

目录
(加载数据+backbone选择+优化器选择+loss+结果回传+结果保存)
1.加载数据
修改位置:mmsegmentation-master/configs/_base_/datasets
以自己的数据为例:建立my_dataset.py
# dataset settings
dataset_type = 'MyDataset'
data_root = './process_ok/mmsegment_label/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (640, 480)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(640, 480), keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
#dict(type='PhotoMetricDistortion', hue_delta=0), #四个参数(参考博客)分别是亮度、对比度、饱和度和色调
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(640, 480),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir=['525/images/train'],
ann_dir=['525/seg_labels/train'],
pipeline=train_pipeline,
split="splits/train.txt"),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir=['525/images/val'],
ann_dir=['525/seg_labels/val'],
split="splits/val.txt",
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir=['525/images/val'],
ann_dir=['525/seg_labels/val'],
split="splits/val.txt",
pipeline=test_pipeline))
splits/train.txt 和splits/val.txt生成使用代码:
'''
生成mmsegment训练使用的split
'''
import mmcv
import os.path as osp
if __name__ == '__main__':
data_root = "./mmsegmentation-master/"
ann_dir = "./mmsegmentation_label/525/seg_labels/train"
split_dir = './mmsegmentation_label/splits'
mmcv.mkdir_or_exist(osp.join(data_root, split_dir))
filename_list = [osp.splitext(filename)[0] for filename in mmcv.scandir(
osp.join('', ann_dir), suffix='.png')]
with open(osp.join(data_root, split_dir, 'train.txt'), 'w') as f:
# select first 4/5 as train set
train_length = int(len(filename_list)*4/5)
f.writelines(line + '\n' for line in filename_list[:train_length])
with open(osp.join(data_root, split_dir, 'val.txt'), 'w') as f:
# select last 1/5 as train set
f.writelines(line + '\n' for line in filename_list[train_length:])在mmsegmentation-master/mmseg/datasets中加入my_dataset.py
# Copyright (c) OpenMMLab. All rights reserved.
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class MyDataset(CustomDataset):
"""PascalContext dataset.
In segmentation map annotation for PascalContext, 0 stands for background,
which is included in 60 categories. ``reduce_zero_label`` is fixed to
False. The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
fixed to '.png'.
Args:
split (str): Split txt file for PascalContext.
"""
CLASSES = ('knife', 'lighter')
PALETTE = [[0, 200, 0], [0, 0, 200]]
def __init__(self, split, **kwargs):
super(MyDataset, self).__init__(
img_suffix='.jpg',
seg_map_suffix='.png',
split=split,
reduce_zero_label=True,
**kwargs)
assert self.file_client.exists(self.img_dir) and self.split is not None
在 mmsegmentation-master/mmseg/datasets/__init__.py中加入
from .my_dataset import MyDataset在__all__ 的list中加入:’MyDataset’
2.backbone选择
1)预训练模型的下载
以segformer为例;
进入mmsegmentation-master/configs/segformer/segformer.yml中有各种预训练模型下载的网址链接;
2)设置最大训练epoch数,以及多少个epoch训练一次
可进入/mmsegmentation-master/configs/_base_/schedules中的采用的文件中,以schedule_20k.py为例;
原始:
runner = dict(type='IterBasedRunner', max_iters=20000)
checkpoint_config = dict(by_epoch=False, interval=2000)
evaluation = dict(interval=2000, metric='mIoU', pre_eval=True)修改为:
runner = dict(type='EpochBasedRunner', max_epochs=200)
checkpoint_config = dict(by_epoch=True, interval=10)
evaluation = dict(by_epoch=True, interval=5, metric='mIoU', pre_eval=True)3)预训练模型的加载
以segformer为例,加载预训练模型的位置在mmsegmentation-master/mmseg/models/backbones/mit.py
def init_weights(self):
if self.init_cfg is None:#无预训练模型
for m in self.modules():
if isinstance(m, nn.Linear):
trunc_normal_init(m, std=.02, bias=0.)
elif isinstance(m, nn.LayerNorm):
constant_init(m, val=1.0, bias=0.)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[
1] * m.out_channels
fan_out //= m.groups
normal_init(
m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
else:
super(MixVisionTransformer, self).init_weights()#有预训练模型3.优化器选择
4.训练
1)单卡训练
python tools/train.py ./configs/segformer/total_config1.py --work-dir ./runs --gpu-id 0 0单卡训练时,将train中config改为了 –config,这也导致了后面采用多卡时,参数无法识别;后面就改回去了;
2)多卡训练
bash tools/dist_train.sh configs/segformer/total_config1.py 2 --work-dir ./runs参数1(configs/segformer/total_config1.py)和参数2(2)分别对应dist_train.sh中的CONFIG=$1和GPUS=$2;


插图来源于:蒸馏模型更换backbone(错误合集)_PHL__的博客-CSDN博客
4.loss+结果回传
5.结果
x光机数据效果:
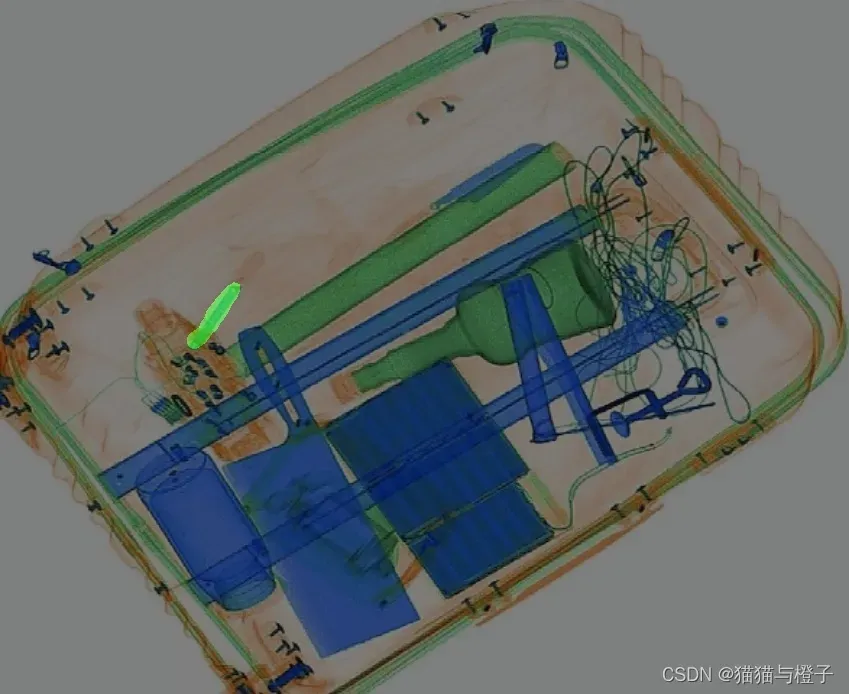

注:绿色的地方是一把美工刀,/(ㄒoㄒ)/~~
报错
1)type object ‘FileClient’ has no attribute ‘infer_client’
self.file_client = mmcv.FileClient.infer_client(self.file_client_args)
AttributeError: type object 'FileClient' has no attribute 'infer_client'报错原因:安装的mmcv-full与mmsegment版本不匹配
解决方案:参考以下网址安装匹配的版本;
mmsegmentation/get_started.md at master · open-mmlab/mmsegmentation · GitHub
2)It is expected output_size equals to 2, but got size 3
File "/home/ray/anaconda3/envs/mmsegmentation/lib/python3.7/site-packages/torch/nn/functional.py", line 3163, in interpolate
return torch._C._nn.upsample_bilinear2d(input, output_size, align_corners, sfl[0], sfl[1])
RuntimeError: It is expected output_size equals to 2, but got size 3报错原因:分割标签不正确
解决方法:本人数据标签是yolov5格式的标签标签类别+归一化的多坐标点(label x1 y1 x2 y2 x3 y3 x4 y4 … …)
img = cv2.imread(img_path)
h, w = img.shape[:2]
size = (h, w) # ( annotation.imgWidth , annotation.imgHeight )
# labelImg = Image.new("L", size, 0)
labelImg = np.zeros(size, np.uint8)
labelImg[:, :] = 0
# drawer = ImageDraw.Draw(labelImg)
lines = open(txt_path, 'r', encoding='utf-8').readlines()
save_label = False
result_list = []
for line in lines:
dict_result = {}
# print(line, img[:-4]+'.txt')
# point = list(map(int, line.strip().split(' ')))
label = line.strip().split(' ')[0]
label_name = dict_label[label]
dict_result["category"] = label_name
points = list(map(float, line.strip().split(' ')[1:])) # 读取中点,w,h
widths = [x * w for x in points[::2]]
heights = [y * h for y in points[1::2]]
polygon = []
for i_ in range(len(widths)):
ptStart = [widths[i_], heights[i_]]
polygon.append(ptStart)
points = np.array(polygon, dtype=np.int32)
if label == '0':
# drawer.polygon(polygon, fill=100)
# labelImg[:, :, 1] = 2
cv2.fillPoly(labelImg, [points], color=(1))#color=(0, 200, 0))
elif label == '1':
# drawer.polygon(polygon, fill=200)
# labelImg[:, :, 2] = 2
cv2.fillPoly(labelImg, [points], color=(2))#color=(0, 0, 200))
else:
print('label is error:', label)参考:https://github.com/open-mmlab/mmsegmentation/issues/550
https://github.com/open-mmlab/mmsegmentation/issues/626
https://github.com/open-mmlab/mmsegmentation/issues/626
在docs/zh_cn/tutorials中也有说明:
注意:标注是跟图像同样的形状 (H, W),其中的像素值的范围是 `[0, num_classes – 1]`。
您也可以使用 [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) 的 `’P’` 模式去创建包含颜色的标注。
3)训练测试结果报NAN
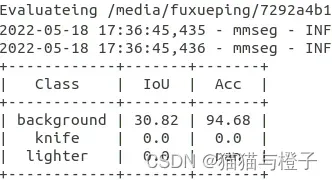

解决办法:reduce_zero_label=False,
4)KeyError: ‘MyDataset is not in the dataset registry’
如果你已经安装官方要求进行了数据层的修改(https://github.com/MengzhangLI/mmsegmentation/blob/add_doc_customization_dataset/docs/en/tutorials/customize_datasets.md#how-to-prepare-your-own-dataset)还是报数据层没有注册,那么可以按照一下方式解决;
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 44, in build_from_cfg
raise KeyError(
KeyError: 'MyDataset is not in the dataset registry'解决办法:进入工程,对工程进行本地安装
# pwd
/home/jovyan/XXX/semantic_segment/mmsegmentation-master
# pip install -e .在get_started.md中也有相关的说明:
Here is a full script for setting up mmsegmentation with conda and link the dataset path (supposing that your dataset path is $DATA_ROOT).
“`shell
conda create -n open-mmlab python=3.10 -y
conda activate open-mmlabconda install pytorch=1.11.0 torchvision cudatoolkit=11.3 -c pytorch
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
git clone https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
pip install -e . # or “python setup.py develop”
5)预训练模型和加载的网络结构层名有差异,unexpected key in source state_dict:
报错:
unexpected key in source state_dict: …(在此省略报错的层名)
missing keys in source state_dict:…(在此省略报错的层名)
使用bycompare对比层名,发现问题:
My pretrained model key vales | backbone model parameters backbone.layers.0.ln1.weight -> backbone.layers.0.ln1.weight backbone.layers.0.ln1.bias -> backbone.layers.0.ln1.bias backbone.layers.0.attn.qkv.weight -> backbone.layers.0.attn.attn.in_proj_weight -----> different backbone.layers.0.attn.qkv.bias -> backbone.layers.0.attn.attn.in_proj_bias -----> different backbone.layers.0.attn.proj.weight -> backbone.layers.0.attn.attn.out_proj.weight -----> different backbone.layers.0.attn.proj.bias -> backbone.layers.0.attn.attn.out_proj.bias -----> different
解决方法:将预训练模型的层名修改一下,重新存储后在加载:
import torch
from collections import OrderedDict
new_state_dict = OrderedDict()
state_dict = torch.load('./segformer_mit-b0_512x512_160k_ade20k_20210726_101530-8ffa8fda.pth')
for k, v in state_dict['state_dict'].items():
k = k.replace('backbone.', '') # remove prefix backbone.
new_state_dict[k] = v
result_dict = {}
result_dict['meta'] = state_dict['meta']
result_dict['state_dict'] = new_state_dict
orch.save(new_state_dict, './segformer_mit-b0_512x512_160k_ade20k_20210726_101530-8ffa8fda_nobackbone.pth')可参考:https://github.com/open-mmlab/mmsegmentation/issues/1473
6)使用多卡训练时报错:tools/dist_train.sh:Bad substitutation
将sh dist_train.sh 改为 bash dist_train.sh;
参考:https://blog.csdn.net/weixin_41529093/article/details/118386064
7)results[‘ann_info’][‘seg_map’]) KeyError: ‘ann_info
Traceback (most recent call last):
File "tools/train.py", line 243, in <module>
main()
File "tools/train.py", line 232, in main
train_segmentor(
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/apis/train.py", line 191, in train_segmentor
runner.run(data_loaders, cfg.workflow)
File "/opt/conda/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 127, in run
epoch_runner(data_loaders[i], **kwargs)
File "/opt/conda/lib/python3.8/site-packages/mmcv/runner/epoch_based_runner.py", line 54, in train
self.call_hook('after_train_epoch')
File "/opt/conda/lib/python3.8/site-packages/mmcv/runner/base_runner.py", line 309, in call_hook
getattr(hook, fn_name)(self)
File "/opt/conda/lib/python3.8/site-packages/mmcv/runner/hooks/evaluation.py", line 267, in after_train_epoch
self._do_evaluate(runner)
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/core/evaluation/eval_hooks.py", line 113, in _do_evaluate
results = multi_gpu_test(
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/apis/test.py", line 206, in multi_gpu_test
for batch_indices, data in zip(loader_indices, data_loader):
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1085, in _next_data
return self._process_data(data)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1111, in _process_data
data.reraise()
File "/opt/conda/lib/python3.8/site-packages/torch/_utils.py", line 428, in reraise
raise self.exc_type(msg)
KeyError: Caught KeyError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 198, in _worker_loop
data = fetcher.fetch(index)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataset.py", line 218, in __getitem__
return self.datasets[dataset_idx][sample_idx]
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/datasets/custom.py", line 214, in __getitem__
return self.prepare_test_img(idx)
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/datasets/custom.py", line 249, in prepare_test_img
return self.pipeline(results)
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/datasets/pipelines/compose.py", line 41, in __call__
data = t(data)
File "/home/jovyan/XXX/semantic_segment/mmsegmentation-master/mmseg/datasets/pipelines/loading.py", line 131, in __call__
results['ann_info']['seg_map'])
KeyError: 'ann_info'报错原因:
dataset_2009_test = dict(
type=dataset_type,
data_root=data_root,
img_dir=[‘2009/images/train’],
ann_dir=[‘2009/seg_labels/train’],
pipeline=test_pipeline,
split=”splits/2009_train.txt”
)
中的pipeline=test_pipeline,写成了’pipeline=train_pipeline,’,改过来就可以了;
参考:
文章出处登录后可见!