链接:https://arxiv.org/pdf/2004.05150.pdf
github:https://github.com/allenai/longformer
Abstract
由于自注意力机制,Transformer模型不能很好地处理长文本;为了处理这个问题,本文提出了Longformer,它的注意力机制是将局部注意力和任务驱动的全局注意力进行了结合。
Introduction
Transformers已经在NLP任务上取得了很好地进展,它的成功主要得益于自注意力能够捕获上下文的信息。但是它的内存和计算的代价和序列长度是二次方的,那么对于长文本的处理代价是比较大的。Longformer能够使得自注意机制和长度成正比(图1);通过实验分析,局部自注意用来构建上下文信息,全局用于构建预测完整的序列表示。
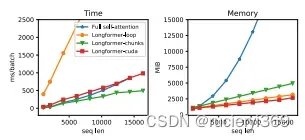
图1
长文本两类自注意机制方法:(1)left-to-right (ltr);(2)sparse。其中left-to-right是将长文本切成块,按照从左到右的方式处理,此方法对于需要双向信息的任务并不适用;sparse是减少自注意机制的计算。本文的方式属于第二种,此外Longformer需要定制化的cuda核。
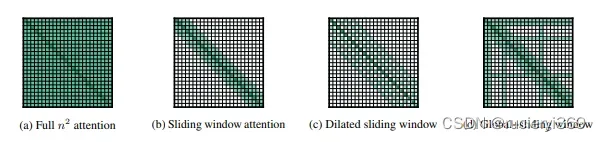
图2 各种注意机制
Model
窗口滑动(图2b)类似于CNN中的滑窗,对于给定的某一个token,选定固定大小的窗口k,与周围2k大小的tokens进行计算.
膨胀滑窗(图2c)为了增加感受域,类似于膨胀CNN,此操作能够获取成千上万的tokens。
上述的窗口滑动和膨胀滑窗对于特定任务的表示是不灵活的。为此,在预先指定的输入位置上增加了全局注意(图2d);它是将全局和局部的信息进行了融合。其中局部的参数是 ;全局的参数是
。
Experiment
LM
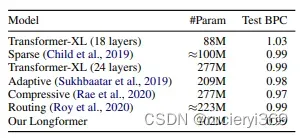
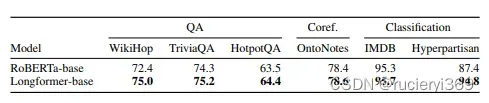
Document Classification
Conclusion
Longformer结合了局部和全局的注意机制并正比与序列长度。在长文本中预训练中,优于RoBERTa并在WikiHop和TriviaQA获得了更好的结果。
文章出处登录后可见!