1.通过sklearn.model_selection.KFold所提供的一个小例子来进行理解交叉验证及应用交叉验证
2.
from sklearn.model_selection import KFold
import numpy as np
X = np.array(["a", "b", "c", "d", "e"])
# print(X[0],X[1],X[2],X[3],X[4],X[5])
# 设置其对折三次,这个变量至少为2
kf = KFold(n_splits=3)
i = 1
for train, test in kf.split(X):
print(i,"训练集:",X[train]," 测试集:",X[test])
i+=1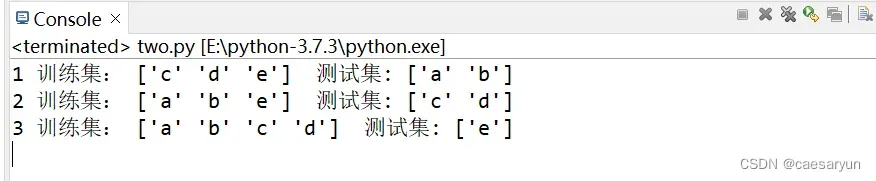
从输出可以看到,其每一次操作会从数组[a,b,c,d,e]中进行划分为两个集合,一个为训练集合,一个为测试集合,且进行三次折叠。得到这两个集合后,传入相关方法中进行训练和预测即可。
3.了解以上信息后,再看官方小例子便清晰了
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
kf.get_n_splits(X)
print(kf)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]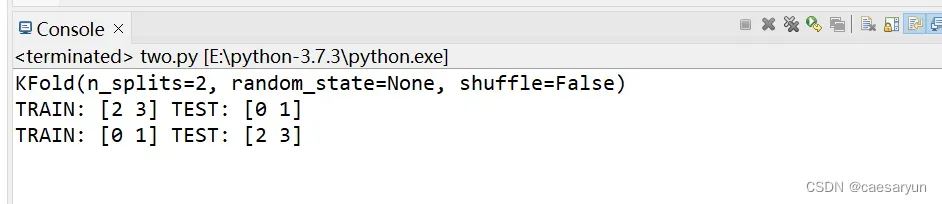
可以看到,训练集合测试集也被划分成成功了,且第一个训练集的数组下标为2和3,测试集的数组下标为0和1。之后通过划分到的下标,使用下标对应的数据来进行训练和预测即可。
文章出处登录后可见!
已经登录?立即刷新