RGB-D Salient Object Detection with Cross-Modality Modulation and Selection
具有跨模态调制和选择的 RGB-D 显着目标检测
一、Motivation
two challenge:
1)如何有效地整合来自 RGB 图像及其对应的深度图的互补信息;
2)如何自适应地选择更多与显着性相关的特征。
二、Solutions
(1) cross-modality feature modulation (cmFM) 模块,通过将深度特征作为先验来增强RGB特征表示,所提出的调制设计通过特征转换实现了多模态信息的有效整合。
(2) adaptive feature selection (AFS) 模块,选择与显着性相关的特征并抑制劣质特征。 该模块突出了不同通道特征在自模态和跨模态中的重要性,同时以门控方式融合了多模态空间特征。
(3) saliency-guided position-edge attention (sg-PEA) 模块,强调与显着性相关的位置和边缘,该模块从预测的显着性图和显着性边缘图中收集其注意力权重。
上述模块作为一个整体,称为 cmMS 块,有助于以粗到细的方式细化显着性特征。再加上自下而上的推理,精细的显着性特征可实现准确且边缘保留的 SOD。
三、Methods
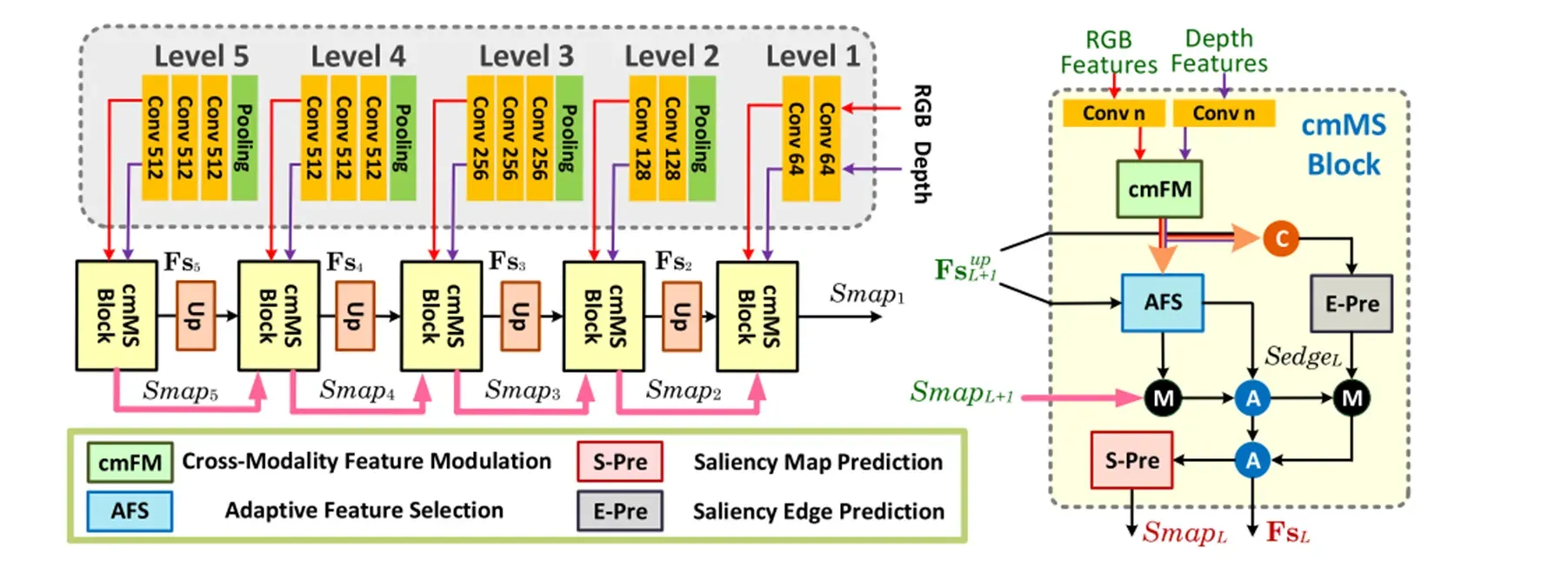
输入是RGB图像及其depth图。输入到VGG的5个 level 的 backbone 里面,将每个level的特征分别输入到cmMS(跨模态调制和选择)模块中来进行跨模态信息的融合以及调制和优化。同时,它是一个由低到高的形势下进行的多级串联,得到最终的预测结果。
cmMS模块由cmFM模块,AFS模块和sg-PEA模块组成。这里,sg-PEA模块还包含一个S-Pre和一个E-Pre。
首先,通过cmFM跨模态特征调制来融合跨模态特征调制,通过AFS自适应特征选择模块来选择出与显著性相关的特征来进行最终的预测。最后,通过S-pe和E-pe(位置和边缘)的显著性引导的注意力机制来细化强调准确定位和边缘,最终得到 level 的显著图。
‘Conv n’ 表示输出 n 个特征图的卷积层,其中 n 是输入特征图的一半(降维)。. “A”、“M”和“C”分别表示元素加法、元素乘法和连接以及通道维度。“Up”表示向上采样块。粉线表示 2× 线性插值。Fs 表示 cmMS 块之后的细化特征,而 Fsup 是Fs经过“Up”块的上采样结果。在这个图中,每个卷积层后面都是 ReLU 激活。我们的网络最终生成了 5 个显著性图(SmapL)和 5 个显著性边缘图(SedgeL),分辨率范围为 14×14 到 224×224,比例为 2。L 表示级别。我们将Smap1视为最终结果。
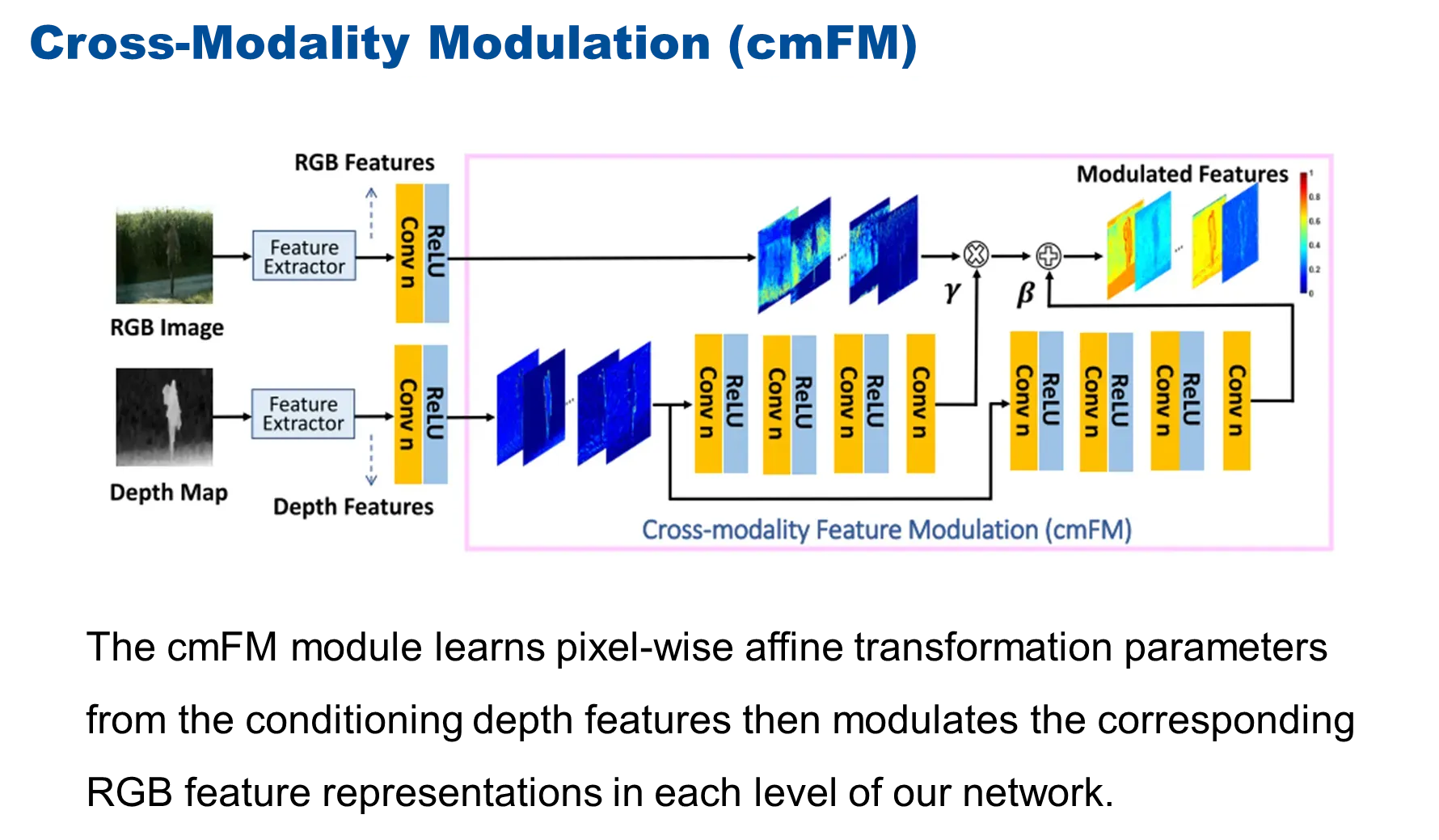
在传统的RGB 和 depth 的融合过程,一般情况下是通过级联或者是相加或者相乘的方式来简单的碱性融合。
在这篇论文中,对整个SOD任务来说,depth特征相对于RGB特征是辅助信息,作者希望通过depth的特征对RGB 特征进行增强,所以把depth 特征做成调制的形式来得到仿射变换的系数![]() 和
和![]() 来对RGB的特征进行增强。
来对RGB的特征进行增强。
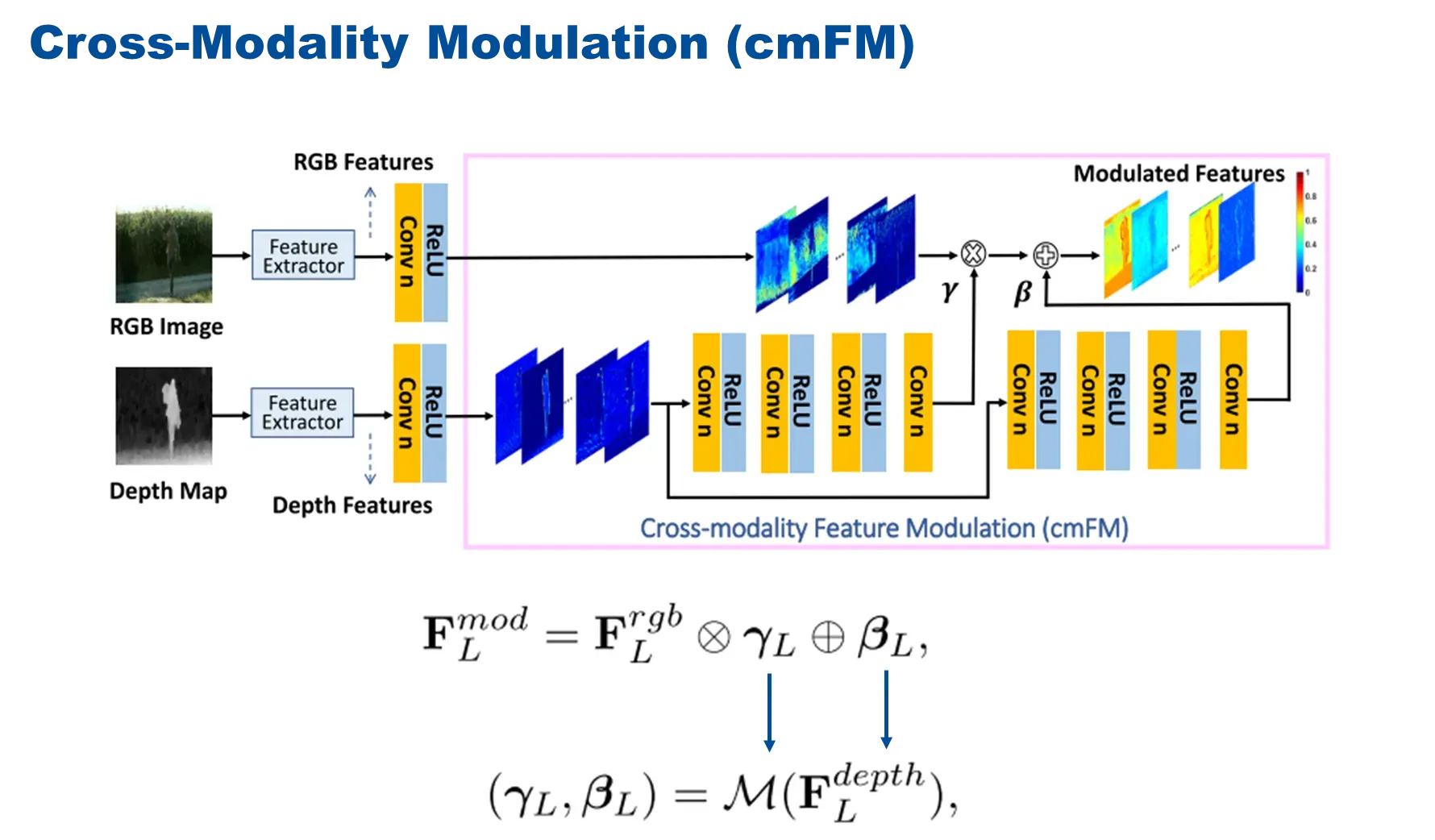
具体过程,把RGB和depth特征输入到cmFM模块中,然后depth学习M的映射,得到![]() 和
和![]()
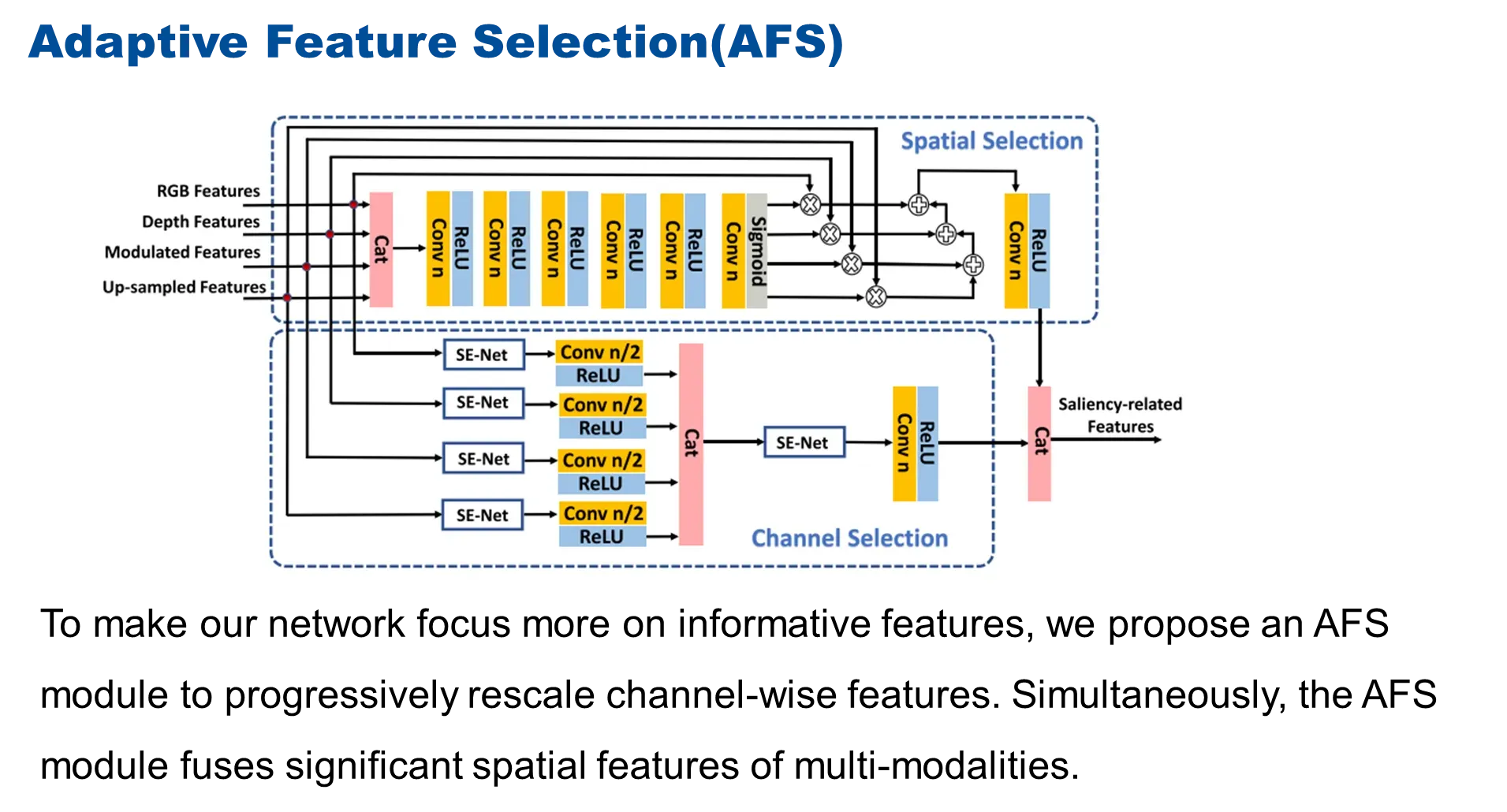
有了这样的一些特征之后,包括了RGB特征、depth特征、调制特征和上一级经过cmMS块最终输出的![]() (如果有)经过上采样的高层特征之后,这些特征之间,它们既存在相关性,但是它们也存在大量的冗余,如何去从这些大量的信息中去自适应选择出与显著性相关的特征对SOD任务来说是非常重要的。
(如果有)经过上采样的高层特征之后,这些特征之间,它们既存在相关性,但是它们也存在大量的冗余,如何去从这些大量的信息中去自适应选择出与显著性相关的特征对SOD任务来说是非常重要的。
作者就设计了这样的自适应选择模块,在这个部分中,主要包含了两个方面,一个是空间信息的选择,另一个是通道信息的选择。
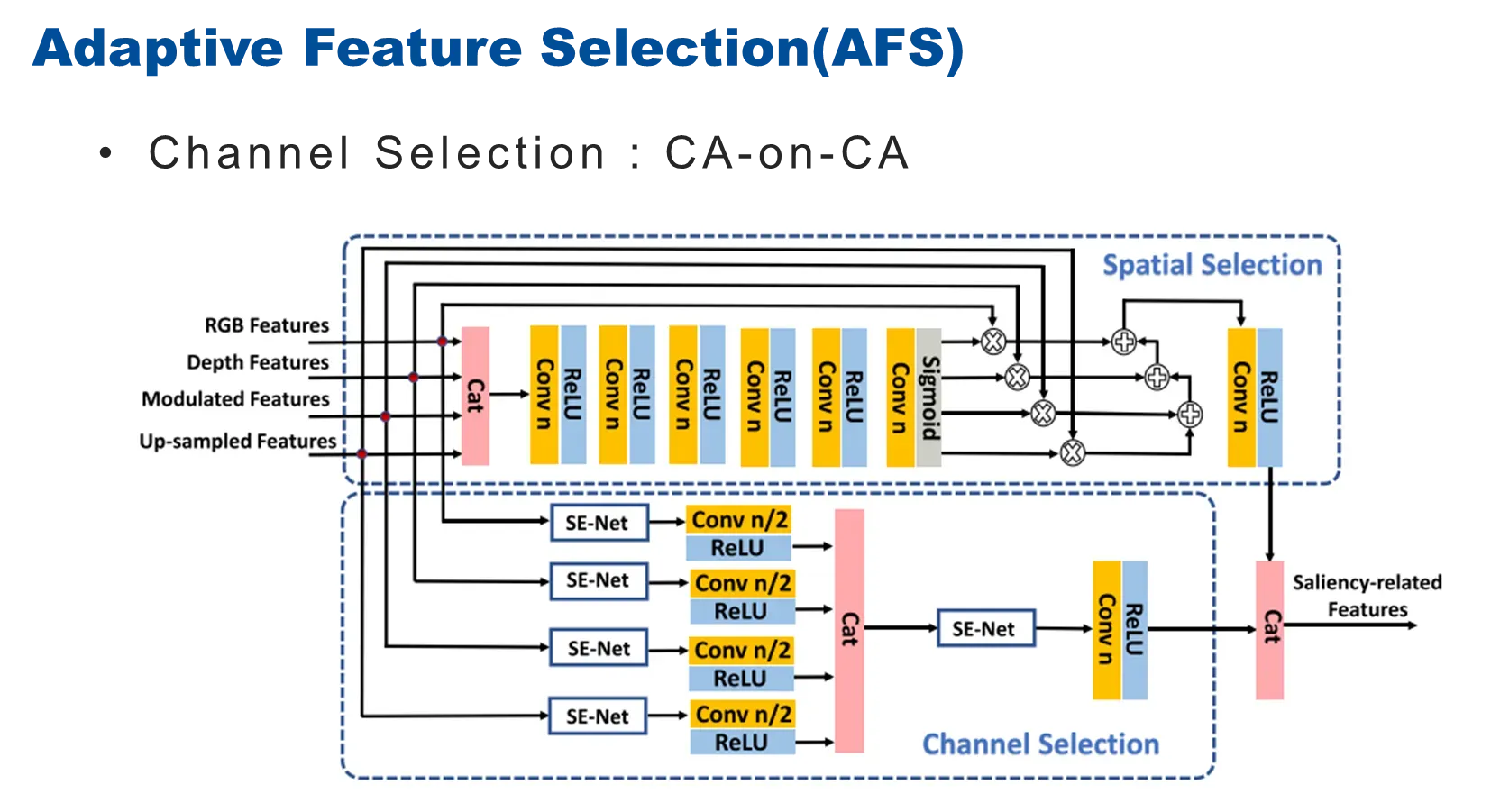
一开始输入的特征是包含很多模态的,在传统方法进行通道选择的时候通常可以采样一些通道注意力的方式,在本文中,作者构建了一种 channel attention on channel attention的一种形式,不仅需要建模输入特征的每一单模态上的通道之间的相互依赖关系,同时还希望这样的选择过程可以建模不同的跨模态之间的相关性,所以,首先,把不同模态的特征经过SE-Net网络提取通道注意力,然后将多个模态输出的特征进行级联,之后再经过注意力机制来进行多模态之间的通道之间的特征建模和提取,这样,就形成了人CA-on-CA的通道选择的部分。
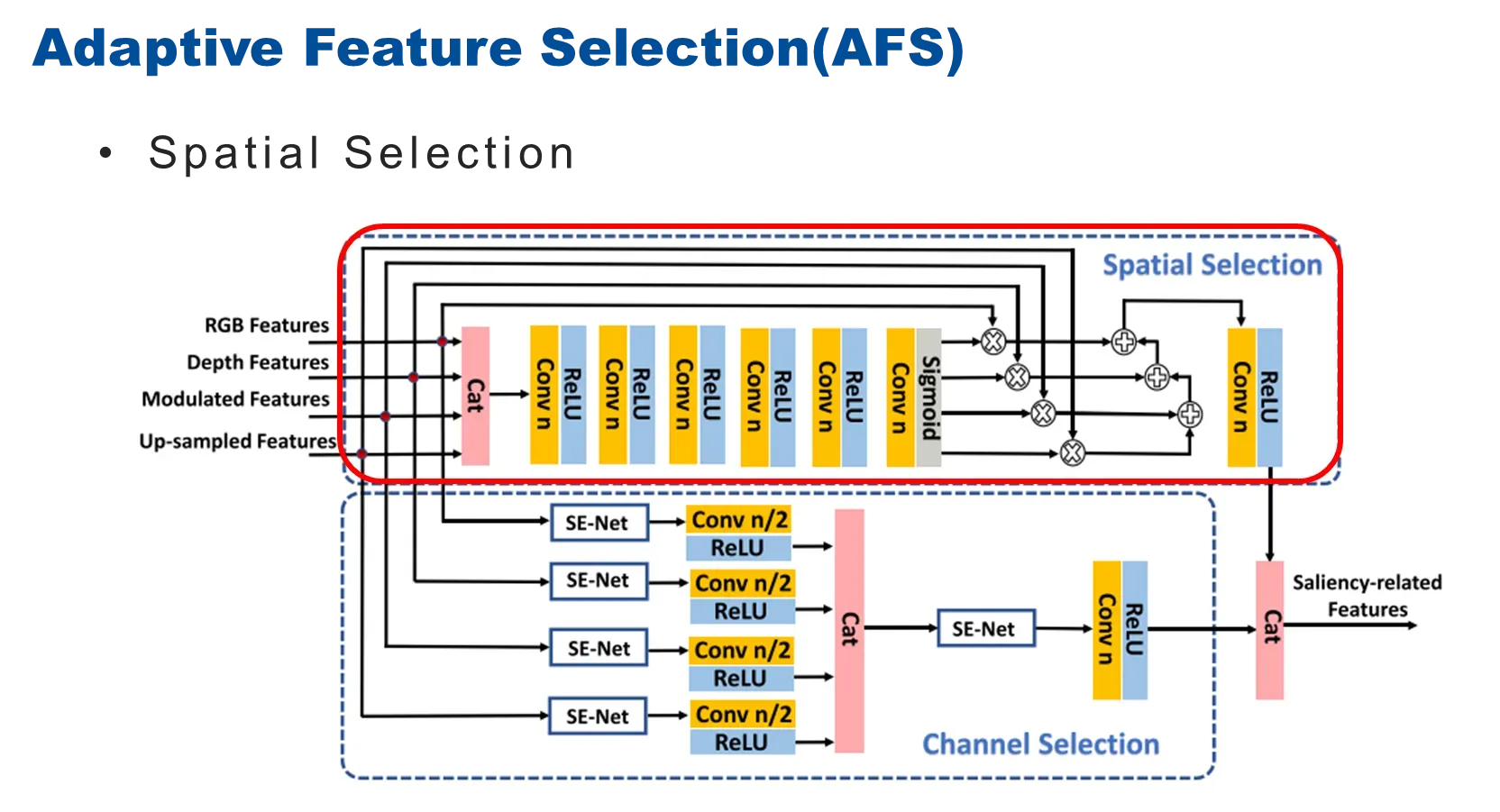
除了要选择有利的通道来进行SOD外,还需要保持空间特征的一些有效信息,所以提出了这样一种空间选择过程把它建模成一个门控注意力引导的多模态信息融合过程。首先把跨模态特征级联之后来学习像素级的权重,然后在权重的引导下,将不同模态的信息进行加权融合,来保留下更加反应显著性信息的特征。
最后将通道特征和空间特征进行级联之后,最终得到与显著相关的特征。
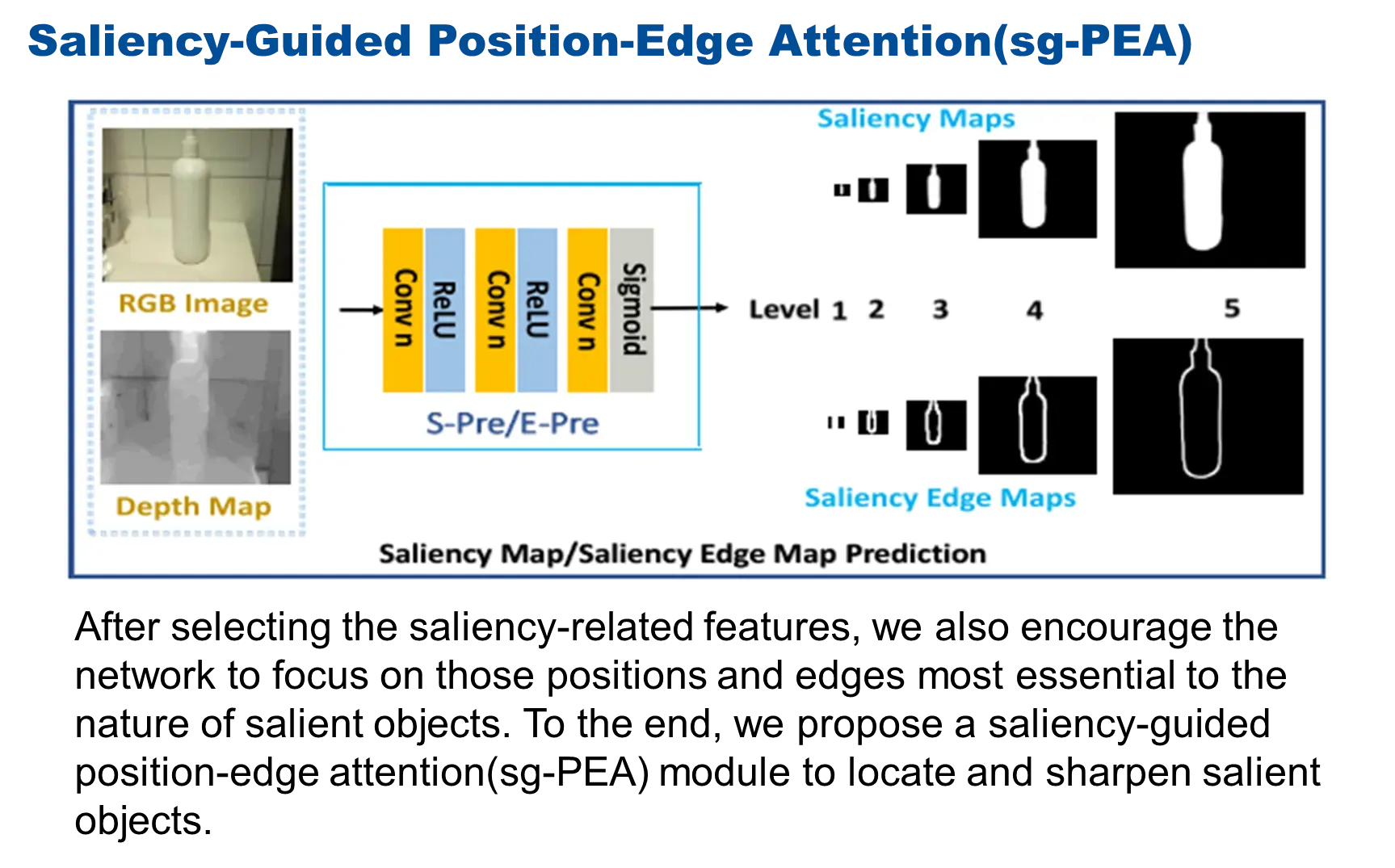
最后,有了这样一些特征之后,我们还需要约束网络能够精准的定位显著目标,同时预测结果具有比较清晰的形式,所以引入了一个显著性引导的位置和边缘的注意力模块,它们是共享相同的网络来约束生成更加完整的显著图和更加清晰的边缘图。
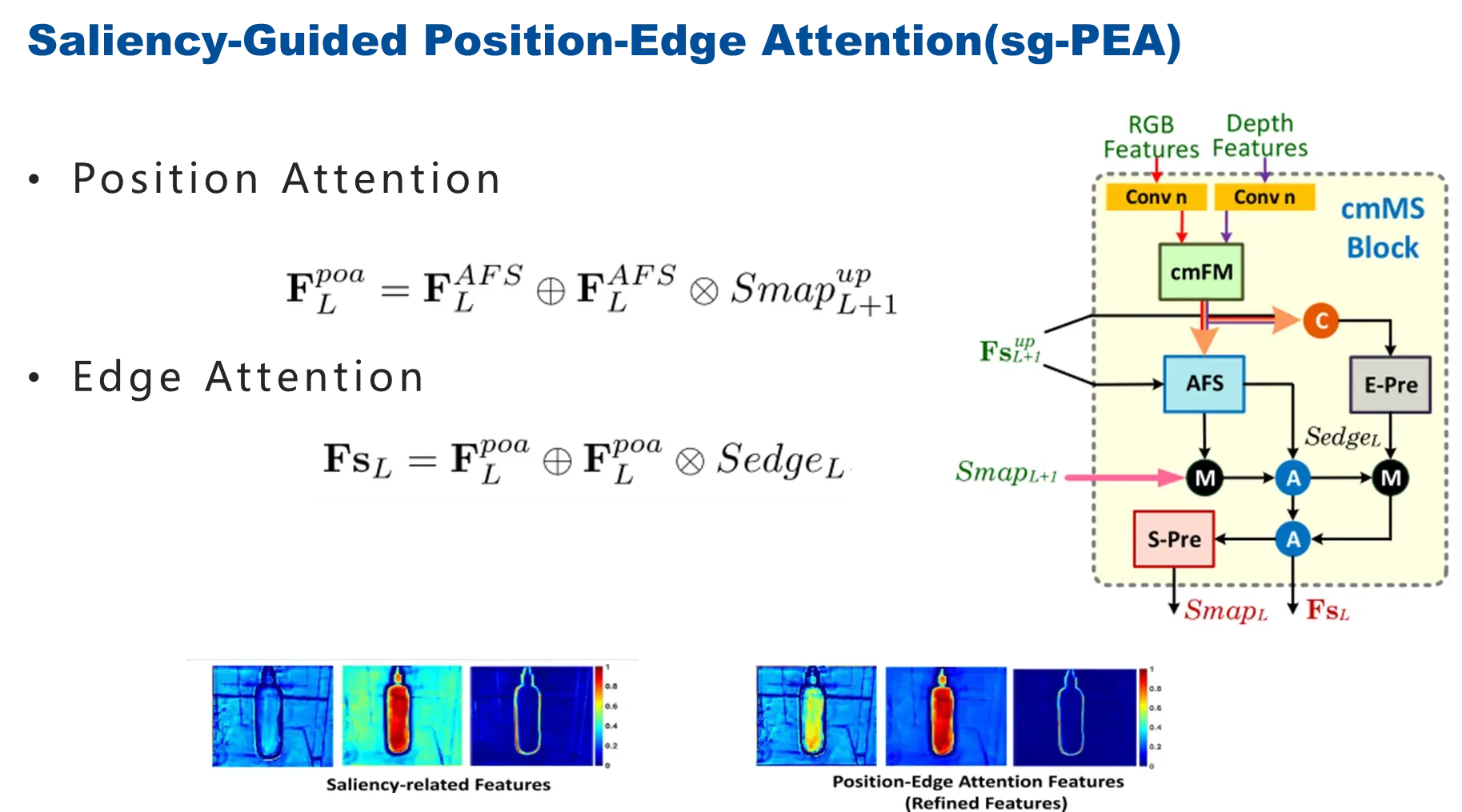
它的具体过程,首先把RGB特征、depth特征、调制特征和高级特征首先经过边缘预测过程(E-pre)得到SedgeL显著边缘图,之后把选择之后的特征利用上个level生成的saliency作为注意力的信息,对当前选择出来的AFS的输出进行修正,然后得到更加关注显著性目标的F^poa L 特征。
然后,再利用刚才生成的显著边缘特征SedgeL作为注意力的加权来对空间位置特征修正,得到用于显著性检测的F SL特征,最后,特征经过S-pre显著预测得到当前level最终显著图。
如上图,边缘信息和背景得到抑制。
文章出处登录后可见!