前言
马上要找工作了,想总结下自己做过的几个小项目。
之前以及总结过了我做的第一个项目:xxx病虫害检测项目,github源码地址:HuKai97/FFSSD-ResNet。CSDN讲解地址:
- 【项目一、xxx病虫害检测项目】1、SSD原理和源码分析
- 【项目一、xxx病虫害检测项目】2、网络结构尝试改进:Resnet50、SE、CBAM、Feature Fusion
- 【项目一、xxx病虫害检测项目】3、损失函数尝试:Focal loss
而这篇主要介绍我做的第二个项目,也是实验室项目。这次是在YOLOv5的基础上进行的改进,同项目其他讲解:
如果对YOLOv5不熟悉的同学可以先看看我写的YOLOv5源码讲解CSDN:【YOLOV5-5.x 源码讲解】整体项目文件导航,注释版YOLOv5源码我也开源在了Github上:HuKai97/yolov5-5.x-annotations,欢迎大家star!
因为我的数据集相对简单,只需要检测单类别:蜂巢。所以在原始的YOLOv5的baseline上,mAP就已经达到了96%了,所以这篇工作主要是对YOLOv5进行轻量化探索,在保证mAP不下降太多的情况下,尽可能的提升速度,使模型能够部署在一些边缘设备上,如树莓派等。
改进的思路:利用ShuffleNetv2中的轻量化思路,改进YOLOv5s的网络结构,使网络更适合一些单类/几个类的数据集。
第一篇主要是介绍下ShuffleNet提出的背景,这就涉及到一些知识点,如:组卷积、深度可分离卷积、ResNeXt、Xception等,所以顺便就把一些重要的、面试常问的卷积模块/神经网络在这里总结一下。
代码已全部上传GitHub: HuKai97/YOLOv5-ShuffleNetv2,欢迎大家star!
一、InceptionV1-V4
【目的】Inception系列提出的初衷是为了解决CNN的两个问题:
- 如何使网络深度增加的同时性能也增加,而不会像vgg一样陷入性能饱和的困境;
- 如何保证网络性能提升的同时模型的计算开销和内存开销降低;
1.1、InceptionV1(GoogLeNet) – 2014
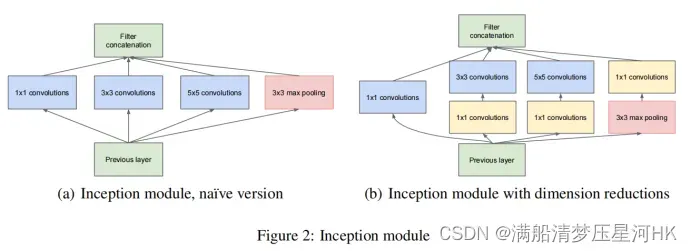
InceptionV1原始版本(左图):使用了一个1x1conv、3x3conv、5x5conv、3x3maxpooling并联的一个结构,实际上起到了图像金字塔的作用,可以融合不同尺度的特征信息,增强网络对尺度的适应性,增强表达;
InceptionV1改进版本(右图):在3x3conv、5×5卷积后面和3x3max pooling后面加一个1×1卷积,通过1×1卷积降低通道数,可以有效的减少参数量,并且同时使用ReLU激活函数,还能增加模型的非线性能力。
1.2、InceptionV2、InceptionV3 – 2015
v2改进点
- 卷积分解:将大尺度卷积分解为多个小尺度的卷积,感受野不变的同时还能减少参数、增强非线性能力。两个3x3Conv代替1各5x5conv;
- 使用非对称卷积代替对称卷积。1×3和3×1卷积代替3×3卷积;(在网络中间效果明显)
- 采用一种更高效的数据压缩方式,将池化和卷积并行执行再合并,保持特征表示并降低计算量;
V3改进点:整体上还是采用v2的网络结构,并在优化算法、正则化等方面作了改进:
- 将7×7分解成两个小卷积/非对称卷积,加速计算同时加深网络,提高非线性表达能力;
- 使用label smoothing对网络loss进行优化,防止过拟合;
- 在辅助分类器上加入BN;
- RMSProp优化器代替SGD
1.3、InceptionV4-2016
改进点
1、提出Inceptionv4结构,Inception在结构还是沿用v2/v3的形式,使用小卷积和非对称卷积,只是结构上更简洁,并使用更多的Inception module
2、结合残差结构,得到Inception-ResNet-v1,Inception-ResNet-v2
二、ResNetV1-V2、ResNeXt
2.1、ResNetV1-2015
1、问题/背景/ResNets为什么能构建如此深的网络?
随着网络的加深,很可能会发生梯度消失和梯度爆炸,传统的方法是使用数据初始化和BN来解决这个问题,虽然解决了梯度问题,但是随着网络的加深,会带来另一个问题-网络退化问题(不是过拟合),即随着网络深度的加深,网络性能反而在下降。
网络退化不是过拟合,过拟合是测试误差大而训练误差小,而网络退化是训练误差和测试误差都大。
为了解决上述问题,本文提出残差思想,用于解决这种退化问题,同时在一定程度上也缓解了梯度消失和梯度爆炸问题,提升网络的性能。
2、残差模块?
残差模块分为恒等映射和残差部分组成。残差部分有两种实现方式,一种是连接两个3x3conv,另一种是先1×1降维再3x3conv最后1×1升维(可以有效减少参数),最后将恒等映射和残差部分生成的特征图进行逐像素相加操作。通过这种前面层和后面层的”短路连接”,有助于训练过程中梯度的反向传播,抑制网络退化。
总共设计了两种残差模块,左边用于ResNet18/34,右边(bottlenecl)用于ResNet50/101/152,通过第一个1×1卷积先对特征进行降维,再3×3卷积,最后用一个1×1卷积进行升维,再进行残差连接,这么做主要目的是为了降低参数量和计算量,同时还可以引入更多的非线性。
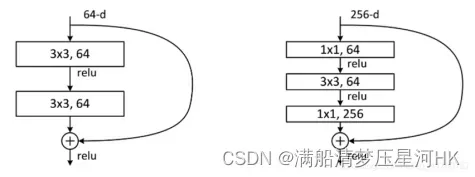
3、经过“shortcut connnection”后,f(x)和x的通道相同可以相加,但是如果通道不同呢?
- 通道相同,计算方式为H(x) = F(x) + x,直接相加
- 通道不相同,计算方式H(x) = F(x) + Wx,其中W是卷积操作,用来调整x的通道维度,调整到个F(x)的通道数相同,再相加
4、残差背后的原理?为什么残差会起作用?为什么残差可以解决网络退化问题?
在原有的认知里面,我们在构建一个模型的时候,理所当然的会认为网络越深效果会原来越好,因为假设一个较浅的网络已经表现不错了,那么即使再堆叠一些网络什么也不做,模型的效果也不会变差。但是事实上,”什么都不做,恰恰是神经网络最难做的事”。比如mobilenetv2里提到的,因为网络中一些非线性函数ReLU的存在,每层的输入到输出的过程几乎都是不可逆的,或多或少都会有一些信息损失。所以说,构建一个很深的网络,你让它什么都不做,信息一点都不损失的可能性很小。所以残差的初衷其实是让模型的内部至少有恒等映射的能力,确保在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化。
2.2、ResNetV2-2016
对残差结构进行深入的分析:Resnetv1残差模块采用的是后激活的结构,即:conv+bn+relu+conv+bn+add+relu
- 可不可以把relu放在add之前呢?如果这样,那么残差结构输出永远非负,这样前向传播输入会单调递增,会影响特征表达,我们希望残差分支输出应该在(-∞, +∞)
- 那可不可以把BN和Relu一起放在add之后呢?如果把BN放在add之后,那么就会改变恒等映射的分布,设计残差模块,增加identity分支的初衷:想通过identity的方式,直接将输入x传到输出作为初始结构传递到网络深层,这样起码能保证信息不丢失。
- 实验证明,当网络较深的时候,这种前激活的结构效果更有效,可以更好的收敛,泛化能力也更高。即:bn+relu+conv+bn+reul+conv+add的结构
2.2、ResNeXt
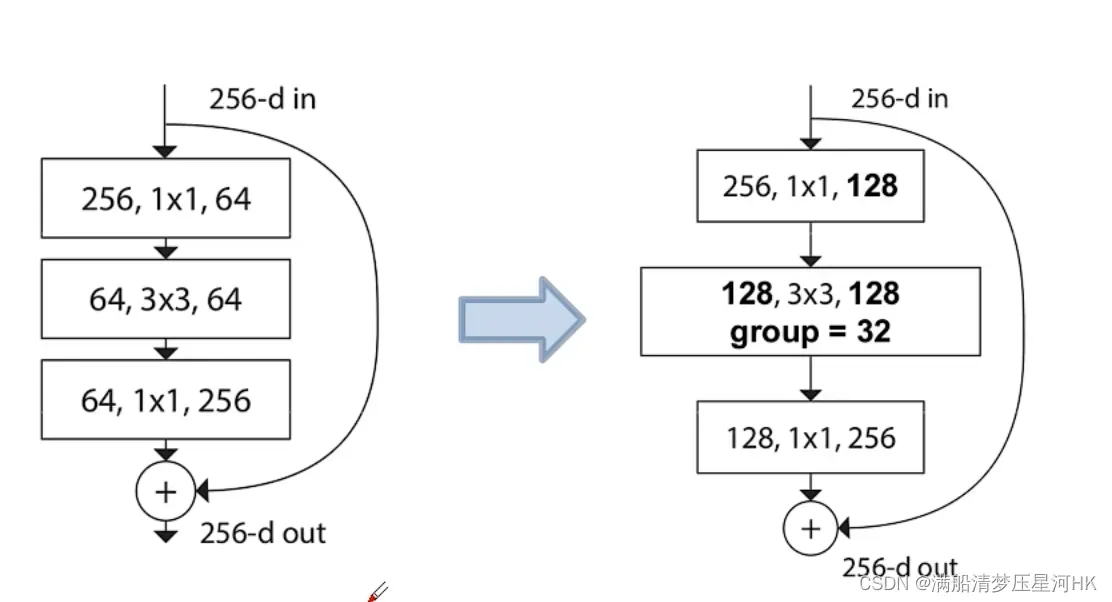
ResNeXt借鉴了Inception的拆分-变换-合并的思想,将输入拆分为很多条分支。同时为了避免复杂的超参和简化计算难度,每个分枝都设计了相同的拓扑结构。同时也简化了这个结构,如下右图所示,新分支和原始ResNet的bottleneck很相似,只是将中间的3×3卷积替换为了3×3组卷积。
三、DenseNet
【背景/动机+什么是densenet?】
一些工作如ResNet等证明建立从早期层到后期层的短路径或者说特征重用的方法有用,那么我就最大化这种前后层信息交流。即:每一层从前面所有层获得额外的输入,本身又作为这层后面所有层的输入,这样就将所有层直接连接起来。
结构:采用模块化的结构,网络由多个密集连接模板构成,同一个Dense Block中的特征图尺寸相同,方便进行特征重用concat,相邻两个Dense Block使用一个Transition层连接,包括BN、ReLU、1×1卷积、2×2平均池化层构成,1×1起到降维压缩模型参数的作用,2×2平均池化用于降低特征图的尺寸;
【ResNet与DenseNet的区别?】
- feature map的融合方式不同:Resnet是逐像素相加,DenseNet是Concat(DenseNet认为逐像素相加的方式可能阻碍了信息在网络中的流动能力);
- 特征重用的方式不同:Resnet是从前面某一层建立到这一层的信息通道,而DenseNet是将这种特征重用最大化,每一层从前面所有层获得额外的输入,本身又作为这层后面所有层的输入;
【优点】
- 密集连接的特殊网络,每一层都会接受其后所有层的梯度,一定程度上解决了梯度消失的问题;
- 虽然concat使大量特征重用,但是每一层独有的特征图是较少的,因此相比ResNet,DenseNet的参数更少;
【缺点】
- DenseNet需要进行多次concat操作,特征需要被复制很多次,比较耗显存;
- 应用上没有Resnet那么广,Resnet比较好做比较实验
四、MobileNetV1-V3
4.1、MobileNetV1-深度可分离卷积-2017
【深度可分离卷积】
由逐通道卷积+逐点卷积两部分组成
- 逐通道卷积:对输入特征图的每个通道单独进行卷积计算(特殊的分组卷积),没有利用到不同通道在相同空间位置上的特征信息,因此需要逐点卷积将生成的特征图进行逐像素卷积。
特点:卷积和channel=1 输入特征矩阵channel=卷积核个数=输出特征矩阵channel - 逐点卷积:本质上就是一个1×1卷积,通过升维和降维达到减少参数量和计算量的作用,增加网络的非线性能力,还能增强网络的跨通道交互能力。
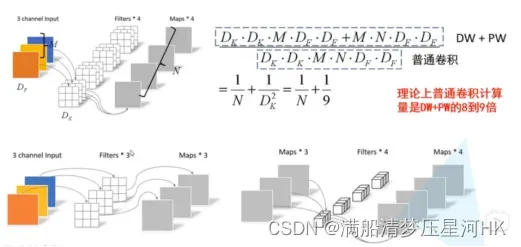
相当于实现了空间和通道之间的解耦,可以在基本不影响准确率的前提下大大减少参数量和计算量。
深度可分离卷积参数量= 理论上计算量是普通卷积的1/k^2 k为卷积和个数
k * k * Cin+1×1 * Cin * Cout ;FLOPs=2 * (1 * k * k) * Cin * H * W+2 * (1 * 1 * Cin) * Cout * H * W
4.2、MobileNetV2-2018
与v1的相同点:都采用DW卷积和PW卷积搭配的深度可分离卷积的方式提取特征。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。理论参数量是普通卷积的1/k^2,k为卷积核大小。
改进点/不同点:
- 在DW卷积之前增加一个PW卷积进行升维。这样就形成了一个倒残差的结构,先升维再降维。因为DW本身没有改变通道的能力,输入多少通道,输出还是多少通道。那么如果输入特征通道本身很少时,DW就只能在低维空间中提取特征,因此效果不够好。增加一个PW先升维,让DW在高维特征上提取特征效果会更好。
- 去掉了倒残差结构中第二个PW的激活函数。因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间中会破坏特征,不如线性的效果好。
- 激活函数使用ReLU6代替ReLU
V2和ResNet的区别与联系:
- 相同点:都使用了残差结构,都使用1×1->3×3->1×1的模式外加一个shortcut连接的残差结构,且最后一个1×1卷积后面都接的是线性激活函数;
- 不同点:ResNet使用的是普通卷积提取特征,而v2是使用DW卷积提取特征;ResNet使用的先降维卷积再升维的普通残差结构,而v2使用的是先升维卷积再降维的沙漏型倒残差结构;
4.3、MobileNetV3-2019
与v1和v2的联系:继承了v1的深度可分离卷积和v2的具有线性瓶颈的倒残差结构
改进:
- 在v2的基础模块上,提出了新的模块:bneck。主要改进点:添加了SE注意力模块,并重新设计非线性激活函数h-swish=x * ReLU6(x+3) / 6。
- 使用NAS搜索参数技术,得到v3网络结构
- 对NAS搜索得到的网络结构进行耗时分析,针对某些耗时结构进行优化:减少第一个卷积层的卷积和个数(32->16);精简Last Stage
五、ShuffleNetV1-V2
【组卷积】
输入输出通道被划分为多个组,每个组的输出通道只和对应组内的输入通道相连,和其他通道无关。
分组卷积参数量:k * k * Cin * Cout * (1/g) g = 分组个数
分组卷积计算量FLOPs=2 * k * k * Cin * Wout * Hout * Cout * (1/g)
优点:
- 降低参数量,参数量降为原来的1/g,g为分组个数;
- 提高训练效率,可以方便使用分布式资源进行分布式训练;
- 提高泛化能力,组卷积可以看作是普通卷积的一直耦合,改善常规卷积中滤波器的稀疏性,在一定程度上起到正则化作用;
ResNeXt结构:
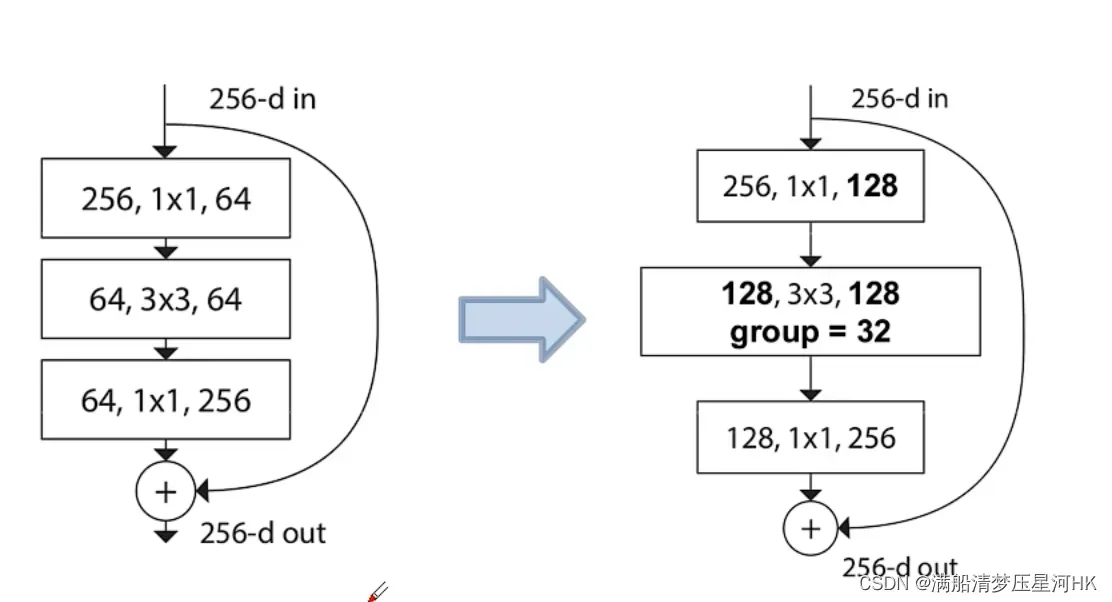
5.1、ShuffleNetV1-2018
ShuffleNet是在ResNeXt的基础上进行改进的。改进点:
- 作者通过实验发现,ResNeXt的基础模块中,主要的计算量都来源于前后的两个1×1卷积,所以这里将前后的两个1×1卷积全部换位1×1组卷积(g=3)。
- 组卷积虽然能减少参数和计算量,但是组卷积之间信息没有交流,可能导致输出的特征图的channel可能只和输入特征图的某些channel相关联,所以提出channel shuffle思想,在第一个1x1GConv后加入Channel shuffle模块。
具体做法:假设分组卷积g=3,对上一步分组卷积得到的输出feature map,对每个组再进行分组,分为g份(123,123,123),相应位置的信息进行拼接(channel shuffle)(111,222,333),得到新的特征图,再对重新分组的特征图进行组卷积,可以增强组卷积不同组间的信息交流。
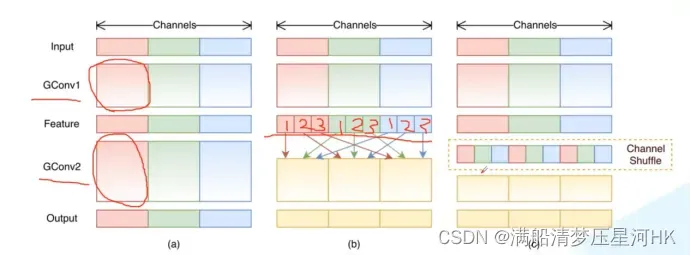
基础结构:
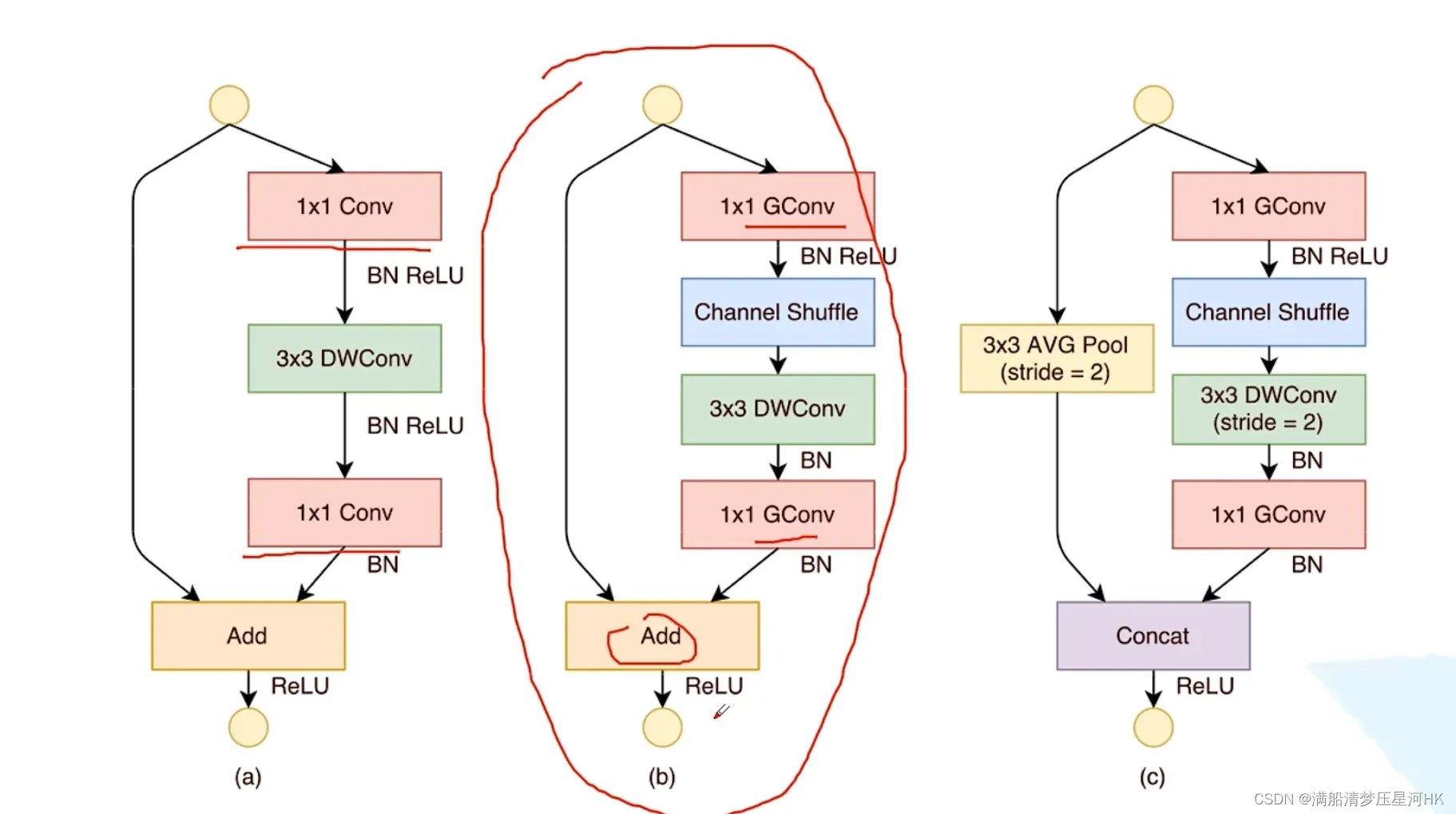
缺点:
- Channel Shuffle操作比较耗时,速度并没有理想中那么快
- Channel Shuffle的规则是人为制定的,参数难以设置
5.2、ShuffleNetV2-2018
FLOPS:每秒浮点运算次数,衡量硬件性能的一个指标。
FLOPs:浮点运算数,理论计算量。
MAC:memery access cost内存访问成本,FLOPs只是理论计算量,真实情况下还要考虑很多因素,比如MAC、并行操作等。
如何设计一个高效网络的四条建议:
- 卷积层的输入特征channel和输出特征channel相等时,MAC最小;
- 使用GConv时,grops越大,MAC越大;
- 网络的分支越多,速度越慢;
- Element-wise操作(如ReLU、ADD、逐点卷积)的MAC也比较大;
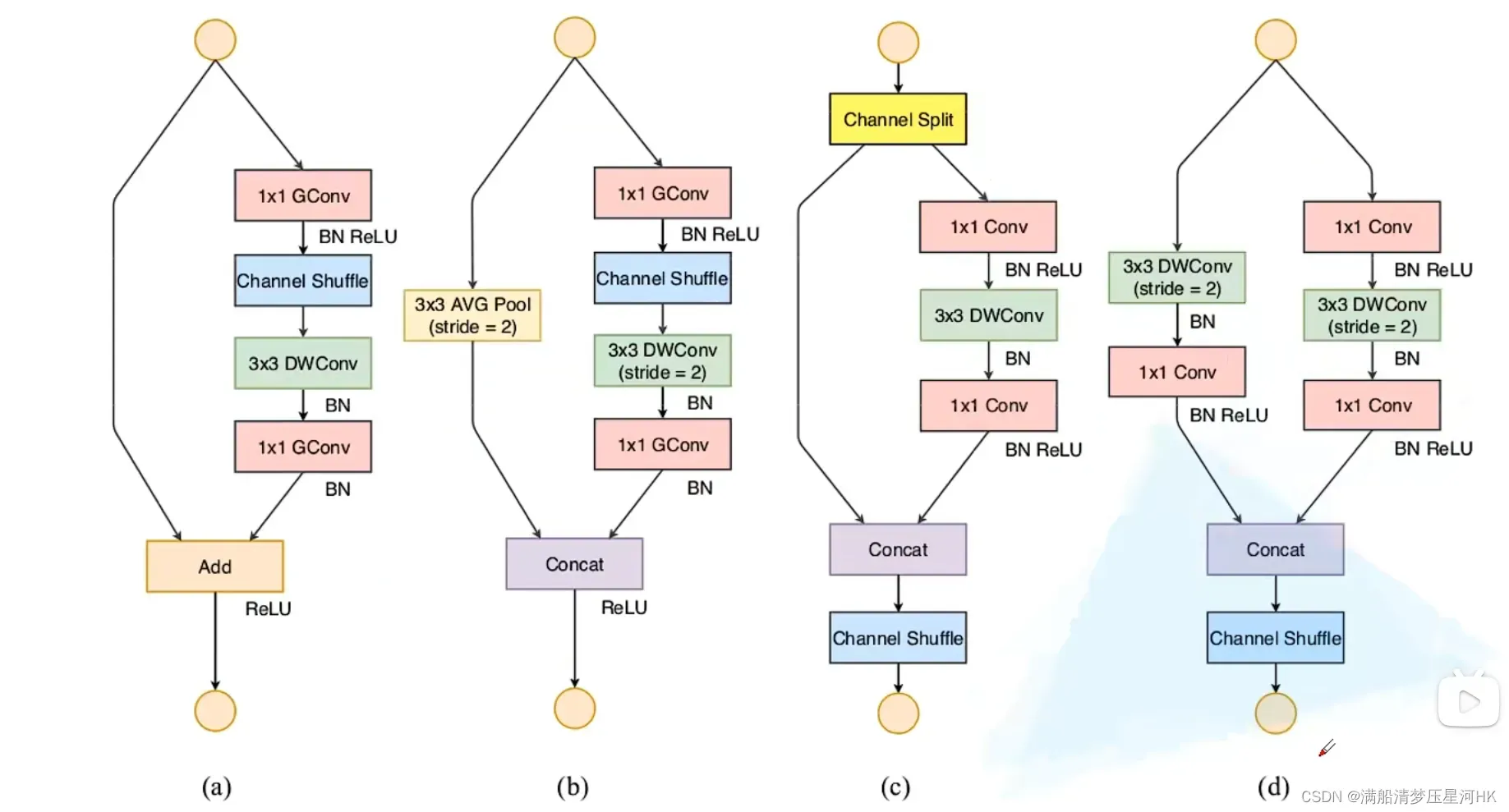
相比v1的基础模块改进点:
- 将输入特征splite成两个部分,且只对右分支进行ReLU,左分支不作任何操作,也就减少了ReLU的特征(G4)
- 将右侧的3个卷积的输入输出Channel相等(G1)
- 2个1×1组卷积改为2个1×1卷积(G2)
- 两个分支的结果的ADD拼接改为Concat拼接(G4)
Reference
文章出处登录后可见!