基本信息
· 题目:Multi-instance Learning with Discriminative Bag Mapping
· 会议:IEEE
摘要
目前,通过选择一个实例将一个包转化为一个新空间中的单个实例,主要是基于原始空间。但是基于原始空间的映射有一些缺陷,如:难以保证所选实例的识别能力。因此,允许一组实例共享一个标签,是解决学习中标签歧义问题的有效工具。本文提出了一种用于多示例学习的判别映射方法,旨在识别最佳实例,从而直接区分新映射空间中的包。
介绍
在有监督学习中,每一个训练样本都是一个带有类标签的实例;与有监督学习相比,多示例学习中的每一个训练样本则是一个含有多个实例的包,每个包都带有类标签。标签是分配给包的而不是给实例的。
若一个包是负包,那么该负包中的所有实例都是负的;但对于正包来说,包中至少有一个实例时正的。
现有的MIL方案主要分为两类:①改进传统的学习算法来解决标签歧义问题;②开发专门用于多示例学习的学习范式。但以上两种方案无法在包中含有大量实例的情况下呈现出优越的性能。
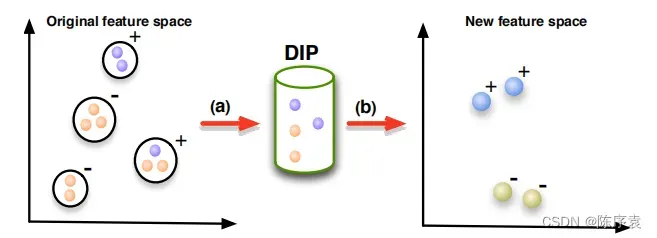
因此,本文提出一种用于多示例学习的直接判别映射方法,旨在识别那些能够使包在新的映射空间中能够被明显区分的实例。
相关工作
当数据集较庞大时,算法需要处理大量的实例。在这种情况下,选择那些最具代表性的实例来代表包就成为了一个具有挑战性的问题。解决这类问题的一种新方法是:使用那些在包中选择的实例,并将MIL问题转换为标准的单实例学习问题。我们将这些方法称为“基于实例选择的MIL”。可以将它们分为两类:①基于实例选择的非包映射方法;②基于实例选择的包映射方法。
①非包映射方法
该方法的基本思想是:从每个包中选出一个或多个实例来表示整个包。直接将包标签映射给包中的所有实例,让所有实例来表示包。但由于包中大部分信息都被丢弃,这种方法往往面临信息丢失和分类性能下降的问题。
②包映射方法
选择一组实例原型,将包映射到一个新的特征空间。
符合与算法框架
本文符号表如下:
| 符号 | 含义 |
|---|---|
| 训练集 | |
| 包数量 | |
| 第 | |
| 标签 | |
| 实例集 | |
| 第 | |
| 实例空间大小 | |
| 判别实例池(Discriminative Instance Pool, DIP) | |
| DIP大小 | |
| 包映射 | |
| 包 |
一个包包含许多实例,实例
表示在第
个包中的第
个实例。用
来表示包
的标签。
在训练的过程中,所有的包都通过discriminative instance pool(DIP)转换称为一个新的特征空间中的一个单实例
。我们将DIP通过
来表示。
在测试过程中,先通过DIP将每一个包映射为特征空间中新的实例,然后利用训练好的分类器来预测最终的类标签。该过程中最关键的一部分就是找到最优的用于包映射的DIP(discriminative instance pool)。
DIP(discriminative instance pool) Optimization
DIP优化目标为:使用一个实例选择矩阵(一种对角矩阵,
)来找到一个子集
。而
是一个启示向量。若
,那么
,否则
。
我们定义作为实例评估函数,用于评价子集
的质量。表达式如下:
其中,表示实例集的基数,而
为从实例集
中选出的实例数量。
DIP评价标准
为了能够得到具有一定鉴别实例能力的DIP,引入以下两个规则:
①bag mapping must-link:由于每一个包都带有一个正或负类标签,因此DIP必须确保在另一个映射空间中的包
标签与包
标签一致;
②bag mapping cannot-link:在映射空间中带有不同类别标签的包应该代表它们之间的差异;
DIP评价标准可以表示为:
其中,表示通过DIP得到的新的映射空间中包
与包
之间的距离。
表示映射空间的区别程度。
能够表示为:
其中,与
一样都使用了所有实例作为映射实例池。将标签嵌入矩阵
定义为:
其中,表示bag mapping must-link的包集;
表示bag mapping cannot-link的包集。
的推导过程如下:
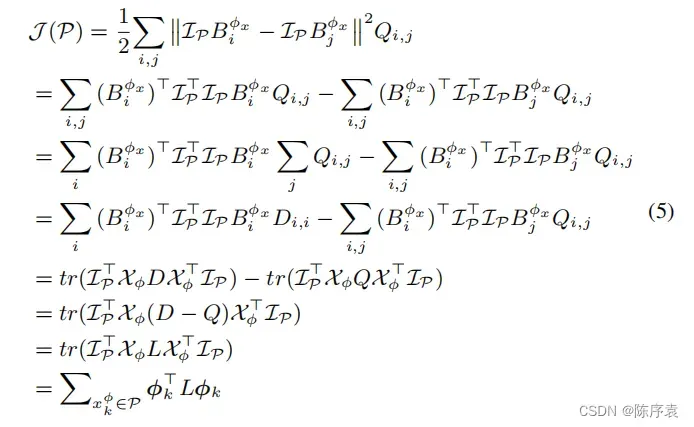
其中,表示矩阵迹算子,
,
代表包的大小。
是对角矩阵,它由矩阵
产生。
是拉普拉斯(Laplacian)矩阵,由矩阵
产生,
可以表示为
。通过函数
来表示
。
最开始的优化问题可以转化为求使函数得到最大和的实例映射集合
:
DIP算法流程如图所示:

通过DIP实现包映射
一旦使用选择好的实例构建DIP,每个包都需要映射到新空间中的单个实例。给定一个DIP判别实例池,该DIP中有
个实例,包
能够映射为一个实例
,而
代表包
与示例
之间的相似度,表示为:
其中,代表在第
个包
中的第
个实例,
为预设的比例因子。通过优化的DIP,每一个包
都映射为
。
映射算法又分为两类:①Global DiscriminativeBag Mapping;②Local Discriminative Bag Mapping
①Global DiscriminativeBag Mapping
这种映射方法是通过计算所有包中的每一个实例到DIP中的前个实例间的距离进行计算。
·aMILGDM:使用所有的训练集包来产生全局DIP
·pMILGDM:仅使用正包
② Local Discriminative Bag Mapping
这种映射方法计算了包中的每一个实例并选出一个具有最高识别分数的实例。
·aMILLDM:从每一个包中找出具有最高识别分数的实例
·pMILLDM:从每一个正包中找出具有最高识别分数的实例
文章出处登录后可见!