误差反向传播是指,对于每次求出的Loss(损失),通过链式求导法则和梯度下降法,更新所有要学习的参数。
例如,对于线性模型:
其可训练的参数就是与
。
PyTorch提供了很好的基于计算图的误差反向传播机制,也就是当我们建立完各个参数之间的运算关系之后,一步backward(),就可以求出它对于所有require_grad = True的变量的偏导数,以方便进一步进行梯度下降(GD)运算。
注:PyTorch的两点反人类设计,一是默认不求偏导,requires_grad = True需要手动设置,二是梯度默认累积,需要手动清零。
一、自定义数据
x_data = [1.,2.,3.]
y_data = [3.,6.,9.]
#使用PyTorch,最好把所有数据预先转换成Tensor格式,方便处理
x_data,y_data = map(
torch.tensor,(x_data,y_data)
)
我们依旧用此数据,寻找最合适的。
二、初始化权重
权重初始化的方式很多,对于一个14*128的权重矩阵,我们可以这样定义。需要注意,dtype要说明为float类型,定义requires_grad = True.
w1 = torch.randn((14,128),dtype = float,requires_grad = True)
本例子中,只有一个,因此我们这样初始化该权重:
w = torch.tensor([10.],requires_grad = True)
需要注意,不要先将w设置为int类型,然后在设置其require_grad。应该在一句话中设置其为float类型的tensor,并设置requires_grad = True.
三、前向传播
#前向传播
def forward(x):
return x*w
四、定义损失函数(返回值为tensor变量,是的函数,即返回值可以对
求偏导)
#定义损失函数
def loss(x,y):
tot = sum((x-y)**2)
return tot/len(x)
五、梯度下降过程
**格外注意,每次使用完梯度后,要对该变量的梯度清零,否则梯度是累加的
for epoch in range(100):
e_l.append(epoch)
#1.计算预测值,y_pred是w的函数
y_pred = forward(x_data)
#2.计算损失值,由于y_pred是w的函数,ls也是w的函数
ls = loss(y_pred,y_data)
#注,只使用tensor变量的数值时,用item()
ls_l.append(ls.item())
#3.误差在计算图上依据链式法则反向传播
ls.backward()
w_l.append(w.item())
#4.梯度下降更新权值
w.data = w.data - 0.01*w.grad.data#只修改数值,则用.data,否则会生成额外的计算图
#梯度值清零,否则会累加
w.grad.zero_()
六、实验结果
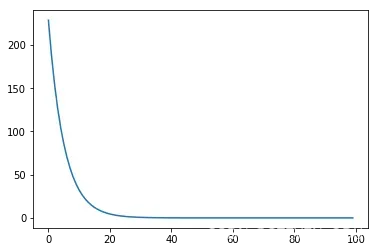
1、损失随epoch的变化
文章出处登录后可见!
已经登录?立即刷新