上一期中,ofter介绍了计算机视觉的常用神经网络模型,以及如何选择模型,今天我们就趁热打铁拿个实际的模型跑跑,欢迎大家跨入数据科学家们的世界。

一、机器学习的目标
作为数据科学家,我们必须明白投入大量时间精力进行机器学习、深度学习的目的是什么?将非结构化、低密度、低价值的大数据转换为高密度和高价值数据。当我们对张三发布的某张照片进行内容识别的时候,这张照片就是非结构化、低密度、低价值的数据;但是当我们对他多年发布的N张照片进行内容识别后,我们大概率可以分析得出张三的生活习惯、爱好、朋友圈等等。

二、机器学习的步骤
- 确定需要使用的框架、预训练模型、编程语言;
- 准备需要训练的数据集;
- 预处理数据;
- 构建模型;
- 训练模型;
- 使用训练好的模型。
三、图像检测实战应用
数据科学家的主要任务是使用正确或表现良好的模型进行数据分析的实际应用。因此,今天ofter以图像检测为例,使用训练好的模型测试下检测效率和效果。本案例使用的框架Tensorflow+Keras,训练好的模型RetinaNet,编程语言python。其中,训练好的模型,大家可以从modelzoo中或其他途径搜索https://modelzoo.co/

3.1 引用所需模块
看上图,我们可以知道需要对识别的图片绘制边框和打印识别标签,因此,除了引用keras_retinanet模型模块以外,我们还需要引用可视化绘制图表、绘制边框、打标签、设置标签颜色的模块。
from keras_retinanet import models
from keras_retinanet.utils.image import read_image_bgr, preprocess_image, resize_image
from keras_retinanet.utils.visualization import draw_box, draw_caption
from keras_retinanet.utils.colors import label_color
import matplotlib.pyplot as plt
import cv2
import os
import numpy as np
import time
import sys
sys.path.insert(0, '../')3.2 加载RetinaNet模型
# 加载已经训练好的retinanet模型
model_path = os.path.join('..', 'snapshots', 'resnet50_coco_best_v2.1.0.h5')
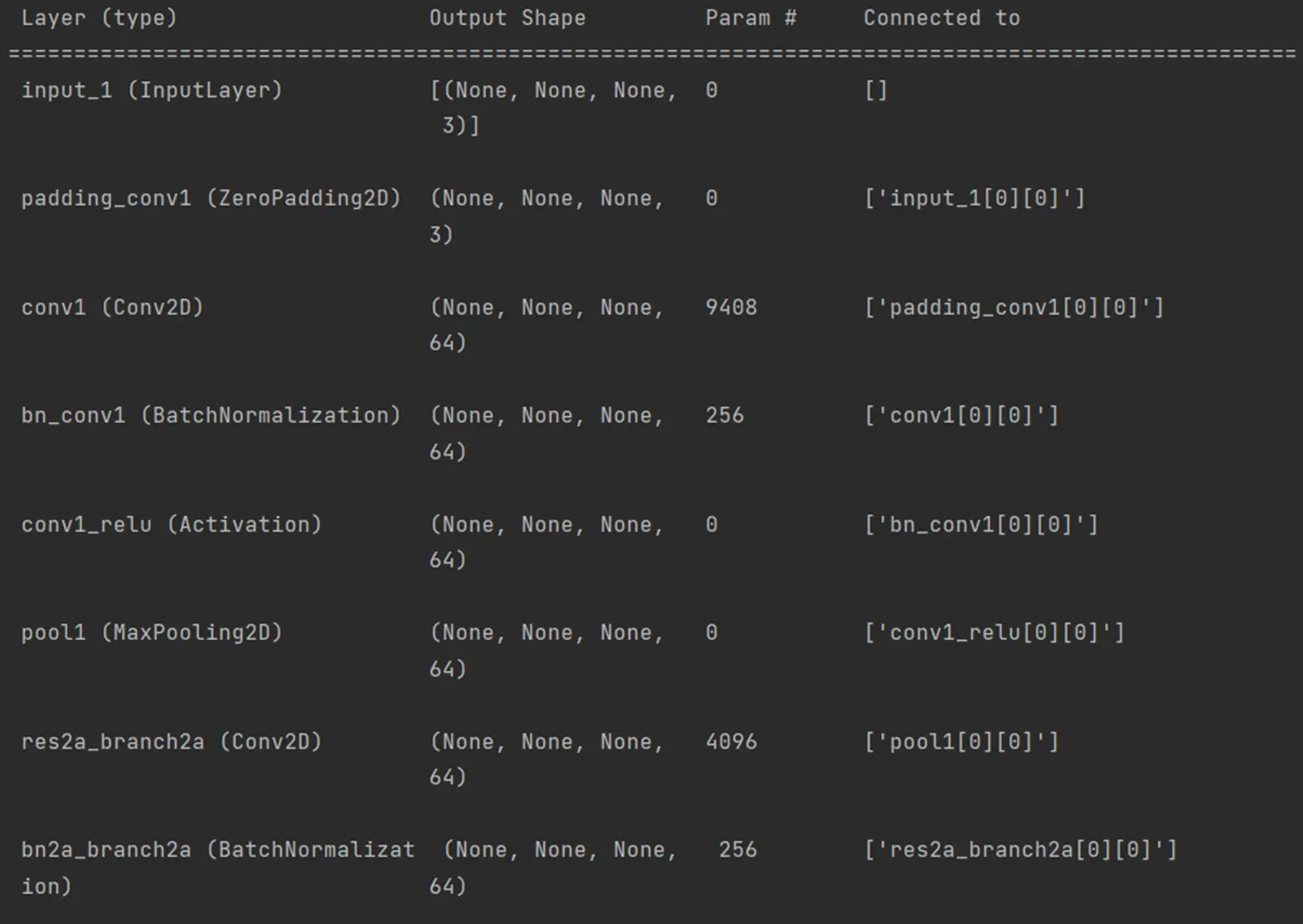
model = models.load_model(model_path, backbone_name='resnet50')
print(model.summary())
# 标签名称映射
labels_to_names = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}其中
resnet50_coco_best_v2.1.0.h5是已经训练过数据集的文件。当我们加载模型时,可以看下该模型的网络结构。
3.3 图像识别代码
# 测试图片
image = read_image_bgr('house.png')
# 图片转换为RGB格式
draw = image.copy()
draw = cv2.cvtColor(draw, cv2.COLOR_BGR2RGB)
# 预处理图片
image = preprocess_image(image)
image, scale = resize_image(image)
# 处理图片
start = time.time()
boxes, scores, labels = model.predict_on_batch(np.expand_dims(image, axis=0))
# 输出图片处理时间
print("processing time: ", time.time() - start)
# 纠正图片比例
boxes /= scale
# 实例检测
for box, score, label in zip(boxes[0], scores[0], labels[0]):
if score < 0.5:
break
color = label_color(label)
b = box.astype(int)
draw_box(draw, b, color=color)
caption = "{} {:.3f}".format(labels_to_names[label], score)
draw_caption(draw, b, caption)
# 输出图片识别结果
plt.figure(figsize=(15, 15))
plt.axis('off')
plt.imshow(draw)
plt.show()原图:

检测后:
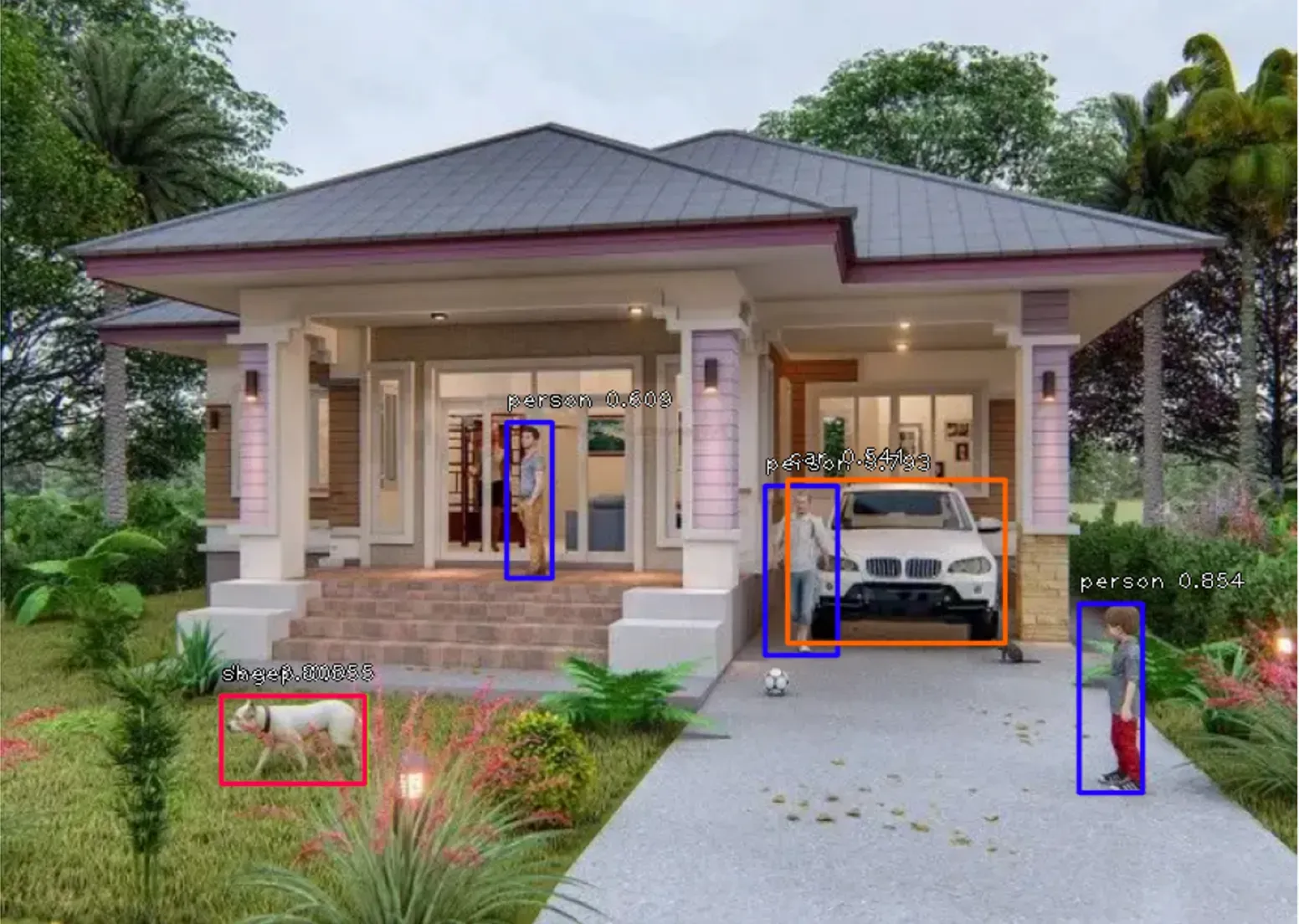
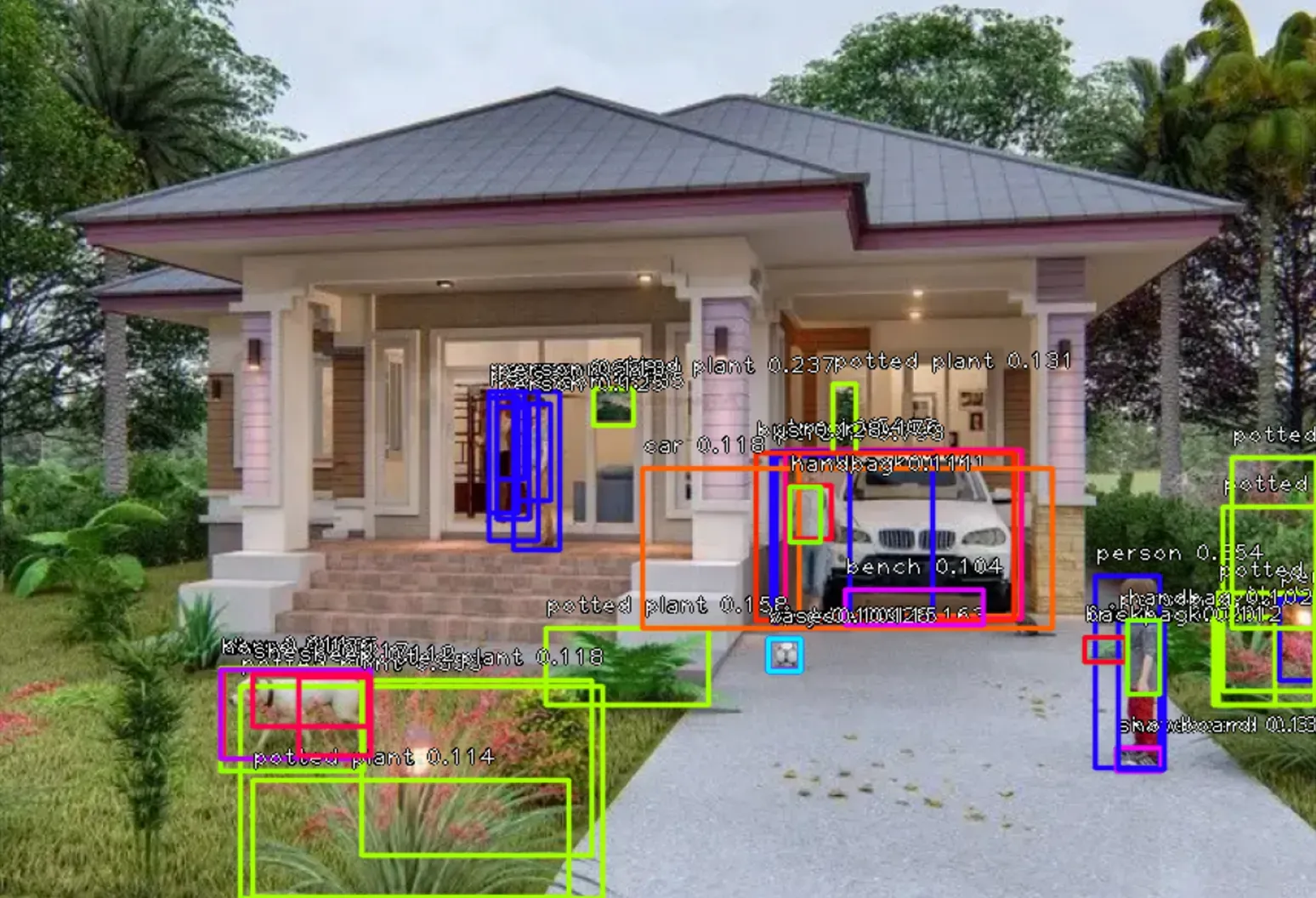
一般,我们会对识别分score<0.5的进行剔除,当然,我们也可以提高识别分,或者降低识别分,比如降低到score<0.1的剔除,那么识别的内容会有更多的可能性。
四、完整的机器学习
当然,如果你想要学习完整的机器学习步骤,ofter推荐一个网址:
https://tensorflow.google.cn/tutorials/keras/classification?hl=zh-cn
本案例的代码下载地址:
https://github.com/fizyr/keras-retinanet
文章出处登录后可见!