ABSTRACT
以往的字体生成工作主要集中在标准打印字体上,即字符形状稳定、笔划清晰。毛笔手写字体的生成研究很少,涉及整体结构的变化和复杂笔画的转换。为了解决这一问题,我们提出了一种新的基于gan的图像平移模型,该模型集成了骨架信息。我们首先从训练图像中提取骨架,然后设计图像编码器和骨架编码器来提取相应的特征。设计了一个自我注意的精细注意模块来引导模型学习不同领域之间的区别特征。骨架鉴别器首先使用预先训练的生成器从生成的图像中合成骨架图像,然后判断其与目标图像的真实性。我们还提供了一个具有六种风格和15,000张高分辨率图像的大型笔触手写字体图像数据集。定量和定性实验结果都证明了我们所提出的模型的竞争力。
索引术语-字体生成,生成式对抗网络,画笔手写字体数据集.
1. INTRODUCTION
在几千年的中国书法历史中,出现了许多不同的书写风格。书法风格可以定义为骨架结构和笔触风格。骨架包含了文字的基本信息,如笔画的构成、位置、书写方向等,而笔画风格则意味着骨架的变形,如粗细、形状、书写强度等。直观地说,自动生成毛笔手写字体时,确保结构的正确性和风格的一致性是至关重要的。最近的作品[1-5]将中文字体生成表述为图像样式转换问题,将参考样式中的字符转换为特定的样式。由于手写中文字库的创建费时费力,目前的研究大多集中在标准打印字体生成(SPFG)上,而对毛笔手写字体生成(BHFG)的研究较少。图1所示。SPFG和BHFG说明。图1,BHFG比SPFG更具挑战性。有人观察到,即使是同一个人物,用不同的风格书写的人物形象看起来也很不一样。特别是草书或半草书的文字,其形象严重扭曲。一方面,分离的笔画的基本结构和布局有一些相似之处,使汉字能够被识别。另一方面,在形状上存在很大的几何变化,所以令人印象深刻的风格很容易区分。根据这些观察和分析,我们认为在不同的文体中,文字的骨架是保存文字内容的关键。然而,目前大多数针对SPFG设计的方法都忽略了骨架的重要性。

为了解决上述问题,我们首先收集了一个大型毛笔手写中文字体数据集,该数据集包含六种不同的书法风格和15000多幅高分辨率图像。然后我们针对BHFG提出了一种新的端到端骨架增强生成对抗网络(SEGAN),该网络可以处理不同类型之间的较大几何变化。SE-GAN是单级模型,这意味着生成器可以直接输出具有用户指定输入字符的程式化图像。SE-GAN包括两个编码器,从源图像和相应的骨架图像捕捉特征。为了有效地提取和融合两个源的特征,设计了一种新的自注意精细注意模块(self – Attention Refined Attention Module, SAttRAM),并将其应用于发电机中。为了进一步保证结构的保存,我们还设计了一个额外的骨架鉴别器,使生成的图像的骨架与目标图像的骨架保持接近。广泛的实验进行了六个不同的风格化画笔手写字体生成任务。实验结果表明,本文提出的模型与基线相比具有较强的竞争力。
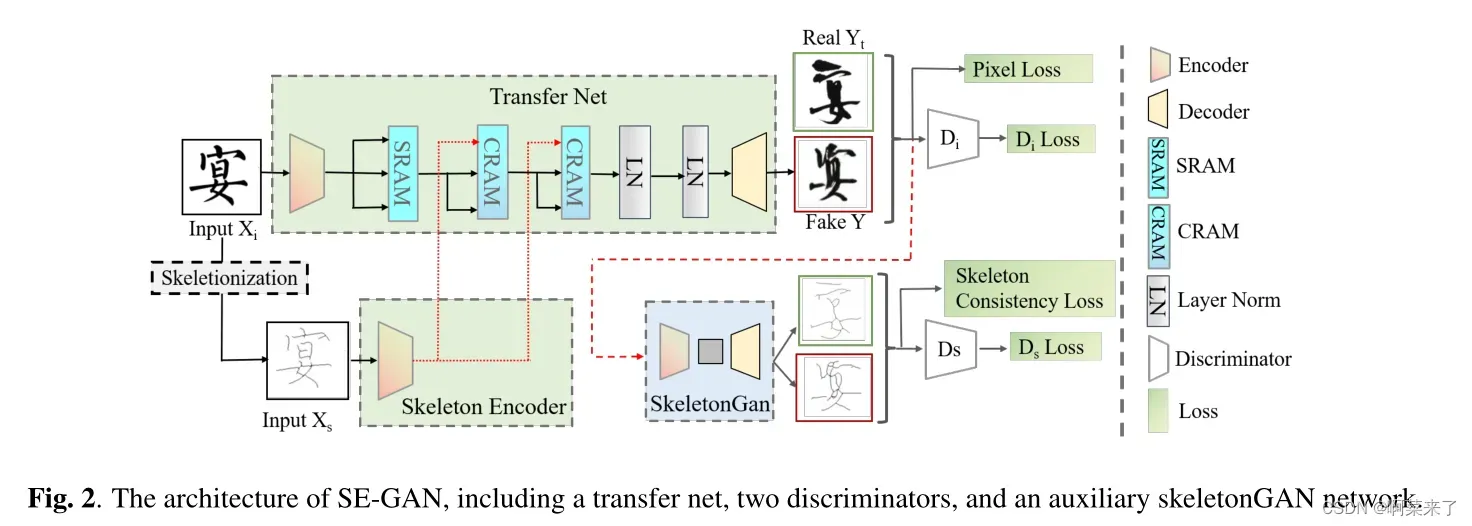
本文的主要工作如下:1)提出了一种新的基于端到端gan的BHFG模型(SE-GAN)。此外,还设计了一种新的自注意精细注意模块(self – Attention Refined Attention Module, SAttRAM),并将其应用于图像发生器中,有效地提取和融合源图像和骨架图像的特征。2)对六种不同风格的汉字字体生成任务进行了广泛的实验。与强基线相比,自动和人工评估都证明了SE-GAN的有效性。3)为便于今后对BHFG的研究,我们还贡献了一个大型字体图像数据集,即将发布。
2. RELATED WORK
Image-to-Image翻译。自生成对抗网络(Generative Adversarial Network, GAN)[6]提出以来,已有许多关于图像到图像翻译的研究成果。Pix2pix[7]是一个基于成对数据监督学习的条件GAN。然后提出了无监督的图像平移模型,如CycleGAN[8],利用循环一致性来提高训练的稳定性。除了一对一域的图像转换,StarGAN[9]引入了一个域分类器或共享的多域嵌入,以单个模型实现多域转换。此外,U-GAT-IT[10]证明了注意模块在图像转换任务中的有效性,它可以引导模型关注不同域之间更重要的区域。但是这些作品都是通过像素到像素的转换,源图像和目标图像的变形很小,不能直接应用于整体变化很大的字体生成任务。
中文字体的一代。以往的作品大多将字符图像的生成表述为图像翻译任务[1,11 – 13]。Zi2zi[1]使用配对数据生成程式化的中文字体。然而,它需要大规模的字体对语料库进行预训练和微调。为了克服数据不足的挑战,[14]应用循环一致性从未配对的数据中生成字体,[11,12]将内容和风格分开作为两个不相关的领域,并从字体图像中学习潜在的风格。最近,[15]利用StarGAN[9]配备了多样性正则器,实现了多风格中文字体的生成。还有一些作品[5,16 – 18]试图将更多的角色领域知识整合到角色生成的多阶段模型中。这些工作大多集中于SPFG,来自源和目标域的图像通常具有非常相似的样式或形状。在本文中,我们主要关注BHFG任务,该任务包含较大的笔画样式差异和布局变化。我们提出用单阶段模型代替多阶段模型,从而使所有模块共同训练,提高了生成过程的效率。
3. APPROACH
3.1. Overall Framework
图2显示了带有两个编码器的框架:图像编码器Ei和骨架编码器Es,它们由四个残差块组成。Ei用于从Xi中提取字符图像特征,包括源域的内容和风格信息,而骨架编码器Es则用于保留Xs的结构特征。为了增强两种不同特征的特征提取和融合,将具有SRAM和CRAM两种变体的新型自注意精细注意模块(SAttRAM)进行顺序叠加,提取骨架增强图像表示。然后,生成器以包含内容和样式信息的精制图像表示作为输入,生成目标样式图像。遵循GANs中的对抗性训练策略,我们使用了两个鉴别器。第一个Di用来区分目标图像和生成的图像。第二个d检测生成的图像骨架与从目标域特征图像中提取的骨架图像是否相干。在骨架提取方面,受[19]启发,我们采用一种简单有效的骨架化算法,对二值化后的字符图像进行迭代腐蚀和膨胀,提取骨架图像。
Self-attentive Refined Attention Module
前人的研究[10,20,21]证明了类激活映射(class activation map, CAM)在图像生成和分类任务中对输入图像重要区域进行定位的有效性。受此启发,CAM可用于在字体生成任务中提取区分风格的注意热点图。为了获得风格鉴别特征M(x),首先将源字体x的解码特征映射F (x)∈RC×W ×H输入到权值为Ω∈RC的全连通(FC)层分类器中进行域分类。然后,CAM通过对所有通道进行线性加权求和,计算出注意热点图:
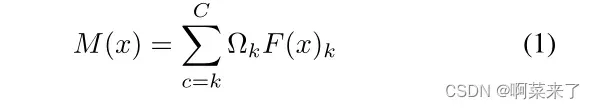
其中M(x)∈RW ×H×C表示空间位置H的注意热点图,W, Ωk表示特征地图中channel k的权值,F (x)k∈RW ×H表示空间位置HW的最后一个卷积层中channel k的特征图。然而,CAM缺乏对空间的关注,通常会导致特征捕获[22]过度激活问题。此外,在CAM模块中集成多模态特征也很困难。为了细化风格判别特征并整合多模态特征,我们提出了一个自注意细化注意模块(SAttRAM),如图3所示。我们将自我注意作为一个有效的模块,通过捕捉空间依赖性来细化像素化的注意热图。因此,细化后的feature map可以定义为:
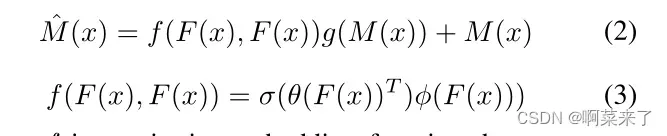
这里f是一个成对的嵌入函数,它计算点积像素亲和力,作为在嵌入空间中通过softmax函数σ归一化的自细化注意权。嵌入函数θ,φ是由个人1×1卷积实现层,在θ(F (x))∈RC1×W H和φ(F (x))∈RC1×W H函数g重塑的输入特性F (x), g (F (x))∈RW H,都是聚合与这种相似性给出的权重函数F (F (x),F (x))∈RC×W h。此自定义注意权值由softmax函数σ归一化,输出ˆM(x)∈RW ×H×C。
为了处理用于图像生成的多模态输入特征,我们在精化注意特征映射的基础上构建了两种不同的注意单元,即自精化注意模块(SRAM)单元和交叉精化注意模块(CRAM)单元。SRAM以一组图像特征xi = Ei(x)作为输入,获取参与特征,因为图像特征是图像平移的基本信息。CRAM捕捉图像特征xi = Ei(xi)与骨架特征xs = Es(xs)之间的模内交互,可以进一步细化从字符图像中提取的特征映射。
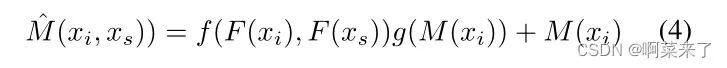
式4中,字符编码特征通过函数g嵌入残差空间,f表示图像特征xi和骨架特征xs之间的像素级特征聚合.
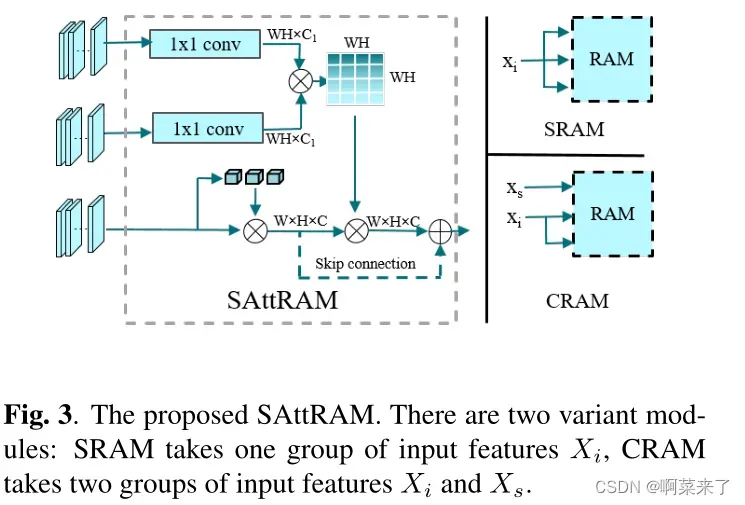
3.3. Discriminators
我们设计了两个鉴别器来学习目标字体样式。按照传统设置,使用第一个鉴别器Di来计算生成的图像与目标域字体图像的相似程度,Di的编码器也利用了前面提到的精细化的注意特征图。在假设生成的字符图像与目标字体图像骨架相似的前提下,我们还设计了一个额外的骨架鉴别器d。考虑到骨架化是一个非微分函数,我们首先应用一个预先训练的骨架生成器(skeletonGAN)从给定的字符图像中生成相应的骨架。然后利用骨架判别器Ds将生成图像的骨架与地面真实图像的骨架进行区分。对于skeletonGAN,我们训练一个简单的CycleGAN模型[8],没有SAttRAM模块,因为骨架化任务似乎比字符生成任务容易得多。借助骨骼鉴别器Ds,模型在训练过程中保留了字符的内容和结构,同时Ds作为SE-GAN的正则化器,防止模型过拟合。
3.4. Loss Design
SE-GAN的损失函数包括含量损失、对抗损失、循环一致性损失和分类损失。内容丢失Lcon包括两部分:像素丢失Lpix,使生成的图像GF (Xi, Xs)与目标图像Yt相似;骨架一致性损失Lsc,确保SG(GF (Xi, Xs))和SG(Yi)之间骨架的一致性。
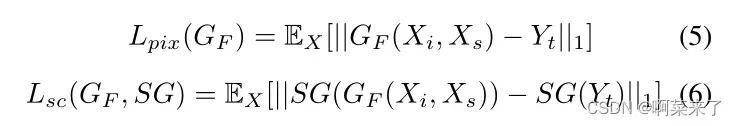
其中SG代表预先训练的骨骼。循环一致性损失Lcycle与[8]中使用的相同,它保证了循环转换能够将图像恢复到原始状态。为了区分图像Xi属于源或目标风格循环,促进细化注意模块中的风格转换,我们在[10]之后使用了一个辅助的loss Lcls。此外,对抗损失Ladv结合了区别损失LDi和骨架级区别损失LDs,这两种损失旨在捕获期望生成的图像Xi的不同属性。
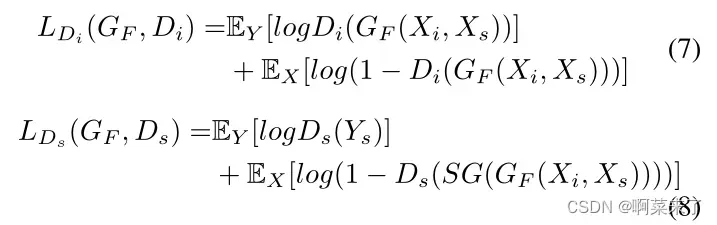
其中Di、Ds分别为像素级鉴别器、骨架鉴别器。最后,我们利用全目标联合训练生成器、鉴别器和分类器,如下所示:
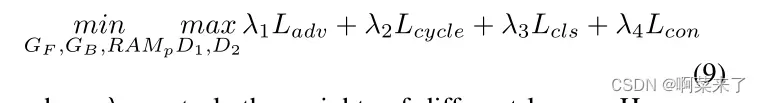
在这里,λi控制不同损失的重量。这里,为了简单起见,我们省略了相应的后向损失函数,因为它们也是以同样的方式定义的。
4. EXPERIMENTS
4.1. Experimental Setup
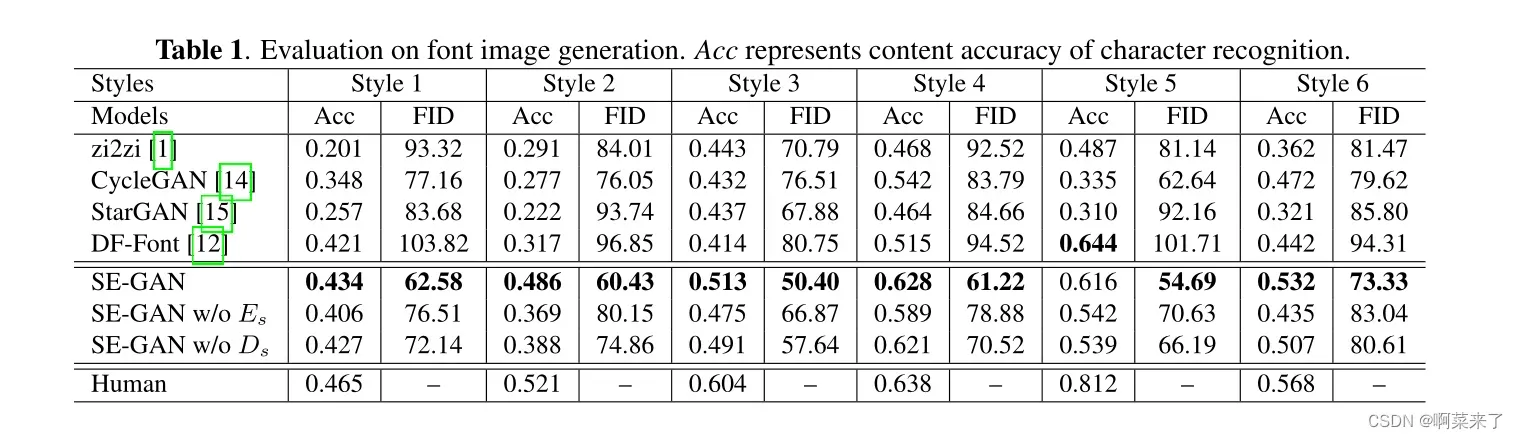
针对公共笔式手写字体生成数据集的不足,我们收集了一个大规模的图像数据集,以六种不同的风格进行实验。各风格的统计为如表1所示。图像总数为15,799,每个子集的大小在1,419到3958之间。在实验过程中,我们将每个子集按8:1:1的比例划分为train/dev/test集合。我们选择标准打印字体Liukai1作为源域,并将这六种风格分别作为目标域。我们采用内容准确性[3]和Fréchet Inception Distance (FID)[23]作为评价指标。作为基线,我们将我们的模型与四种代表性的字体生成模型进行比较,包括zi2zi[1]、CycleGAN[14]、StarGAN[15]和DGFont[12]。

4.2. Experimental Results
**定量分析。**我们计算了所有基线和我们提出的模型在六种字体风格上的Top 1内容准确性(Acc)和FID得分。表1表明,我们提出的模型SE-GAN在几乎所有六种风格中都达到了最好的准确性和最低的FID得分。与zi2zi等监督方法相比,我们的模型仍然可以生成高质量的图像。与性能不稳定的无监督模型CycleGAN和StarGAN相比,SE-GAN仍然具有很强的竞争力和显著的改进。对于DF-Font,我们注意到它倾向于生成与源图像相似的字体图像,但是其独特的风格并没有被很好地学习。虽然DF-Font的内容准确性较高,但FID得分最差。
**定性分析。**我们在图4中展示了所有模型的一些生成示例,作为案例研究。一般来说,SE-GAN的字体图像更容易识别,书法风格也更符合前面提到的原始风格。对于其他基线,生成的字体图像存在明显的缺陷。对于zi2zi来说,风格2和风格6的笔画缺失,风格1和风格5的结构是相互联系的。对于CycleGAN,结构是错误的样式1和样式3的字符很难识别。对于StarGAN来说,在风格2和3中有一些额外的和错误的笔画,这损害了字符的整体外观。以上的例子都说明了骨架信息可以促进字体的生成。


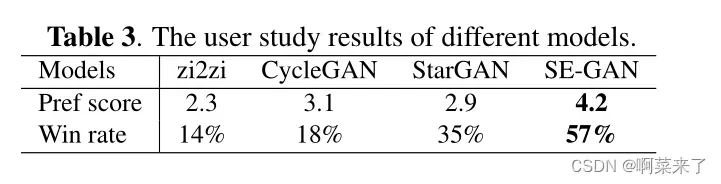
**消融实验.**我们分别去除发生器骨架输入Es和骨架鉴别器Ds来进行烧蚀实验。从表1可以看出,去除Es后,与SE-GAN相比,准确率明显下降,说明骨架信息有助于对字符结构的学习。然而,它在大多数款式上仍优于CycleGAN,证明了SAttRAM的有效性。此外,在所有类型的模型中去掉d也会降低模型的性能,这说明骨架鉴别器的必要性。图5 (a)为不同烧蚀模型的生成图像。由于骨架信息的缺乏,生成的文字中有些笔画不是缺失就是过分夸张。删除d后,一些组件会混合在一起,从而影响生成图像的可读性。图5 (b)对比了CAM、SRAM和CRAM的热点注意图。值得注意的是,与CAM相比,SRAM和CRAM的过度激活较少,激活覆盖范围更全面。此外,通过CRAM学习到的字体形状比SRAM更准确,更接近于ground-truth字体图像,验证了骨架的贡献。用户研究。我们进行了两种用户研究(由于表1中DF-Font的性能较差,我们跳过了对DF-Font的评估)。第一种是对不同模型生成的字体图像进行偏好评分。二是将生成的图像与人工书写的字体图像混合,从中挑选出视觉上更赏心悦目的字体图像。本次评比共邀请了60名具有3年以上书法写作经验的美术专业学生。表3显示,我们的模型从人类专家那里获得了最高的用户偏好得分和胜率。
5. CONCLUSION AND FUTURE WORK
在本文中,我们提出了一个新颖的端到端的毛笔手写字体生成框架SE-GAN。由于该任务涉及整体的结构变化和复杂的笔画传递,我们提出了整合骨架信息的方法来生成字符图像。我们设计了两个编码器,分别提取字符和骨架特征。为了有效地融合来自双方的信息,在发生器中设计了一种新的自我注意模块。此外,我们还采用了骨架鉴别器来保证生成的图像与目标图像的内容一致性。实验表明,我们提出的模型优于几个强基线方法。在未来,我们将探索预先训练的图像平移模型,以促进这项任务。
6. REFERENCES
[1] Y uchen Tian, “Master chinese calligraphy with con-
ditional adversarial networks,” https://github.
com/kaonashi-tyc/zi2zi, 2017.
[2] Danyang Sun, Tongzheng Ren, Chongxuan Li, Hang Su,
and Jun Zhu, “Learning to write stylized chinese charac-
ters by reading a handful of examples,” in Proceedings
of the 27th International Joint Conference on Artificial
Intelligence, 2018.
[3] Bo Chang, Qiong Zhang, Shenyi Pan, and Lili Meng,
“Generating handwritten chinese characters using cycle-
gan,” in 2018 IEEE Winter Conference on Applications
of Computer Vision (WACV). IEEE, 2018.
[4] Y ue Gao, Y uan Guo, Zhouhui Lian, Yingmin Tang, and
Jianguo Xiao, “Artistic glyph image synthesis via one-
stage few-shot learning,” ACM Transactions on Graph-
ics (TOG), vol. 38, no. 6, 2019.
[5] Chuan Wen, Y ujie Pan, Jie Chang, Y a Zhang, Siheng
Chen, Y anfeng Wang, Mei Han, and Qi Tian, “Hand-
written chinese font generation with collaborative stroke
refinement,” in Proceedings of the IEEE/CVF Winter
Conference on Applications of Computer Vision, 2021.
[6] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza,
Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron
Courville, and Y oshua Bengio, “Generative adversar-
ial nets,” in Advances in neural information processing
systems, 2014.
[7] Phillip Isola, Jun-Y an Zhu, Tinghui Zhou, and Alexei A
Efros, “Image-to-image translation with conditional ad-
versarial networks,” in Proceedings of the IEEE confer-
ence on computer vision and pattern recognition, 2017.
[8] Jun-Y an Zhu, Taesung Park, Phillip Isola, and Alexei A
Efros, “Unpaired image-to-image translation using
cycle-consistent adversarial networks,” in Proceedings
of the IEEE international conference on computer vi-
sion, 2017.
[9] Y unjey Choi, Minje Choi, Munyoung Kim, Jung-Woo
Ha, Sunghun Kim, and Jaegul Choo, “Stargan: Uni-
fied generative adversarial networks for multi-domain
image-to-image translation,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, 2018.
[10] Junho Kim, Minjae Kim, Hyeonwoo Kang, and
Kwang Hee Lee, “U-gat-it: Unsupervised generative at-
tentional networks with adaptive layer-instance normal-
ization for image-to-image translation,” in International
Conference on Learning Representations, 2020.
[11] Y exun Zhang, Y a Zhang, and Wenbin Cai, “Separating
style and content for generalized style transfer,” in Pro-
ceedings of the IEEE conference on computer vision and
pattern recognition, 2018, pp. 8447–8455.
[12] Y angchen Xie, Xinyuan Chen, Li Sun, and Y ue Lu, “Dg-
font: Deformable generative networks for unsupervised
font generation,” in Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
2021, pp. 5130–5140.
[13] Shaozu Y uan, Ruixue Liu, Meng Chen, Baoyang Chen,
Zhijie Qiu, and Xiaodong He, “Learning to compose
stylistic calligraphy artwork with emotions,” in Pro-
ceedings of the 29th ACM International Conference on
Multimedia, 2021.
[14] Bo Chang, Qiong Zhang, Shenyi Pan, and Lili Meng,
“Generating handwritten chinese characters using cycle-
gan,” in 2018 IEEE Winter Conference on Applications
of Computer Vision (WACV). IEEE, 2018, pp. 199–207.
[15] Jinshan Zeng, Qi Chen, and Mingwen Wang, “Diversity
regularized stargan for multi-style fonts generation of
chinese characters,” in Journal of Physics: Conference
Series. IOP Publishing, 2021, vol. 1880, p. 012017.
[16] Yiming Gao and Jiangqin Wu, “Gan-based unpaired
chinese character image translation via skeleton trans-
formation and stroke rendering,” in Proceedings of the
AAAI Conference on Artificial Intelligence, 2020.
[17] Y ue Jiang, Zhouhui Lian, Yingmin Tang, and Jianguo
Xiao, “Scfont: Structure-guided chinese font generation
via deep stacked networks,” in Proceedings of the AAAI
Conference on Artificial Intelligence, 2019, vol. 33.
[18] Jinshan Zeng, Qi Chen, Y unxin Liu, Mingwen Wang,
and Y uan Y ao, “Strokegan: Reducing mode collapse
in chinese font generation via stroke encoding,” arXiv
preprint arXiv:2012.08687, 2020.
[19] TY Zhang and Ching Y . Suen, “A fast parallel algorithm
for thinning digital patterns,” Communications of the
ACM, vol. 27, no. 3, pp. 236–239, 1984.
[20] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude
Oliva, and Antonio Torralba, “Learning deep features
for discriminative localization,” in Proceedings of the
IEEE conference on computer vision and pattern recog-
nition, 2016.
[21] Jungbeom Lee, Eunji Kim, Sungmin Lee, Jangho Lee,
and Sungroh Y oon, “Ficklenet: Weakly and semi-
supervised semantic image segmentation using stochas-
tic inference,” in Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
2019.
[22] Aditya Chattopadhay, Anirban Sarkar, Prantik
Howlader, and Vineeth N Balasubramanian, “Grad-
cam++: Generalized gradient-based visual explanations
for deep convolutional networks,” in 2018 IEEE
Winter Conference on Applications of Computer Vision
(WACV). IEEE, 2018.
[23] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,
Bernhard Nessler, and Sepp Hochreiter, “Gans trained
by a two time-scale update rule converge to a local nash
equilibrium,” arXiv preprint arXiv:1706.08500, 2017.
文章出处登录后可见!