沐神论文精度:https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=pageDriver
Paper:https://arxiv.org/pdf/1706.03762.pdf
Transformer开创了继MLP、CNN和RNN之后的第四大类模型
摘要
sequence transduction:序列转录,序列到序列的生成
结论
这篇文章介绍了transform模型,第一个仅仅使用注意力的序列模型。用multi-headed self-attention替换常用在encoder-decoder的结构循环层recurrent layers
导言
1、RNN特点:从左往右一步一步计算,对第t个状态ht,由ht-1(历史信息)和当前词t计算。
存在的问题:
(1)难以并行
(2)过早的历史信息可能被丢弃。时序信息是一步一步往后传递的
(3)一个大的ht存历史信息,每一个计算步都需要存储,内存开销大
2、这篇文章提出的transformer不再使用之前大家使用的循环神经层,而是纯基于注意力机制,并行度比较高,能够在较短的时间之内做到比之前更好的效果。
相关工作
用卷积神经网络对于较长的序列难以建模
(1)卷积做计算的时候每次是看一个比较小的窗口,如果两个像素相隔较远需要很多层卷积堆叠起来,才能够把两个隔得比较远的像素融合起来。
(2)卷积的好处是可以有多个输出通道,一个输出通道可以认为是识别不一样的模式。本篇文章提出了一个multi-headed attention多头注意力机制,用于模拟卷积神经网络多输出通道的一个效果。
自注意力机制
memory networks
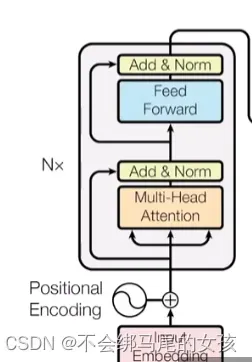
模型
序列模型比较好的是编码器和解码器的架构
编码器:将(x1,x2,…,xn)原始输入映射成(z1,z2,…,zn)机器学习可以理解的向量。
解码器:拿到encoder的输出,会生成一个长为m的序列(y1,y2,y3…,ym)。
encoder和decoder的区别:
- encoder一次性很可能会看全整个句子
- decoder在解码时是一个个的生成,自回归auto-regressive的模型,过去时刻的输出会作为当前时刻的输入
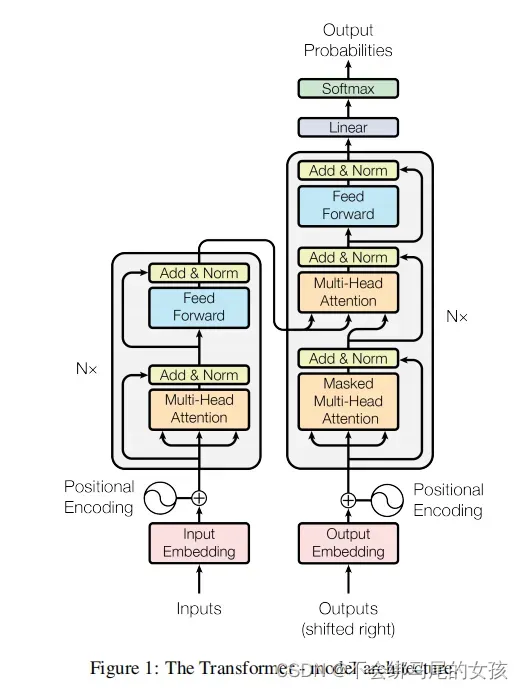
- inputs:中文句子
- outputs:decoder在做预测的时候是没有输入的。
- shifted right指的是decoder在之前时刻的一些输出作为此时的输入,一个个往右
移。 - input embedding:嵌入层,进来的是一个个的词需要将它们表示成向量。
- transformer block
1 multi-Head attention
2 feed forward前馈神经网络
3 add&norm:add表示残差的连接
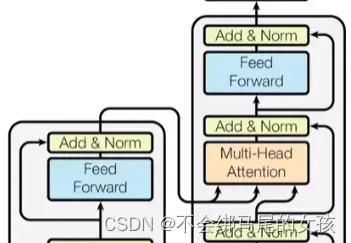
- 编码器
编码器是用一个n=6的层layers,每一个layer用两个sub-layer 第一个sub-layer:multi-headed
self-attention 第二个sub-layer:simple position-wise fully connected
feed-forward network,也就是一个MLP 对于每一个子层采用了一个残差连接,最后再使用layer
normalization—-LayerNorm(x+sublayer(x))
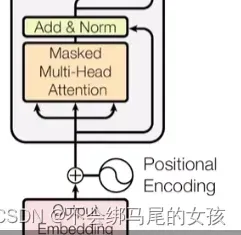
- 解码器
解码器和编码器一样都是n=6个同样的层构成的,不同之处在于有一个第三个子层。因为解码器做的是自回归,在预测t时刻的输出时不可以看到t之后时刻的输入。通过一个带掩码的注意力机制保证输入进来的时候,在t时刻不可以看到t时间以后的那些输入。
- 注意力层
- 注意力
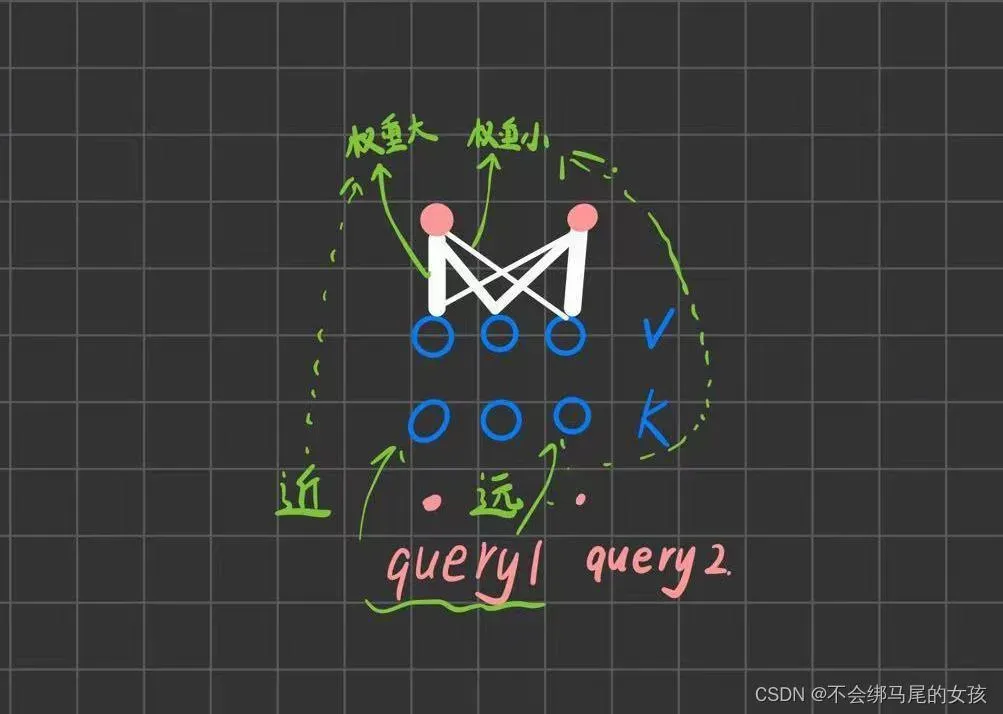
注意力:注意力函数是将query和一些key-value对映射成输出的函数
· 里面所有的query、key-value、输出都是向量
· 输出是value的加权和,所以输出的维度和value的维度是一样的
· 对于每一个value的权重,他是value对应的key和query的相似度(compatibility function,不同的注意力机制有不同的算法,不同的相似度函数导致不一样的注意力的版本)计算得来
key和value并没有变,但是因为query变化从而权重有变化,导致输出也会有不一样。
- scaled dot-product attention
scaled dot-product attentiontransformer中使用的注意力机制
query和key是等长的,都为dk。value的长度为dv。
计算:对于每一个query和key做内积将其作为相似度(如果内积的值越大就表示两个向量的相似度就越高)
softmax得到n个非负的和为1的权重,再将这些权重作用到value上就可以得到输出。
加性注意力机制&点积注意力机制
加性注意力机制additive attention可以处理query和key不等长的情况。
本文所用的scaled dot-product attention相比于点积注意力机制dot-product(实现起来比较简单效果较好)多除以一个根号dk(也就是scaled)
这里为什么要多除以根号dk呢
当dk比较大的时候,也就是两个向量长度比较长的时候,做点积的时候值可能比较大也可能比较小
当值比较大的时候,向量之间相对的差距就会变大,就导致值最大的那个值进行softmax操作后就会更接近1,剩下的值就会更靠近于0,值就会向两极分化,当出现这种情况后,在算梯度的时候,梯度会比较小(softmax最后的结果是所希望的预测值置信的地方尽量靠近1,不置信的地方尽量靠近0,这样就差不多收敛了,梯度就会变得比较小,就会跑不动)
在transformer里面一般用的dk比较大(512),所以除以根号dk是一个不错的选择
在这里mask主要是为了避免在t时刻看到以后时间的东西。对于qt和kt之后的用于计算的那些值替换为较大的负值,它们在经过softmax后会变成0
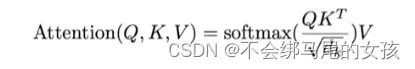
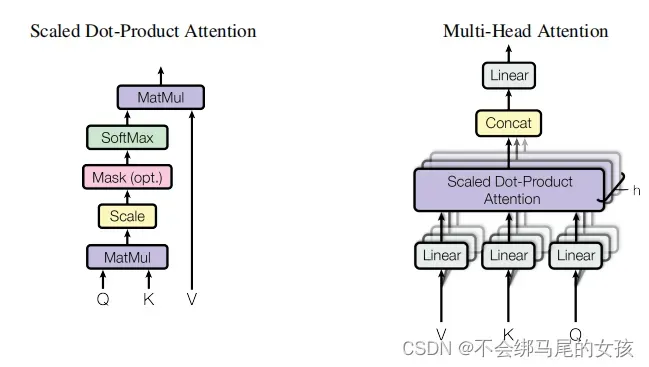
- Multi-Head Attention
整个的query,key和value投影(linear)到一个低维,投影h次;然后做h次scaled dot-product attention,得到h个输出,将这些输出变量concat,最后做一次线性的投影得到最终的输出。
为什么用多头注意力机制呢
- dot-product注意力没有可以学习到的参数,主要就是进行内积,有时候为了识别不一样的模式而有不同的算法。
- 加性attention里面是有一个权重是可以学到的
- 本文multi-head attention先投影到低维,这个投影的w是可以学习到的,也就是有h次学习到不一样投影的方法,使得在投影进去的度量空间中能够匹配不同模式所需要的相似函数,然后最后把所得到的东西再做一次投影。
- Transformer中注意力机制的实现
第一个注意力层:
multi-head attention的三个输入为key,value,query(这三个相同,也就是一根线复制成三份,叫做自注意力机制),输入和输出的大小相同。假如不考虑多头和有投影的情况,相当于是value的加权和,权重来自key和query。如果有多头的话,经过投影会学习到h个不一样的距离空间出来,使得的出来的东西会有些不同。第二个注意力层:
和第一个也是一样的,唯一的不一样在于mask
第三个注意力层:
它不再是自注意力了,其中key和value来自编码器,query来自解码器下一个attention的输入
attention:query注意到当前的query感兴趣的东西,对当前的query不感兴趣的内容可以忽略掉。在encoder和decoder之间传递信息。
- Position-wise Feed-Forward Networks
其实就是一个full connected feed-forward network也就是一个MLP,但是不同之处在于它是把同一个MLP对每个词作用一次即position-wise,就是MLP只是作用在最后一个维度。(batch,sequence,feature)
position:输入序列中很多个词,每个词就是一个position
在注意力层的输入(每一个query对应的输出)的长为512,x就是一个512的向量,W1会把512投影成2048(等价于将他的维度扩大了4倍),以为最有有残差连接,所以还需要投影回去,所以W2又把2048投影回512
这其实就是一个单隐藏层的MLP,中间的隐藏层将输入扩大4倍,最后输出的时候又回到输入的大小(如果用pytorch来实现的话其实就是把两个线性层放在一起,而不需要改任何参数,因为pytorch在输入是3d的时候,默认就是在最后一个维度做计算)
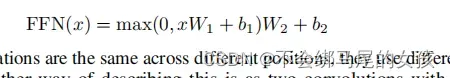
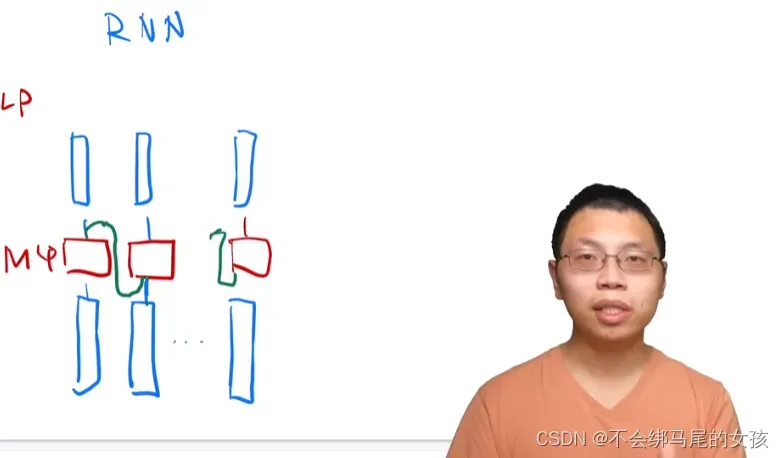
- Transformer如何抽取序列信息?并将其加工成最后所想要的语义空间向量?
首先考虑一个最简单的情况(没有残差连接、attention也是单头、没有投影),如下图所示
在整个过程中attention所起到的作用就是把整个序列信息抓取出来做一次汇聚aggregation。所以在MLP成为更想要的语义空间的时候,因为加权attention之后的每个输出已经包含了序列信息,每个MLP只要在每个点独立进行运算就可以。
RNN的输入也是向量,对于第一个点也是做一个线性层
对于下一个点,如何利用序列信息,还是用之前的MLP(权重跟之前是一样的),但是时序信息(下图中绿色曲线表示之前的信息,蓝色曲线表示当前的信息)方面,是将上一个时刻的输出放回来作为输入的一部分与第二个点一起作为输入,这样就完成了信息的传递
RNN&Transformer
都是用一个线形层或者MLP来进行语义空间的转换,但是不同之处在于传递序列信息的方式。RNN是只把上一时刻信息的输出作为输入。而transformer是用通过attention获得全局信息,然后再用MLP做语义转换。

- embeding
embeding
因为输入是一个一个的词(或者叫词源,token),需要将其映射成向量。embeding的作用就是给任何一个词,学习一个长为d的向量来表示它(本文中d等于512)
编码器的输入需要embeding
解码器的输入也需要embeding
在softmax前面的线性也需要embeding
本文中这3个embeding是一样的权重,这样子训练起来会简单一点
另外还将权重乘了根号d:因为embedding会把一个向量的L2 Norm学成比较小的值,维度一大的话,权重值就会变小。但是之后要加上positional encoding,他不会随着长度变长把他的Norm固定住,因此乘上了根号d之后,使得他们在scale差不多。也就是说让embedding的权重大一些,不至于被positional encoding学到的权重掩盖。
- positional encoding
attention不会有时序信息,输出是value的加权和,权重是query和key之间的距离,和序列信息无关
RNN是如何添加时序信息的?RNN将上一个时刻的输出作为下一个时刻的输入来传递历史信息
attention是在输入里面加入时序信息,将输入词所在的位置信息加入到输入里面(positional encoding)
词在嵌入层会表示成一个长为d的向量,同样用一个长为d的向量来表示数字,也就是词的位置,这些数字的不同计算方法是用周期不一样的sin和cos函数的值来算出来的,所以说任何一个值可以用长为d的向量来表示,然后这个长为d的记录了时序信息的向量和嵌入层相加,就完成了将时序信息加进数据中的操作。
- Layernorm & batchnorm
对于一个二维输入矩阵,每一行是一个样本,每一列是一个特征
Batchnorm:每一次将每一列特征在它的一个小的mini-batch里面的均值变成零,方差变成1
把这个向量本身的均值减掉,然后再除以他的方差就可以了
1. 在计算均值的时候,是在每个小批量里面(一条向量里面算出他的均值和方差)
2. 在训练的时候可以做小批量,在预测的时候会把全局的均值算出来
3. 在预测的时候会把全局的均值算出来,整个数据扫一遍之后,在所有数据上平均的均值方差存起来,在预测的时候再使用
4. batchnorm还会学lambda和beta出来:可以把向量通过学习放成任意某个值,均值为任意某个值
layernorm:对每个样本做normalization
在transformer或者RNN中,输入是一个三维的一个序列的样本,(batch,sequence[n]代表一个句子,feature[d]每个词的向量每个单词被编码为相同的词向量)
BatchNorm:每次取一个feature,也就是对应的(batch,sequence[n])取出来,然后将其的均值变为0方差变为1,也就是相当于切一块下来然后拉成一个向量,然后再进行运算。
LayerNorm:每次取一个batch,也就是(sequence[n],feature[d])
切法不一样带来不同的效果,为什么layernorm用的多一点呢?
因为在时序序列模型中,batch中每个句子长度不一定都相同,造成(batch,sequence[n])不是一个二维矩阵,数据部分会类似成为阶梯形。
Batch Norm:为了使得(batch,sequence[n])成为二维矩阵,没有的地方一般用0来填充。
1 如果样本长度变化比较大的时候,每次做小批量的时候,算出来的均值和方差的抖动相对来说是比较大的。
2 另外,在做预测的时候要把全局的均值和方差记录下来,这个全局的均值和方差如果碰到一个新的预测样本,如果碰到一个特别长的,因为在训练的时候没有见过这种长度的,那么在之前计算的均值和方差可能就不那么好用了。
而对于Layernorm,它是按照每个样本进行均值和方差的计算,也不需要存下一个全局的均值和方差,这样的话相对来讲更稳定一些。
实验
正则化
residual
dropout:对每一个子层(包括多头的注意力层和之后的MLP),在每个层的输出上,在进入残差连接之前和进入到layernorm之前,使用dropout(dropout率为0.1,也就是把输出的10%的那些元素值乘0.1,剩下的值乘1.1)。另外在输入加上词嵌入再加上position
encoding的时候,也用了一个dropout。也就是说,基本上对于每一个带权重的层,在输出上都使用了dropout,虽然dropout率不是特别高,但是使用了大量的dropout层来对模型做正则化
label smoothing(inception v3)
使用softmax去学东西的时候,正确的标号是1,错误的标号是0,对于正确的label的softmax值,让他去逼近于1,但是softmax的值是很难去逼近于1的,因为他里面是指数,比较soft(需要输出接近无限大的时候,才能逼近于1),这样使得训练比较困难。
一般的做法是不要搞成特别难的0和1,可以把1的值往下降一点,比如降成0.9,本文中是直接降成了0.1,就是说对于正确的那个词,只需要softmax的输出(置信度)到0.1就可以了,而不需要特别高,剩下的值就可以是0.9除以字典大小,这里会损失perplexity(log
lost做指数),基本上可以认为是模型的不确信度(正确答案只要10%是对的就行了,不确信度会增加,所以这个值会变高),但是在模型不那么确信的情况下会提升精度和BLUE的分数(这两个才是真正所要关心的点)
文章出处登录后可见!