简单来说就是在Few-shot Learning问题中加入了跨域问题,具体表现在:在一个数据集上进行Few-shot训练,完成后在另一个数据集Few-shot测试,两个数据集中没有相同的类别。
Universal Representation Learning from Multiple Domains for Few-shot Classification (ICCV2021)
问题: 现有解决方案首先会在多个数据集分别训练特征提取器,随后在测试阶段筛选或者融合来自不同提取器的特征,如下图(a)所示,但是针对小样本场景中样本少的问题导致筛选、融合过程难以实现。
创新点: 本文使用对多个特征提取器进行知识蒸馏,从而避免了测试过程中的筛选、融合步骤,下图(b)所示。
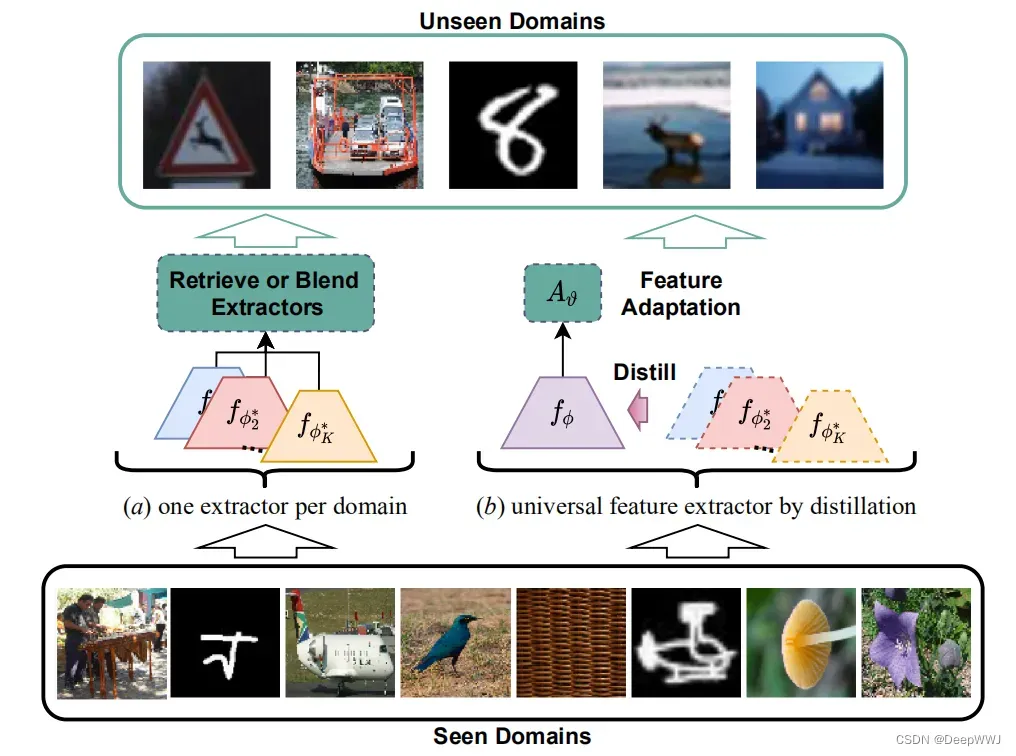
具体框架图:

- 第一阶段,首先在每个域训练对应的特征提取器
域分类器
- 第二阶段,将所有的
冻结,然后使用知识蒸馏来学习
2.1 特征约束: 在知识蒸馏阶段,每个域图像分别进入各自的特征提取器,并进入
。
进行线性变换。最后使用CKA (一种骚距离度量) 对
2.2 结果约束:中得到分类结果,
的输出输入到冻结的
得到分类结果,计算两种结果的KL损失。
- 两种约束能够在不同层面上帮助网络进行知识蒸馏,在测试阶段使用
,最后参考Few-shot分类范式,使用
Cross-domain Few-shot Learning with Task-specific Adapters (CVPR2022)
跟上一篇出自同一个团队 (很专注) 。
创新点: 去除了迁移过程中繁琐的adapter步骤,将task adaptation依附在训练过程中,在训练过程中完成适配。
具体框架:
-
在ImageNet上训练得到特征提取器
-
support-set中,在冻结的
,具体是加入各种变换。将经过这些变换后得到的特征输入到分类器
中进行分类。
-
超级总结: 在冻结的特征提取器
卷积,并最后一层再加入线性变换器
。这些简单的操作,再Few-shot setting下就有了神奇的魔力。因为Few-shot是基于episodes训练的,所以训练过程中这些
跨域数据集
多源域自适应矩阵匹配:Moment Matching for Multi-Source Domain Adaptation,ICCV2019
收集并注释了迄今为止最大的UDA数据集DomainNet,存在显著的领域差距和大量的类别,它包含6个域和分布在345个类别中的约60万幅图像。

Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples(ICLR )
相较于上一篇,数据集是按领域来划分,即数据集间没有类别交叉

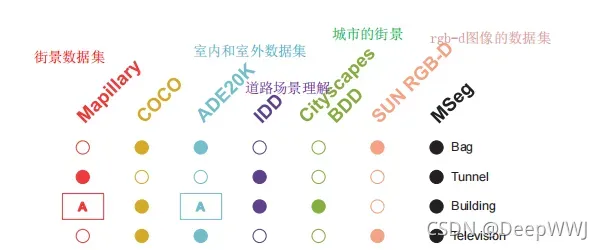
MSeg: A Composite Dataset for Multi-domain Semantic Segmentation
综合好几个分割数据集(多数为街景)为一个大的数据集,将类别进行了更加精细的处理。
文章出处登录后可见!