matmul(users_emb, items_emb.t()))
return rating
def getEmbedding(self, users, pos_items, neg_items):
all_users, all_items = self.computer()
users_emb = all_users[users]
pos_emb = all_items[pos_items]
neg_emb = all_items[neg_items]
users_emb_ego = self.embedding_user(users)
pos_emb_ego = self.embedding_item(pos_items)
neg_emb_ego = self.embedding_item(neg_items)
return users_emb, pos_emb, neg_emb, users_emb_ego, pos_emb_ego, neg_emb_ego
def bpr_loss(self, users, pos, neg):
(users_emb, pos_emb, neg_emb,
userEmb0, posEmb0, negEmb0) = self.getEmbedding(users.long(), pos.long(), neg.long())
reg_loss = (1/2)*(userEmb0.norm(2).pow(2) +
posEmb0.norm(2).pow(2) +
negEmb0.norm(2).pow(2))/float(len(users))
pos_scores = torch.mul(users_emb, pos_emb)
pos_scores = torch.sum(pos_scores, dim=1)
neg_scores = torch.mul(users_emb, neg_emb)
neg_scores = torch.sum(neg_scores, dim=1)
loss = torch.mean(torch.nn.functional.softplus(neg_scores - pos_scores))
return loss, reg_loss
def forward(self, users, items):
# compute embedding
all_users, all_items = self.computer()
# print('forward')
#all_users, all_items = self.computer()
users_emb = all_users[users]
items_emb = all_items[items]
inner_pro = torch.mul(users_emb, items_emb)
gamma = torch.sum(inner_pro, dim=1)
return gamma
4.2 LightGCN数据构造代码
了解了LightGCN模型后,是不是迫不及待想要train一个试试了呢~
别急!
下面我们来看看训练和测试数据是怎么构造的:
首先,LightGCN的Dataloader会继承一个BasicDataset类,里面初始化了所有要使用到的方法。
class BasicDataset(Dataset):
def __init__(self):
print("init dataset")
@property
def n_users(self):
raise NotImplementedError
@property
def m_items(self):
raise NotImplementedError
@property
def trainDataSize(self):
raise NotImplementedError
@property
def testDict(self):
raise NotImplementedError
@property
def allPos(self):
raise NotImplementedError
def getUserItemFeedback(self, users, items):
raise NotImplementedError
def getUserPosItems(self, users):
raise NotImplementedError
def getUserNegItems(self, users):
"""
not necessary for large dataset
it's stupid to return all neg items in super large dataset
"""
raise NotImplementedError
def getSparseGraph(self):
"""
build a graph in torch.sparse.IntTensor.
Details in NGCF's matrix form
A =
|I, R|
|R^T, I|
"""
raise NotImplementedError
下面来看看正式的DataLoader定义
class Loader(BasicDataset):
"""
Dataset type for pytorch \n
Incldue graph information
gowalla dataset
"""
def __init__(self,config = world.config,path="../data/gowalla"):
# 基本参数的初始化
cprint(f'loading [{path}]')
self.split = config['A_split']
self.folds = config['A_n_fold']
self.mode_dict = {'train': 0, "test": 1}
self.mode = self.mode_dict['train']
self.n_user = 0
self.m_item = 0
train_file = path + '/train.txt'
test_file = path + '/test.txt'
self.path = path
trainUniqueUsers, trainItem, trainUser = [], [], []
testUniqueUsers, testItem, testUser = [], [], []
self.traindataSize = 0
self.testDataSize = 0
# 读取数据
# .txt格式:userID itemID1 itemID2 ... itemIDn
with open(train_file) as f:
for l in f.readlines():
if len(l) > 0:
l = l.strip('\n').split(' ')
items = [int(i) for i in l[1:]]
uid = int(l[0])
trainUniqueUsers.append(uid)
trainUser.extend([uid] * len(items))
trainItem.extend(items)
self.m_item = max(self.m_item, max(items))
self.n_user = max(self.n_user, uid)
self.traindataSize += len(items)
self.trainUniqueUsers = np.array(trainUniqueUsers)
self.trainUser = np.array(trainUser)
self.trainItem = np.array(trainItem)
with open(test_file) as f:
for l in f.readlines():
if len(l) > 0:
l = l.strip('\n').split(' ')
items = [int(i) for i in l[1:]]
uid = int(l[0])
testUniqueUsers.append(uid)
testUser.extend([uid] * len(items))
testItem.extend(items)
self.m_item = max(self.m_item, max(items))
self.n_user = max(self.n_user, uid)
self.testDataSize += len(items)
self.m_item += 1
self.n_user += 1
self.testUniqueUsers = np.array(testUniqueUsers)
self.testUser = np.array(testUser)
self.testItem = np.array(testItem)
self.Graph = None
print(f"{self.trainDataSize} interactions for training")
print(f"{self.testDataSize} interactions for testing")
print(f"{world.dataset} Sparsity : {(self.trainDataSize + self.testDataSize) / self.n_users / self.m_items}")
# 构建(users,items)二分图
self.UserItemNet = csr_matrix((np.ones(len(self.trainUser)), (self.trainUser, self.trainItem)),
shape=(self.n_user, self.m_item))
self.users_D = np.array(self.UserItemNet.sum(axis=1)).squeeze()
self.users_D[self.users_D == 0.] = 1
self.items_D = np.array(self.UserItemNet.sum(axis=0)).squeeze()
self.items_D[self.items_D == 0.] = 1.
# pre-calculate
# 获得各用户购买过物品的index,即正样本
self._allPos = self.getUserPosItems(list(range(self.n_user)))
self.__testDict = self.__build_test()
print(f"{world.dataset} is ready to go")
@property
def n_users(self):
return self.n_user
@property
def m_items(self):
return self.m_item
@property
def trainDataSize(self):
return self.traindataSize
@property
def testDict(self):
return self.__testDict
@property
def allPos(self):
return self._allPos
def _split_A_hat(self,A):
A_fold = []
fold_len = (self.n_users + self.m_items) // self.folds
for i_fold in range(self.folds):
start = i_fold*fold_len
if i_fold == self.folds - 1:
end = self.n_users + self.m_items
else:
end = (i_fold + 1) * fold_len
A_fold.append(self._convert_sp_mat_to_sp_tensor(A[start:end]).coalesce().to(world.device))
return A_fold
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo().astype(np.float32)
row = torch.Tensor(coo.row).long()
col = torch.Tensor(coo.col).long()
index = torch.stack([row, col])
data = torch.FloatTensor(coo.data)
return torch.sparse.FloatTensor(index, data, torch.Size(coo.shape))
def getSparseGraph(self):
print("loading adjacency matrix")
if self.Graph is None:
try:
pre_adj_mat = sp.load_npz(self.path + '/s_pre_adj_mat.npz')
print("successfully loaded...")
norm_adj = pre_adj_mat
except :
print("generating adjacency matrix")
s = time()
adj_mat = sp.dok_matrix((self.n_users + self.m_items, self.n_users + self.m_items), dtype=np.float32)
adj_mat = adj_mat.tolil()
R = self.UserItemNet.tolil()
adj_mat[:self.n_users, self.n_users:] = R
adj_mat[self.n_users:, :self.n_users] = R.T
adj_mat = adj_mat.todok()
# adj_mat = adj_mat + sp.eye(adj_mat.shape[0])
rowsum = np.array(adj_mat.sum(axis=1))
d_inv = np.power(rowsum, -0.5).flatten()
d_inv[np.isinf(d_inv)] = 0.
d_mat = sp.diags(d_inv)
norm_adj = d_mat.dot(adj_mat)
norm_adj = norm_adj.dot(d_mat)
norm_adj = norm_adj.tocsr()
end = time()
print(f"costing {end-s}s, saved norm_mat...")
sp.save_npz(self.path + '/s_pre_adj_mat.npz', norm_adj)
if self.split == True:
self.Graph = self._split_A_hat(norm_adj)
print("done split matrix")
else:
self.Graph = self._convert_sp_mat_to_sp_tensor(norm_adj)
self.Graph = self.Graph.coalesce().to(world.device)
print("don't split the matrix")
return self.Graph
def __build_test(self):
"""
return:
dict: {user: [items]}
"""
test_data = {}
for i, item in enumerate(self.testItem):
user = self.testUser[i]
if test_data.get(user):
test_data[user].append(item)
else:
test_data[user] = [item]
return test_data
def getUserItemFeedback(self, users, items):
"""
users:
shape [-1]
items:
shape [-1]
return:
feedback [-1]
"""
# print(self.UserItemNet[users, items])
return np.array(self.UserItemNet[users, items]).astype('uint8').reshape((-1,))
def getUserPosItems(self, users):
posItems = []
for user in users:
posItems.append(self.UserItemNet[user].nonzero()[1])
return posItems
4.3 LightGCN训练
到此,我们准备好了模型,准备好了数据。
终于可以开始训练啦!
下面的代码块为总体的训练代码:
def BPR_train_original(dataset, recommend_model, loss_class, epoch, neg_k=1, w=None):
"""bpr = BPRLoss(Recmodel, world.config) """
Recmodel = recommend_model
Recmodel.train()
bpr: BPRLoss = loss_class
with timer(name="Sample"):
S = UniformSample_original(dataset) # 采样,每个user采样一个正样本和一个负样本
# 提取用户id,正样本,负样本
users = torch.Tensor(S[:, 0]).long()
posItems = torch.Tensor(S[:, 1]).long()
negItems = torch.Tensor(S[:, 2]).long()
users = users.to(world.device)
posItems = posItems.to(world.device)
negItems = negItems.to(world.device)
users, posItems, negItems = utils.shuffle(users, posItems, negItems)
total_batch = len(users) // world.config['bpr_batch_size'] + 1
aver_loss = 0.
# btach train
for (batch_i,
(batch_users,
batch_pos,
batch_neg)) in enumerate(minibatch(users,
posItems,
negItems,
batch_size=world.config['bpr_batch_size'])): # 随机采样一定比例的正负样本,每个minibatch算一个loss
cri = bpr.stageOne(batch_users, batch_pos, batch_neg)
aver_loss += cri
if world.tensorboard:
w.add_scalar(f'BPRLoss/BPR', cri, epoch * int(len(users) / world.config['bpr_batch_size']) + batch_i)
aver_loss = aver_loss / total_batch
time_info = timer.dict()
timer.zero()
return f"loss{aver_loss:.3f}-{time_info}"
可以看到,基本的流程为:
- 采样正负样本;
- 随机置乱样本顺序;
- minibatch训练。
下面就来看看怎么采样正负样本:
def UniformSample_original(dataset, neg_ratio = 1):
dataset : BasicDataset
allPos = dataset.allPos
start = time()
if sample_ext:
S = sampling.sample_negative(dataset.n_users, dataset.m_items,
dataset.trainDataSize, allPos, neg_ratio)
else:
S = UniformSample_original_python(dataset)
return S
def UniformSample_original_python(dataset):
"""
采样正负样本,每个用户采样一个正样本和一个负样本
:return:
np.array
"""
total_start = time()
dataset : BasicDataset
user_num = dataset.trainDataSize
users = np.random.randint(0, dataset.n_users, user_num)
allPos = dataset.allPos
S = []
sample_time1 = 0.
sample_time2 = 0.
for i, user in enumerate(users):
start = time()
posForUser = allPos[user]
if len(posForUser) == 0:
continue
sample_time2 += time() - start
posindex = np.random.randint(0, len(posForUser))
positem = posForUser[posindex]
while True:
negitem = np.random.randint(0, dataset.m_items)
if negitem in posForUser:
continue
else:
break
S.append([user, positem, negitem])
end = time()
sample_time1 += end - start
total = time() - total_start
return np.array(S)
总的来说,就是为每个user分别采样出1个或个与ta相连和不相连的item。
接着,再看看minibatch
def minibatch(*tensors, **kwargs):
"""按batch size来切割数据"""
batch_size = kwargs.get('batch_size', world.config['bpr_batch_size'])
if len(tensors) == 1:
tensor = tensors[0]
for i in range(0, len(tensor), batch_size):
yield tensor[i:i + batch_size]
else:
for i in range(0, len(tensors[0]), batch_size):
yield tuple(x[i:i + batch_size] for x in tensors)
其实就是按batch size将数据进行切分。
好了,总体代码如下:
def UniformSample_original(dataset, neg_ratio = 1):
dataset : BasicDataset
allPos = dataset.allPos
start = time()
if sample_ext:
S = sampling.sample_negative(dataset.n_users, dataset.m_items,
dataset.trainDataSize, allPos, neg_ratio)
else:
S = UniformSample_original_python(dataset)
return S
def UniformSample_original_python(dataset):
"""
采样正负样本,每个用户采样一个正样本和一个负样本
:return:
np.array
"""
total_start = time()
dataset : BasicDataset
user_num = dataset.trainDataSize
users = np.random.randint(0, dataset.n_users, user_num)
allPos = dataset.allPos
S = []
sample_time1 = 0.
sample_time2 = 0.
for i, user in enumerate(users):
start = time()
posForUser = allPos[user]
if len(posForUser) == 0:
continue
sample_time2 += time() - start
posindex = np.random.randint(0, len(posForUser))
positem = posForUser[posindex]
while True:
negitem = np.random.randint(0, dataset.m_items)
if negitem in posForUser:
continue
else:
break
S.append([user, positem, negitem])
end = time()
sample_time1 += end - start
total = time() - total_start
return np.array(S)
def minibatch(*tensors, **kwargs):
"""按batch size来切割数据"""
batch_size = kwargs.get('batch_size', world.config['bpr_batch_size'])
if len(tensors) == 1:
tensor = tensors[0]
for i in range(0, len(tensor), batch_size):
yield tensor[i:i + batch_size]
else:
for i in range(0, len(tensors[0]), batch_size):
yield tuple(x[i:i + batch_size] for x in tensors)
# 训练函数
def BPR_train_original(dataset, recommend_model, loss_class, epoch, neg_k=1, w=None):
"""bpr = utils.BPRLoss(Recmodel, world.config) """
Recmodel = recommend_model
Recmodel.train()
bpr: utils.BPRLoss = loss_class
with timer(name="Sample"):
S = utils.UniformSample_original(dataset) # 采样,每个user采样一个正样本和一个负样本
# 提取用户id,正样本,负样本
users = torch.Tensor(S[:, 0]).long()
posItems = torch.Tensor(S[:, 1]).long()
negItems = torch.Tensor(S[:, 2]).long()
users = users.to(world.device)
posItems = posItems.to(world.device)
negItems = negItems.to(world.device)
users, posItems, negItems = utils.shuffle(users, posItems, negItems)
total_batch = len(users) // world.config['bpr_batch_size'] + 1
aver_loss = 0.
# btach train
for (batch_i,
(batch_users,
batch_pos,
batch_neg)) in enumerate(minibatch(users,
posItems,
negItems,
batch_size=world.config['bpr_batch_size'])): # 随机采样一定比例的正负样本,每个minibatch算一个loss
cri = bpr.stageOne(batch_users, batch_pos, batch_neg)
aver_loss += cri
if world.tensorboard:
w.add_scalar(f'BPRLoss/BPR', cri, epoch * int(len(users) / world.config['bpr_batch_size']) + batch_i)
aver_loss = aver_loss / total_batch
time_info = timer.dict()
timer.zero()
return f"loss{aver_loss:.3f}-{time_info}"
参考资料:
文章出处登录后可见!