一、前言
今天在写神经网络里,使用minibatch抽取部分数据使用到了choice函数
二、函数讲解
1、choice()函数
老样子,先给大家上张官网的介绍
英文版:
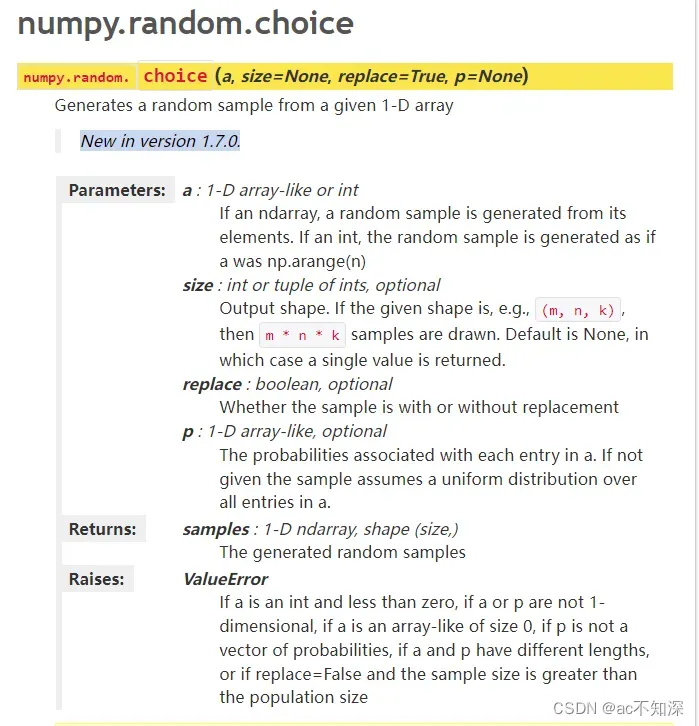
中文版:
choice(a, size=None, replace=True, p=None)
从给定的1维数组中生成随机样本
2、参数讲解
1) a
类型:一维数组或int整数
① 如果是数组的话
则从a的元素中生成随机的样本
import numpy as np
a = [1,5,3,0,2,6,9,8]
print(np.random.choice(a))
# 2 # 没有size参数,默认随机返回一个值
② 如果是int类型的话
用法和mp.arange(n)相同
import numpy as np
print(np.random.choice(5,3))
# [0 3 4] # 等同于np.arange((0,5),3),均匀随机样本(可能存在重复)
2)size(可选)
类型:int(例如1,2,3)或int型的元组(例如:(1,2,3) )
作用:影响返回值的形状
① 如果不填
默认返回一个随机样本
import numpy as np
a = [1,5,3,0,2,6,9,8]
print(np.random.choice(a))
# 2
② 如果填写(m,n,k)
返回m * n * k个样本(这里可以理解为(块,行,列),类似于我这篇文章里的permute函数)
import numpy as np
print(np.random.choice(a,size=(1,2)))
# [[2 3]] #1块1行2列
print(np.random.choice(a,size=(1,2,3)))
# [[[2 9 3] # 1块2行3列
# [6 5 3]]]
3)replace(可选)
类型:布尔类型(True/False)
作用:影响输出值是否存在重复情况
① 如果是True
输出值可能重复
print(np.random.choice(5,3,replace=True))
# [2 0 0] # 输出值可能重复
② 如果是Fasle
print(np.random.choice(5,3,replace=False))
# [1 4 0] # 输出值不会重复
4)p(可选,全称:probability)
类型:一维数组(同a)
作用:与 a 中的每个条目相关联的概率,默认为均匀分布
print(np.random.choice(5, 3, replace=False, p=[0.1, 0, 0.3, 0.6, 0]))
# [3 0 2]
5)返回值
类型:与size参数设定有关系,默认为一维的int或者数组
3、出错时可能的情况
- a 是 int 且小于零
- a 或 p 不是一维的
- a 是size= 0 的数组
- p 不是概率向量
- a 和 p 具有不同的长度
- replace=False 时并且样本数量大于总体
扩展
a除了一维数组和int整数类型
也可以吧一维数组中的数字替换成字符串
a = ['pooh', 'rabbit', 'piglet', 'Christopher']
print(np.random.choice(a, 3, p=[0.5, 0.1, 0.1, 0.3]))
# ['Christopher' 'Christopher' 'rabbit']
文章出处登录后可见!
已经登录?立即刷新