

Title: TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing
Paper: https://arxiv.org/abs/2203.10489
Code: https://github.com/JierunChen/TVConv
医学图像分割的一篇论文,数据集都没见过。主要提出了个对空间Dynamic,对数据却Static的,动态又感觉不那么动态的动态卷积。用了一个Affinity Map喂给Weight Genrate模块来生成权重,这个过程类似非线性的矩阵分解。Affinity Map是包含了该数据集图片的一定共性的,比如鼻子眼睛在上嘴巴在下,因此能够很好地提取不同空间位置的信息。
不过我好奇的是,当从人脸识别和工业检测转向ImagNet这种1000多类的数据集,Affinity Map这种机制能否保持有效。
引文整理
Per-pixel动态卷积: TVConv引文整理-Per-pixel动态卷积
Per-image动态卷积: TVConv引文整理-Per-image动态卷积
Motivation
TE问题
translation equivariance转换等变性,这是一个很不错的特性。 将卷积操作展开为矩阵乘法,很容易观察到对于输入,变换矩阵是在不同空间位置共享卷积核参数的(稍有变化,以移位和补零的方式)。但是TE也使得模型适应不同位置输入的能力变差了,对于specific layout,就需要学习非常多的卷积核来匹配特征。
两种方差
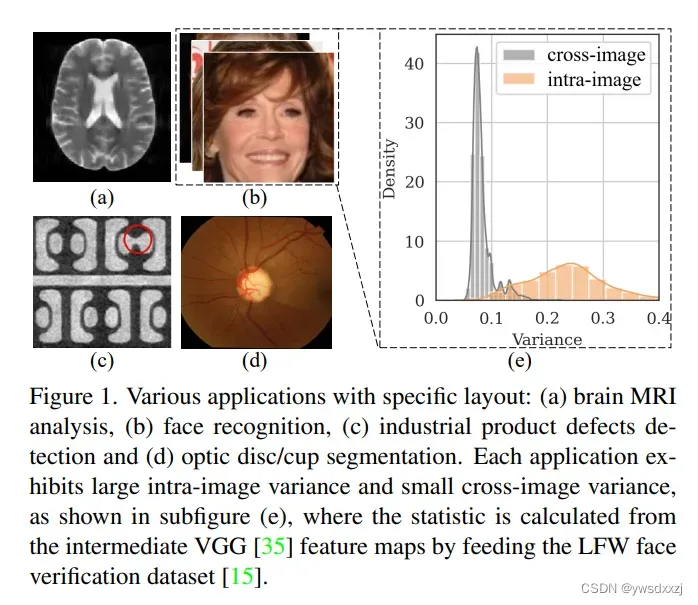
对于layout-specific tasks,比如人脸识别,所有图片都遵循类似的模式,然而每张图片空间上的差异极大。文章称之为large intra-image (spatial) variance and small cross-image variance。这一点,给出了VGG中间层特征的统计量作为证明(Fig1)。
所以,有些工作为了解决large intra-image variance,在per-image上提出了per-pixel的动态卷积——但实际上并不好用,因为1) 特别耗显存和FLOPs; 2)没有利用好small cross-image variance这回事儿。

贡献
- rethinking了一下传统卷积里面由于没有利用好两个方差这个特性,存在的无用功部分;
- 提了个TVConv,建立在1的假设之上;
- 做了拓展实验,2提的TVConv在人脸识别很牛,上到医学图像任务上居然更他妈的牛。
Methodology
针对这个layout-specific tasks,本文提出的Translation Variant Convolution (TVConv)同时利用好了两种方差的特点。简单理解为,对于BxCxHxW的输入,变换矩阵在H, W维度不同,却在B维度上共享——本文认为这是效率最高的方式。
TVConv流程
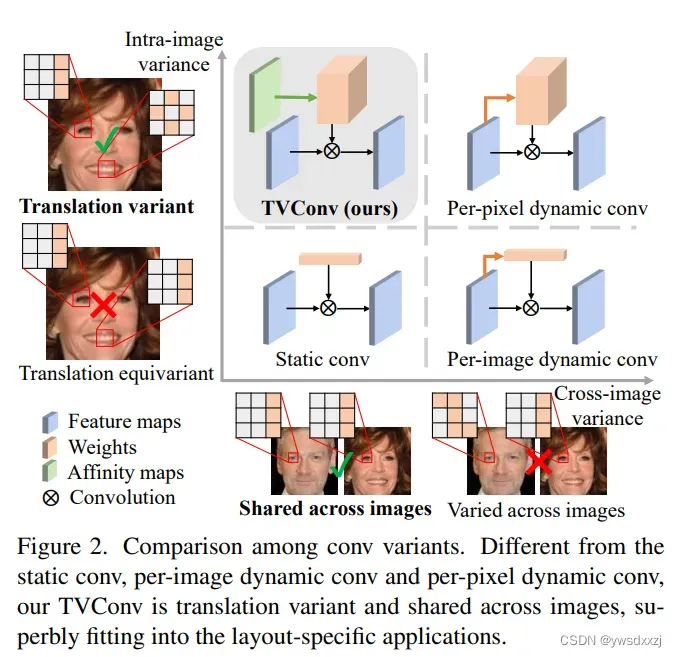

提出了1) Affinity Maps来区分多种不同的局部特征。这个东西隐式地捕捉了不同空间区域的语义特征,这很self-attention很像,却没有生成HWxHW的庞大矩阵;2) 接着,我们把Affinity Maps交给权重生成网络,来产生权重。这个TVConv还有一个好处,就是Affinity Maps也是训练一次就固定,生成的权重也可以生成一次就存下来,以后对所有输入都不改变。
数学表达
每次公式部分读完了就不想写,很奇怪,回头补下。。
结果
形式上,简单地即插即用,直接替换DWConv。
- 对轻量化,这节约了3.1x的复杂度(理论证明),并在不掉点前提下达到2.3x加速;
- 对准确度,(我猜的)小幅增加参数,能够提高4.21%的准确度。
实验分析
四个问题
①TVConv对于数据增强够鲁棒吗?
答:某些甚至加了更好;对大部分,有鲁棒性;加得太多,最差情况退化为普通DW卷积(PS:这其实是很符合理论的结论啊!)。
②如何初始化Affinity Maps?

答:默认是使用常数maps初始化,即从DWConv开始。理论上,从初始化为所有图片的统计值会更好,然而实验没做出来。作者感觉这是因为深层次的Affinity Maps包含一些高级语义信息了,只通过统计均值方差,很难总结出需要的“高级的共性”。

③过参数化Weight-Generate模块有用吗?
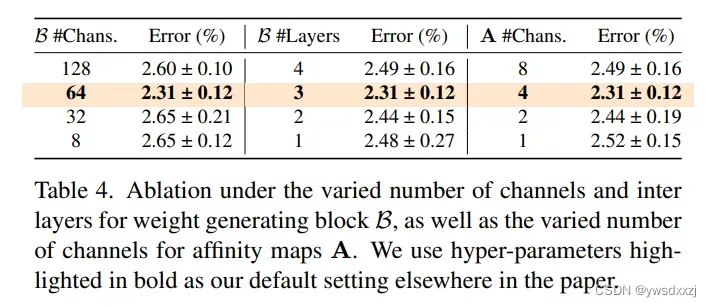
答:真的有用,加宽加深Weight-Generate模块都能提点。但是,搞太大也会饱和。

④既然TVConv可以即插即用,那么插在哪好?

答:替换在网络深层好,替换浅层时效果甚至会变差。

总结
缺点
因为Affinity Maps是ca, H, W,导致必须确定H, W,也就不能适应动态分辨率。
未完待续
文章出处登录后可见!