题记:
记录下自己论文中态势预测问题中,使用重标极差分析法对时间序列数据集进行可预测分析的过程。网上找到的相关R/S计算Hurst指数的代码,大多没有按照标准计算过程来实现,而相关论文中使用Hurst指数时,往往采用了对数散点图的方式来展示。
最终实现效果:
1、一般的重标极差分析法的计算过程

2、Python实现
水平有限,只是简单实现,没有采用矩阵等方式加速计算过程。
import numpy as np
import matplotlib.pyplot as plt
def my_hurst(obs: list) -> int:
"""
严格按照 R/S 标准流程推导
:param obs: 时间序列数据
:return: Hurst指数
"""
x_res = []
y_res = []
# 划分时间序列的间隔
step = 3
for n in range(step, len(obs), step):
x_res.append(np.log(n))
# 按长度n将时间序列分成子序列
sub_obs = []
for i in range(0, len(obs), n):
sub_obs.append(obs[i:i + n])
# 每个子序列的均值
sub_mean = []
# 计算每个子序列的标准差
sub_S = []
# 计算每个子序列的极差
sub_R = []
for sub in sub_obs:
# 每个子序列的累计离差
sub_cumulative_deviation = []
mean = sum(sub) / n
sub_mean.append(mean)
for i in range(n):
deviation = [x - mean for x in sub[:i]]
sub_cumulative_deviation.append(sum(deviation))
sub_R.append(max(sub_cumulative_deviation) - min(sub_cumulative_deviation))
# 离差平方
z = [(x - mean) ** 2 for x in sub]
sub_S.append(np.sqrt((sum(z) + 0.001) / n))
# 计算每组RS值
sub_RS = []
for i in range(len(sub_S)):
R = sub_R[i]
S = sub_S[i]
sub_RS.append(R / S)
# 计算重标极差
RS = sum(sub_RS) / len(sub_RS)
y_res.append(np.log(RS))
plt.xlabel("ln(n)")
plt.ylabel("ln(R/S)")
plt.xlim(1, 5) # 制定坐标轴范围大小
plt.ylim(0, 5)
# 拟合
h, b = np.polyfit(x_res, y_res, 1)
x = [0] + x_res + [5]
x = np.array(x)
y = h * x + b
plt.scatter(x_res, y_res, label='Hurst R/S')
if b > 0:
lable = "y = %.3f * x + %.3f" % (h, b)
else:
lable = "y = %.3f * x - %.3f" % (h, abs(b))
plt.plot(x, y, label=lable)
plt.legend(loc='best')
plt.show()
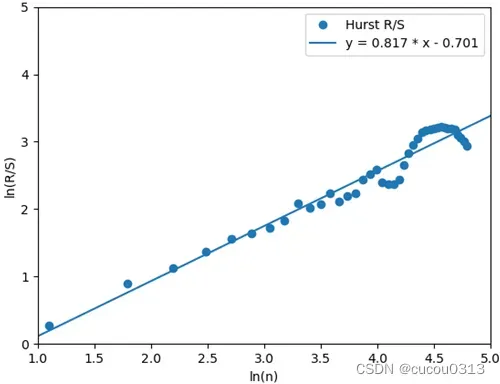
return h运行结果:
Hurst = 0.8170858515778376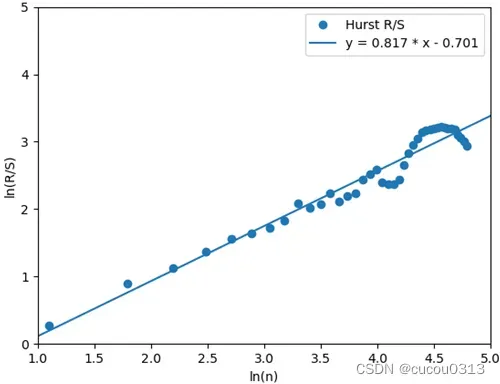
文章出处登录后可见!
已经登录?立即刷新