背景:最近在学习深度学习中目标检测相关的知识点,看了一些论文,这里挑出YOLO这篇论文,写一篇博客记录一下读后感,供自己回忆,供有需要的人参考~
1、YOLO(目标检测One-Stage中的“典型”)
一、概述:
YOLO(you only look once)是Joseph Redmon等人在2016年CVPR中提出的One-Stage类型的算法,也是继RCNN、faster-RCNN之后,又一里程碑式的目标检测算法。yolo在保持不错的准确度的情况下,解决了当时基于深度学习的检测中的痛点——速度问题。YOLO的论文作者中也可以看到Ross Girshick大神身影,也是RCNN家族的作者,所以YOLO正可谓是强强联合的作品。
Two-Stage: RCNN家族
1)通过专门模块去生成候选框(RPN),寻找前景以及调整边界框(基于anchors)
2)基于之前生成的候选框进一步分类以及调整边界框(基于proposals)
One-Stage: SSD、YOLO
基于anchors直接进行分类以及调整边界框
二、算法流程:

YOLO总体算法步骤可以分为三步:
1、图像尺寸预处理:
首先对输入的图片进行resize操作,使得shape为448 x 448,接着:
1)将一副图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object
2)每个网格要预测B个(一般是2个)bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值,每个网格还要预测C个类别的分数
2、YOLO网络处理:
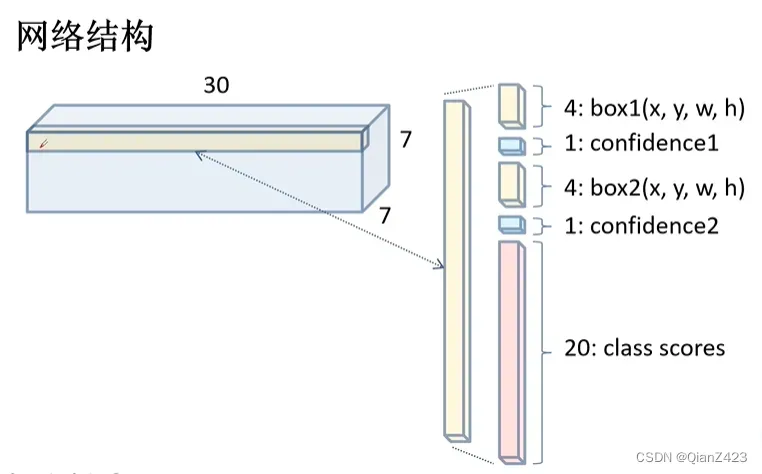
拿到步骤1的输出,作为本步骤的输入,然后YOLO使用了24个卷积层、4个最大池化层,2个全连接层对输入的指定shape的图片进行处理,最后每个bounding box要预测B个(一般是2个)bounding box,每个bounding box (x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。即SxS个网格,每个网格除了要预测B个bounding box外,还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。(注意:class信息是针对每个网格的,即一个网格只预测一组类别而不管里面有多少个bounding box,而confidence信息是针对每个bounding box的。)
例如:在PASCAL VOC中,图像输入为448 x 448,取S = 7, B = 2,一共有20个类别(C = 20),最后输出得到了一个7 x 7 x 30的tensor,其中可以看成是由49个1*1*30的长条(tensor)组成,那么这个长条就对应原图中的一个grid cell对应的结果。
输出:
3、YOLO网络处理:
得到每个box的class-specific confidence score之后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS(非极大值抑制non-maximum suppression)处理,就得到了最终的检测结果。
三、YOLO框架:

四、YOLO读后感:
创新点:
1、One-Stage的典型代表,检测速度快,正可谓是天下武功,唯快不破!
不足之处:
1、对于群体小目标检测效果较差,比如一张图片中有一群飞过天空的小鸟。
2、YOLO容易产生物体的定位错误。
参考博客如下,感谢~
五、损失计算:
损失:bounding box损失、confidence损失、classes损失,计算损失用的都是sum-squared error(误差平方和)
文章出处登录后可见!