Transformer论文学习
摘要

*提出了一种新的简单的网络架构,Transformer,完全基于注意力机制,完全取消了递归和卷积。
*具有更强的并行性,并且需要的训练时间明显更少。
模型架构

Transformer遵循 encoder-decode结构
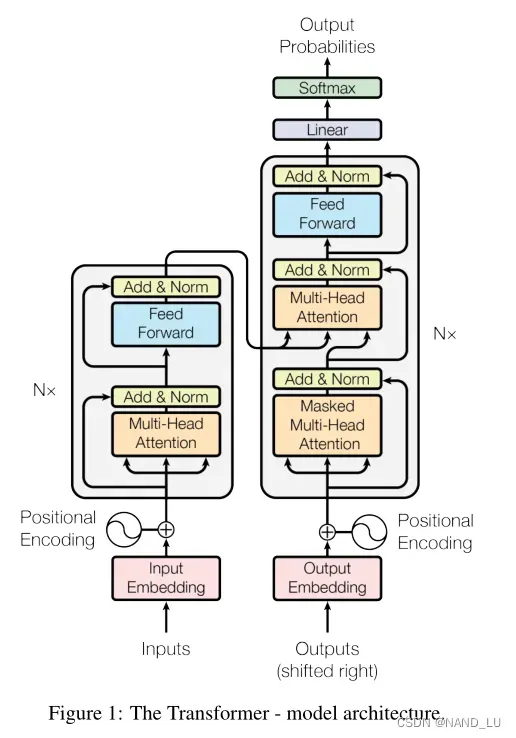
Encoder-Decoder
Encoder包括:
多头注意力机制->add残差结构-> layer normalization->Feed Forward network->add残差结构-> layer normalization
layer normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下
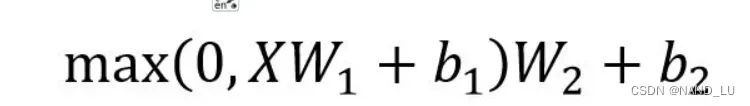
重复N次
Decoder比Encoder多了一个Masked多头注意力机制:
Masked多头注意力机制:->头注意力机制->add残差结构-> layer normalization->Feed Forward network->add残差结构-> layer normalization
重复N次
Attention

Scaled Dot-Product Attention比例点积注意力
注意力结构如图所示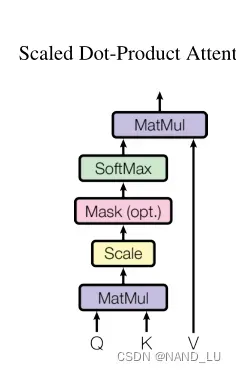
数学表达式

#三个向量,由输入input通过线性变换得到的
Q: query
K:key
V:value
#维度为
dk
#计算Q与所有K的点积,每个键除以√dk,并应用softmax函数来获得值的权重
首先由Q与K矩阵相乘(MatMul)=,再除以
,经过softmax函数
矩阵相乘后得到最后的结果。
当dk值较大时,点积会增大,将softmax函数推入梯度极小的区域。我们将点积乘以1√dk抵消梯度消失的风险。
当Q、K、V为矩阵的时候将体现出点积注意力的优势
![]()
![]()
![]()
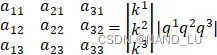
Multi-Head Attention多头注意力机制
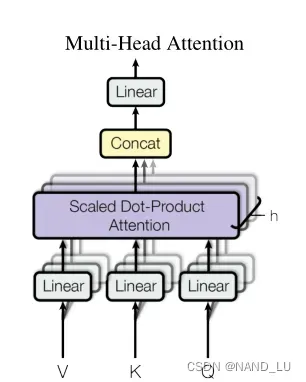

V、K、Q进行线性变换后得到多维v、k、q,再对各维v、k、q分别进行比例点积。将得到的值再次Concat后进行线性变化得到的最终结果比直接使用V、K、Q效果好。W为矩阵。
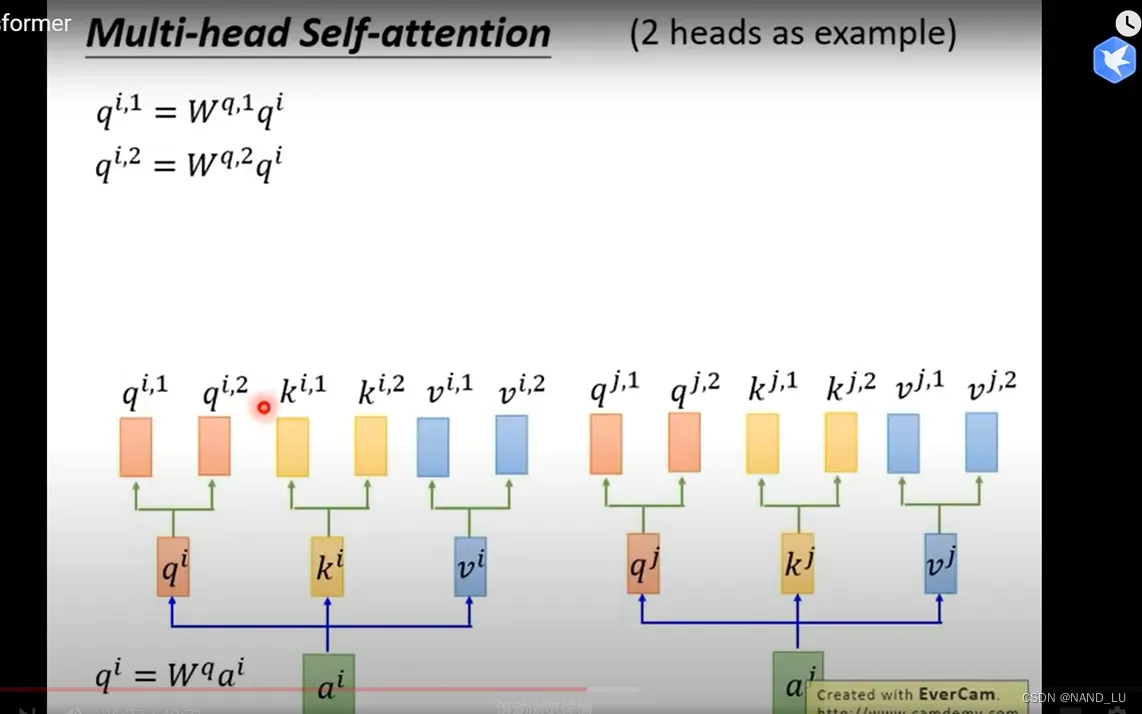
 Mask Multi-Head Attention
Mask Multi-Head Attention
Mask是一个矩阵。Mask存在的意义就是为了防止为出现的词汇对前面的词汇造成信息干扰。
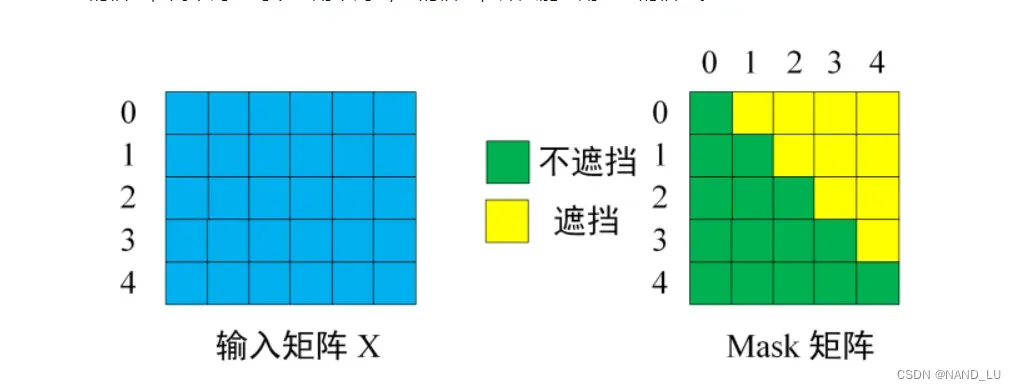
比如当encoder输入0,1,2,3,4的时候,decoder在学习0的时候需要把1234的信息全部遮挡住学习1,的时候,需要把2,3,4的信息全部遮挡住。因为后面的信息是由前面的信息推到出来的,后面的信息不能对前面的信息进行干扰,这就是所谓的防止信息左移

Position Embedding
ransformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。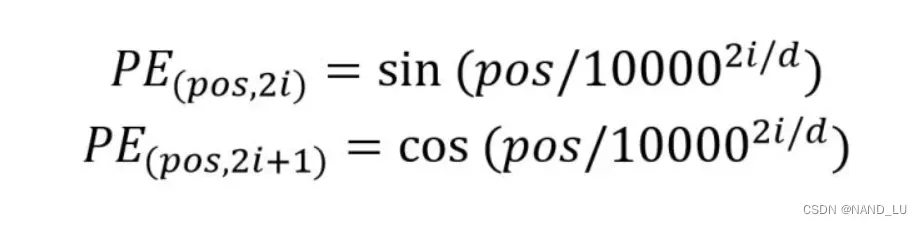
位置编码需要满足以下准则。
- 每个位置的编码值应该是唯一的。
- 相邻位置的编码值的差应该是保持不变的,无论句子有多长。
- 编码方法要能轻松泛化到更长的句子。
- 编码方式必须是确定的。

参考
文章出处登录后可见!