决策树(Decision Tree)
时间:2022/2/17
1.相关知识
-
决策树归纳:从有类标号的训练元组中学习决策树。
-
决策树:决策树是一种类似于流程图的树结构,其中,每个内部结点表示在一个属性上的测试,每个分支表示该测试的输出,而每个叶子结点存放一个类标号。如下图所示,内部结点矩形表示,树叶用椭圆表示。有的决策树算法是只产生二叉树,有的决策树算法会产生非二叉树。
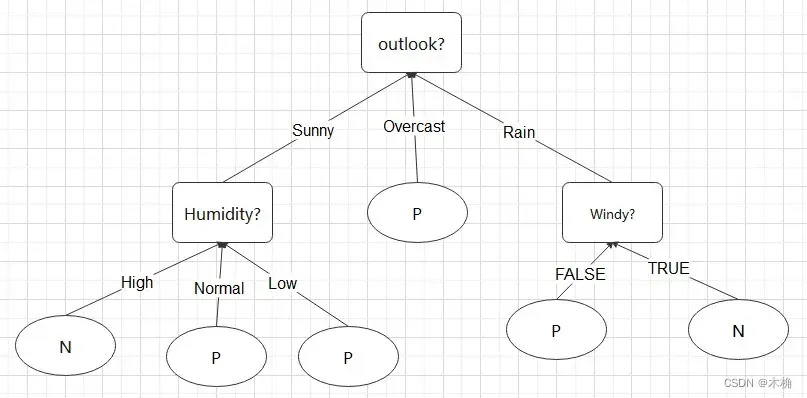
-
如何使用决策树进行分类?
对于给定的未知类标号的元组X,在决策树上测试该元组的属性值。跟踪一条从根到树叶结点的路径,树叶上存放的便是该元组的预测类标号。 -
决策树的特点:
- 分类器的构造符合人类的思维,不需要任何领域知识或参数设置,因此适合探测式知识发现。
- 决策树可处理高维数据。
- 决策树的模型用树形表示直观易懂,很容易转化成分类规则。
- 决策树归纳的学习和分类步骤是简单和快速的。且一般具备较好的准确率。
- 决策树的准确率依赖于训练样本。
-
决策树的发展历史。
在20世纪80年代初期,机器学习研究员J.Ross Quinlan开发了决策树算法,称为迭代的二分器(Iterative Dichotomiser,ID3)。后来Quinlan提出了C4.5(ID3的后继),成为了新的监督学习算法的性能比较基准。1984年,多位统计学家出版了著作《Classification and Regression Tree》(CART),介绍了二叉决策树的产生。ID3、C4.5和CART都采用了贪心算法,其中决策树以自顶向下递归的分治方式构造,从训练样本和它们相关联的类标号开始构建决策树。
2.决策树构建算法
算法:Generate_decision_tree.由数据分区D中的训练样本通过产生决策树。
输入:
1.数据分区D,训练样本和它们对应类标号的集合。
2.attribute_list,候选属性集合。
3.Attribute_selection_method,一个确定“最好地”划分数据元组为个体类的分裂准则的过程。这个准则由分裂属性(splitting_attribute)和分
裂点或划分子集组成。
输出:一棵决策树。
方法:
(1) 创建一个结点N;
(2) if D中的元组都在同一类C中 then
(3) 返回N作为叶子结点,以类C为标记;
(4) if attribute_list为空 then
(5) 返回N作为叶子结点,以D中的多数类标号为标记; //多数表决
(6) 使用Attribute_selection_method(D,attribute_list),找出“最好的”splitting_criterion;
(7) 用splitting_criterion标记结点N;
(8) if splitting_criterion是离散值的,并且允许多路划分 then //不限二叉树
(9) attribute_list=attribute_list-splitting_criterion; //去掉分裂属性
(10)for splitting_criterion的每一个输出j
//划分元组并对每一个分区产生子树
(11) 设Dj是D中满足输出j的数据元组的集合; //一个分区
(12) if Dj为空
(13) 加一个树叶到结点N,标记为D中的大多数类; //分区没有结点
(14) else 加一个Generate_decision_tree(Dj,attribute_list)产生的结点到N;//构建子树
endfor
(15)返回N;
-
Attribute_selection_method指定选择属性的启发过程,用来选择可以按类”最好的“区分给定元组的属性。该过程使用一种属性选择度量,如信息增益或基尼指数(Gini index)。
-
决策树是否严格的二叉树是由属性选择度量决定的。基尼指数会强制结果是一种二叉树,而信息增益允许决策树多路划分。
-
Attribute_selection_method确定分裂准则(splitting_criterion)。分裂准则指定分裂属性,并且指出分裂点(splitting-point)或者分裂子集(splitting subset)。
-
理想情况下分裂子集应当是纯的,即所有的元组属于同一类。一般当达不到理想情况时使用多数表决,将多数类的类标号作为整个分区的类标号。
-
若元组属性是离散值则分裂方法如图1所示。
-
若元组属性是连续的值,可设定阈值作为分裂点split_point,产生两个分支
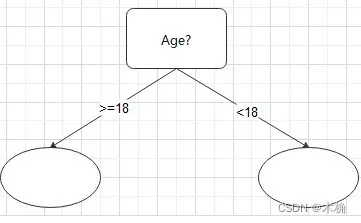
-
若元组属性是离散值,且必须产生二叉树则,则测试形如
,其中
是A的分裂子集
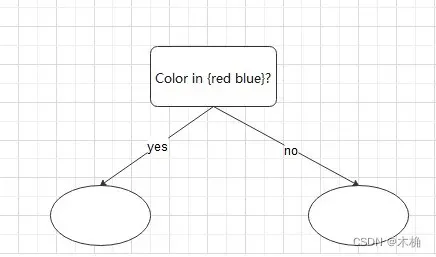
-
给定的训练集D,算法的计算复杂度为O(n*|D|*log(|D|)),其中n是D中元组的属性个数,|D|是D中元组的个数。
3属性选择度量
属性选择度量为描述给定训练元组的每个属性提供了秩评定。具有最好度量得分的属性将作为给定元组的分裂属性。若分裂属性是连续值或者需要严格二叉树,则分裂点或分裂子集也应当作为分裂准则的返回值。以下介绍三种常用的属性选择度量——信息增益、增益率、基尼指数。
设数据分区D为标记类元组的训练集。假定类标号属性具有m个不同值,定义了m个不同的类(i=1,…,m)。设
是D中
类元素的集合,|D|和
分别是D和
中元组的个数。
3.1 信息增益
ID3使用信息增益作为属性选择度量。该度量基于香农(Claude Shannon)在研究消息的值或者”信息内容“的信息论方面的先驱工作。设结点N代表或存放分区D的元组,选择具有最高信息增益的属性作为结点N的分裂属性。该属性使结果分区中对元组分类所需要的信息量最小,并反映这些分区中的最小随机性或”不纯性“。这种方法使得对一个对象的分类所需要的期望测试数目最小,并确保找到一棵简单的(但不必最简单)树。
对D中元组分类所需要的期望信息如下:
其中是D中任意元组属于类
的非零概率,并用
估计。使用以2为底的对数函数是因为信息是以二进制编码。
是识别D中元组的类标号所需要的平均信息量,也叫D的信息熵。此时我们所有的信息只是每个类的元组所占的百分比。
现在,假设我们要按照某个属性A进行划分D中的元组,其中A在训练集中具有v个不同值。如果A是离散值,则这些值对应于A上测试的v个输出。将训练集D按照A划分为v个分区
,其中
对应于属性A的值
。理想情况下希望分区都是纯的,但一般情况下是不纯的,包含不同类的元组。在划分之后为了得到准确的分类,我们还需要的信息如下:
是第j个分区的权重。
是基于按A划分对于D的元组分类所需要的期望信息。该期望信息越小,分区纯度越高。
而信息增益则定义为原来的信息需求(仅基于类比例)与新的信息需求(对A划分之后)的差值。如下:
表示通过A属性的划分我们得到了多少信息。使用具有最高信息增益的属性A作为结点N的分裂属性,等价于在A属性的划分,使得完成元组分类还需要的信息最小(最小化
)。
如何计算连续值属性的信息增益?
对于连续值属性计算时必须确定属性A的最佳分裂点。首先将A的值进行升序排序。典型的每对相邻值的中点被看作可能的分裂点。对于给定A的v个值,需要计算v-1个可能的划分。比如A属性的的中点便是
对于A的每个可能的分裂点计算,D按照分裂点划分为两个分区。选择具有最小期望信息值的点作为分裂点(
)。
3.2增益率
信息增益偏向于具有许多输出的测试,或者说是更加适用于具有大量值的属性。但像唯一标识符属性productID,在其上的划分将导致大量分区(与取值个数一样多),每个分区只有一个元组。这导致每个分区都是纯的,因为只有一个,故其。因此,通过对该属性的划分得到的信息增益最大,但这样的划分是没有意义的。
ID3的后继C4.5使用一种称为增益率(gain ratio)的信息增益扩充,试图克服这种偏倚。它使用“分裂信息(split information)”值将信息增益规范化。该值定义如下:
该值表示由训练集D按照属性A划分成v个分区产生的信息。值得注意的一点是,对于每个输出,它们相对于D中元组的总数考虑具有该输出的元组数即,与信息增益的
不同。则增益率表示为:
需要注意的是,随者划分信息趋近于0,该比率变得不稳定。为了避免这种情况,增加一个约束:选择的测试信息增益必须比较大,至少不小于与考察的所有测试的平均增益。
3.3基尼指数
基尼指数(Gini index)是在CART中使用的,用于度量数据分区或训练样本D的不纯度,定义为:
与信息增益一致,表示D中元组属于
。对m个类计算和。
基尼指数考虑每个属性的二元划分。首先是A是离散值属性时,其中A具有v个不同的值{ }出现在D中。考察使用A已知值的所有可能子集。每个子集
可以看作是属性A的一个形如”
“的二元测试,对于一个给定的元组,如果该元组A的值出现在
中,则满足测试。对于一个具有v个可能取值的属性A,存在
个子集。但是幂集(全集)和空集是不考虑的,因为这两者并没有起到划分的作用。所以A属性的二元划分方法具有
种可能。
对于A的二元分裂时,计算每种划分可能的基尼指数加权和。如下:
对每个属性考虑每种可能的二元划分划分。对离散值属性,选取该属性产生基尼指数最小的子集作为分裂子集。对于连续值属性,考虑每一个分裂点,如信息增益一样,将每两个相邻的值的中点作为可能的分裂点,选取产生最小基尼指数的点作为分裂点。
对于离散值或连续值属性A的二元划分导致的不纯度降低为:
选择最大化的属性作为分裂属性,该属性和它的分裂点或分裂子集一同形成分裂准则。
3.4其他属性选择度量
目前的三种属性选择度量并不是无偏的,信息增益偏向于多值属性,虽然增益率调整了这种偏倚,但它更倾向于产生不平衡的划分,其中一个分区会远远小于其他分区。基尼指数也偏向于多值属性,并且当类的数量很大时会有困难,而且还倾向于产生相等大小的分区和纯度。虽然有偏倚,但在实践中产生的效果都很不错。
其他的一些度量还有基于统计检验的属性度量、CSEP和G-统计量(一种信息论度量,近似于
)。基于最小描述长度(Minimun Description Length,MDL)原理的属性选择度量具有最小偏向于多值属性的偏倚。
其他的属性选择度量考虑多元划分。多元划分是一种属性的构造方法,其中新属性由已有属性构造,即元组的划分基于属性的组合而不是单个属性。
所有的属性选择度量均存在偏倚。已经证明决策树的归纳的时间复杂度随树的高度指数增长,所以产生更矮的树的度量可能更加可取。但实践中并没有某一种属性度量明显优于其他度量。
4.树剪枝
在决策树创建时,由于数据中的噪声和离群点,许多分支反应的是训练样本中的异常情况。一棵决策树分支越多,则表明它对训练样本的拟合程度就越高,有时会出现分类器在训练样本的准确度很高,但在测试样本的分类准确度反而很低,这便是数据过拟合的情况。因为决策树的构建时是基于训练样本的,不管是采用何种分裂规则,都会受到训练样本的影响,如果训练样本的代表性不够,那么便会产生过拟合的情况。针对于这种情况,可以使用剪枝的方法减小过拟合程度。一棵决策树越简单,它的适用性便越好,但同时,也会导致错误率的上升,需要平衡好二者的关系。
剪枝的方法有两种常用的方法:前剪枝和后剪枝。
前剪枝(prepruning方法中通过提前停止树的构建(例如通过决定在给定的结点不再分裂或者划分训练样本的子集)而对树剪枝。停止树的构建后,结点便成为一个叶子结点,该树叶拥有子集元组中最评分的类,或者这些元组的概率分布。构造树时,可以使用如统计显著性、信息增益、基尼指数等度量评估分裂的好坏,可以设定一个阈值,如果分裂的度量低于设定阈值,便停止划分。但阈值的选取是很难达到一个合适值的,过高的阈值会导致太简化的树;过低的阈值会导致剪枝效果不明显。
后剪枝(postpruning),它由”完全生长”的树减去子树。让决策树完全分化,之后再删除结点的分支并转化成树叶,剪短给定结点的子树。一般使用子树中最频繁的类标号作为树叶的类标号。CART使用的代价复杂度剪枝算法便是后剪枝。该方法把树的复杂度看作树中树叶的个数和树的错误率的函数(错误率是树中错误分类的元组所占百分比)。它从树底部开始,对每个内部节点N,计算N的子树的代价复杂度和该子树剪枝后的代价复杂度,若剪枝后的代价复杂度更低则减去该子树,否则保留该子树。使用一个带标记的剪枝集数据来评估代价复杂度,该数据集独立于训练集和测试集。
还可以将前剪枝与后剪枝进行组合的方法,二者交叉使用,后剪枝一般计算量大于前剪枝,但产生的树更加可靠。目前并未发现一种剪枝方法明显优于其他方法。
5.ID3的构造实现
ID3采用信息增益作为属性选择度量,这里我们采用前剪枝的方法进行剪枝,设定分区大小最小为3个元组。
采用数据集为weather数据集,由于只有14个数据,数据集太小了,测试时也是采用的自身测试虽然测试准确度很高,但测试效果可信度不高。
具体代码如下
/**
* ID3.java
*
* @author zjy
* @date 2022/5/17
* @Description:用于ID3决策树学习
* @version V1.0
*/
package swpu.zjy.ML.DecisionTree;
import weka.core.Instance;
import weka.core.Instances;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Arrays;
public class ID3 {
/**
* 数据集实体
*/
public Instances dataset=null;
//分区是否是纯的
boolean isPure;
//决策属性的取值
int numClasses;
//可用的数据元组
int[] availableInstances;
//可用的分裂属性
int[] availableAttribute;
//当前分裂点选取的分裂属性
int splitAttribute;
//当前分裂点的孩子结点
ID3[] children;
//出现不在决策树中的决策路径时或者达到最小分块还是不纯时,使用的默认标签
int defaultlabel;
//分区最小数据个数,分区可用数据等于最小数据时不再分裂
static int smallBlockThreshold=3;
/**
* 构造方法,初始化决策树
* @param dataSetFileName 数据集文件路径
*/
public ID3(String dataSetFileName){
try {
FileReader fileReader=new FileReader(dataSetFileName);
dataset=new Instances(fileReader);
fileReader.close();
} catch (Exception e) {
e.printStackTrace();
}
dataset.setClassIndex(dataset.numAttributes()-1);
numClasses=dataset.numClasses();
//提取可用数据
availableInstances=new int[dataset.numInstances()];
for (int i=0;i<availableInstances.length;i++){
availableInstances[i]=i;
}
//提取可用属性
availableAttribute=new int[dataset.numAttributes()-1];
for (int i=0;i<availableAttribute.length;i++){
availableAttribute[i]=i;
}
children=null;
//提取默认标号
defaultlabel=getMajorityClass(availableInstances);
//判断是否是纯的
isPure=pureJudge(availableInstances);
}
/**
* ID3构造方法,构造子树时使用
* @param dataset 数据集
* @param availableBlock 可用分区
* @param availableAttributes 可用属性
*/
public ID3(Instances dataset,int[] availableBlock,int[] availableAttributes){
this.availableInstances=availableBlock;
this.availableAttribute=availableAttributes;
this.dataset=dataset;
this.children=null;
this.defaultlabel=getMajorityClass(availableBlock);
this.isPure=pureJudge(availableInstances);
}
/**
* 判断分区是否是纯的
* @param availableBlock 数据分块
* @return 判断结果
*/
private boolean pureJudge(int[] availableBlock) {
boolean tempPure=true;
for(int i=0;i<availableBlock.length;i++){
if(dataset.instance(availableBlock[i]).classValue()!=dataset.instance(availableBlock[0]).classValue()){
tempPure=false;
break;
}
}
return tempPure;
}
/**
* 通过投票获取分区内最多的类标号
* @param availableBlock 分区
* @return 类标号
*/
private int getMajorityClass(int[] availableBlock) {
int[] tempClassCounts=new int[dataset.numClasses()];
//投票
for (int i = 0; i < availableBlock.length; i++) {
tempClassCounts[(int) dataset.instance(availableBlock[i]).classValue()]++;
}
int resultClass=-1;
int tempMaxClass=-1;
for (int i=0;i<tempClassCounts.length;i++){
if(tempMaxClass<tempClassCounts[i]){
tempMaxClass=tempClassCounts[i];
resultClass=i;
}
}
return resultClass;
}
/**
* 选择剩余属性中信息增益最大的属性
* @return 信息增益最大属性
*/
private int selectBestSplitAttribute(){
int tempSplitAttribute=-1;
double tempMinEntropy=Double.MAX_VALUE;
double tempEntropy=0;
for (int i=0;i<this.availableAttribute.length;i++){
tempEntropy=conditionalEntropy(this.availableAttribute[i]);
if(tempMinEntropy>tempEntropy){
tempMinEntropy=tempEntropy;
tempSplitAttribute=this.availableAttribute[i];
}
}
return tempSplitAttribute;
}
/**
* 计算属性信息增益,这里只比较大小,不用与info(D)相减
* @param attribute 需要计算的属性
* @return 该属性信息增益
*/
private double conditionalEntropy(int attribute) {
//统计数据
int tempNumValues=dataset.attribute(attribute).numValues();
int tempNumClasses=dataset.numClasses();
//|D|
int tempNumInstances=availableInstances.length;
//|Dj|
double[] tempValueCounts=new double[tempNumValues];
double[][] tempCountMatrix=new double[tempNumValues][tempNumClasses];
int tempClass,tempValue;
for (int i=0;i<tempNumInstances;i++){
tempClass=(int)dataset.instance(availableInstances[i]).classValue();
tempValue=(int)dataset.instance(availableInstances[i]).value(attribute);
tempValueCounts[tempValue]++;
tempCountMatrix[tempValue][tempClass]++;
}
double resultEntropy=-1;
double tempEntropy,tempOdds;
for (int i=0;i<tempNumValues;i++){
if(tempValueCounts[i]==0){
continue;
}
//计算info(Dj)
tempEntropy=0;
for (int j=0;j<tempNumClasses;j++){
tempOdds=tempCountMatrix[i][j]/tempValueCounts[i];
if(tempOdds==0){
continue;
}
tempEntropy+=-tempOdds*Math.log(tempOdds);
}
//InfoA(D)
resultEntropy+=tempValueCounts[i]/tempNumInstances*tempEntropy;
}
return resultEntropy;
}
/**
* 根据分裂属性,将可用分区进行分块
* @param splitAttribute 分裂属性
* @return 分块
*/
private int[][] splitData(int splitAttribute){
int tempNumValues=dataset.attribute(splitAttribute).numValues();
int[][] resultBlocks=new int[tempNumValues][];
int[] tempSize=new int[tempNumValues];
//step1.统计各个分块大小
int tempValue;
for (int i=0;i<availableInstances.length;i++){
tempValue = (int) dataset.instance(availableInstances[i]).value(splitAttribute);
tempSize[tempValue]++;
}
//step2.构建分块
for (int i=0;i<tempSize.length;i++){
resultBlocks[i]=new int[tempSize[i]];
}
//step3.分块赋值
//数组清零,作为计数器数组
Arrays.fill(tempSize,0);
//进行分区
System.out.println(splitAttribute);
for (int i = 0; i < availableInstances.length; i++) {
tempValue = (int) dataset.instance(availableInstances[i]).value(splitAttribute);
// 复制数据.
resultBlocks[tempValue][tempSize[tempValue]] = availableInstances[i];
//计数器+1
tempSize[tempValue]++;
}
return resultBlocks;
}
/**
* 递归构建决策树
*/
public void buildTree(){
//结束条件1.分区数据是纯的
if(pureJudge(availableInstances)){
return;
}
//结束条件2.分区数据数量小于等于最小分区大小,便不在分裂
if(availableInstances.length<=smallBlockThreshold){
return;
}
//step1.找出属性选择度量最大的属性作为分裂属性
splitAttribute=selectBestSplitAttribute();
//step2.根据分裂属性进行分区
int[][] tempSubBlock=splitData(splitAttribute);
//tempSubBlock.length==分裂属性取值范围
children=new ID3[tempSubBlock.length];
//step3.更新剩余属性
//顺序表元素的删除操作,将选择作为分裂属性的属性从可用属性列表中删除
int[] tempRemainAttributes=new int[availableAttribute.length-1];
for (int i=0;i<availableAttribute.length;i++){
if(availableAttribute[i]<splitAttribute){
tempRemainAttributes[i]=availableAttribute[i];
}else if(availableAttribute[i]>splitAttribute){
tempRemainAttributes[i-1]=availableAttribute[i];
}
}
//step4.构造子节点
for (int i=0;i<children.length;i++){
//分区为空则子节点也为空
if(tempSubBlock[i]==null || tempSubBlock[i].length==0){
children[i]=null;
continue;
}else {
//构造子节点
children[i]=new ID3(dataset,tempSubBlock[i],tempRemainAttributes);
//子节点递归建立子树
children[i].buildTree();
}
}
}
/**
* 使用决策树进行分类
* @param testInstance 欲分类的数据
* @return 分类结果标签
*/
public int classify(Instance testInstance){
if(children==null){
return defaultlabel;
}
ID3 tempChild=children[(int)testInstance.value(splitAttribute)];
if(tempChild==null){
return defaultlabel;
}
return tempChild.classify(testInstance);
}
/**
* 测试方法,测试输入数据集
* @param paraDataset 测试样本
* @return 测试准确率
*/
public double test(Instances paraDataset) {
double tempCorrect = 0;
for (int i = 0; i < paraDataset.numInstances(); i++) {
if (classify(paraDataset.instance(i)) == (int) paraDataset.instance(i).classValue()) {
tempCorrect++;
}
}
//计算准确度
return tempCorrect / paraDataset.numInstances();
}
/**
* 使用训练集作为测试样本,因为数据集本身太小了
* @return 分类准确度
*/
public double selfTest() {
return test(dataset);
}
/**
* 重写toString方法,方便输出决策树
* @return 对象字符串
*/
@Override
public String toString(){
String resultString="";
String tempAttributeName=dataset.attribute(splitAttribute).name();
String tempClass=dataset.classAttribute().value(defaultlabel);
if (children == null) {
resultString += "class = " + tempClass;
} else {
for (int i = 0; i < children.length; i++) {
if (children[i] == null) {
resultString += tempAttributeName + " = "
+ dataset.attribute(splitAttribute).value(i) + ":" + "class = " + tempClass
+ "\r\n";
} else {
resultString += tempAttributeName + " = "
+ dataset.attribute(splitAttribute).value(i) + ":" + children[i]
+ "\r\n";
}
}
}
return resultString;
}
public static void main(String[] args) {
ID3 testID3 = new ID3("E:\\DataSet\\weather.arff");
ID3.smallBlockThreshold = 3;
testID3.buildTree();
System.out.println("The tree is: \r\n" + testID3);
double tempAccuracy = testID3.selfTest();
System.out.println("The accuracy is: " + tempAccuracy);
}
}
文章出处登录后可见!